AWS Partner Network (APN) Blog
Building a Modern Data Lake with Fivetran and Amazon S3 to Accelerate Data-Driven Success
By Meera Viswanathan, Lead Product Manager – Fivetran
By Brenner Heintz, Lead Technical Product Marketing Manager – Fivetran
By Tamara Astakhova, Sr. Partner Solution Architect – AWS
 |
| Fivetran |
 |
Building a cloud data platform to enable advanced analytics and machine learning (ML) can provide a major competitive advantage. But let’s face it, the journey to data-driven success is not for the faint of heart.
The main challenge that data teams face is to find simple, flexible tools that accelerate downstream data consumers’ access to data so they can find the answers they need on their own.
To accomplish this, many organizations are adopting data lakes to handle large volumes of data, and flexible pipelines to fit the needs of consuming services and teams (machine learning, business intelligence, and analytics). However, traditional data lakes pose challenges in the modern data stack, including:
- Difficulty in discovery: Lack of metadata makes it difficult to uncover the needed data for consuming services.
- Upfront costs for data preparation: Customers must build pipelines to cleanse, de-duplicate, and normalize the data within the data lake.
- Data governance: The lack of standardization of the data, as it lands, adds complexity in building pipelines and retrieving the most up-to-date data in a consistent way. Further, stale records and faulty writes are retained making compliance a nightmare.
In this post, we will discuss the modern data lake and how Fivetran can help accelerate time-to-value with Amazon Simple Service Storage (Amazon S3) and Apache Iceberg.
Fivetran is an AWS Data and Analytics Competency Partner and AWS Marketplace Seller with service specializations in Amazon Redshift, Amazon Relational Database Service (Amazon RDS), and AWS PrivateLink. Fivetran is a fully managed and automated data movement platform in the cloud that enables data teams to automatically ingest and centralize data from hundreds of sources into the data warehouse or data lake with ready-to-analyze schemas.
Fivetran offers pre-built connectors for 300+ data sources and employs extract, transform, load (ETL) to land data in the warehouse or data lake. Analytics teams can then query the data directly using native SQL, or transform it using Fivetran’s native integration with dbt Core.
Centralize Data for Analytics with Fivetran and Amazon S3
One of the most fundamental problems data engineers run into when building a cloud data platform is how to centralize all of their data. You can’t possibly do advanced artificial intelligence (AI) when your data is siloed across multiple databases, customer relationship management (CRM) systems, and other data sources.
To that end, Fivetran offers support for Amazon S3 as a destination, enabling you to land your data in S3 with end-to-end automation, reliability, and security.

Figure 1 – Fivetran data movement platform diagram.
Fivetran allows you to move your data from all your data sources into Amazon S3 in Apache’s Iceberg format, easier than ever before. From there, you can instantly run SQL queries on your data with any compatible compute engine, like Amazon Athena, Amazon Redshift, and others.
Why Land the Data in Apache Iceberg Format?
When Fivetran first looked at adding Amazon S3 as a supported destination, its teams took an opinionated approach. Since their customers would like to avoid using a data lake like a “junk drawer” for all of their data, Fivetran chose to implement S3 as a destination by converting customers’ data into Apache Iceberg format before landing it in S3.
Customers who are looking to build a lake house architecture have increasingly turned to open-source data formats like Apache Iceberg and Delta Lake to organize their data within the data lake. In a lake house architecture, data is ingested into the data lake in its raw form, and then transformed and organized into structured tables, with defined schemas that users can immediately query using standard SQL for data analysis.
These formats also replicate many of the features of traditional cloud data warehouses, including:
- ACID transactions
- Schema evolution
- Time travel
- Data compaction and partitioning
The lake house architecture with Apache Iceberg offers several advantages over traditional data management approaches. It allows organizations to store and process large volumes of data in a cost-effective and scalable way, while also ensuring data consistency and integrity. It provides a flexible and agile data management framework that can adapt to changing business needs.
Data Governance with Amazon S3 and Apache Iceberg
A consistent, compliant data lake provides ready-to-query data for analytics teams, and precious raw data for AI/ML teams. With Apache Iceberg, governance is also a key benefit through features such as:
- Data transparency: Apache Iceberg uses AWS Glue as the underlying data catalog. AWS Glue is populated with metadata as information lands in the data lake, which provides full transparency of the data for any governance requirements.
- Access control: Data can be a sensitive asset for a company and support for row-level-permissions in AWS Lake Formation gives data stewards granular control on data assets.
- Compliance: The “right to be forgotten” is an important GDPR requirement. Records can be found (through the catalog) and deleted with simple SQL commands, making the solution GDPR/CCPA compliant.
Architecture Review
Next, we will compare traditional data pipelines to Fivetran’s automated data movement platform.
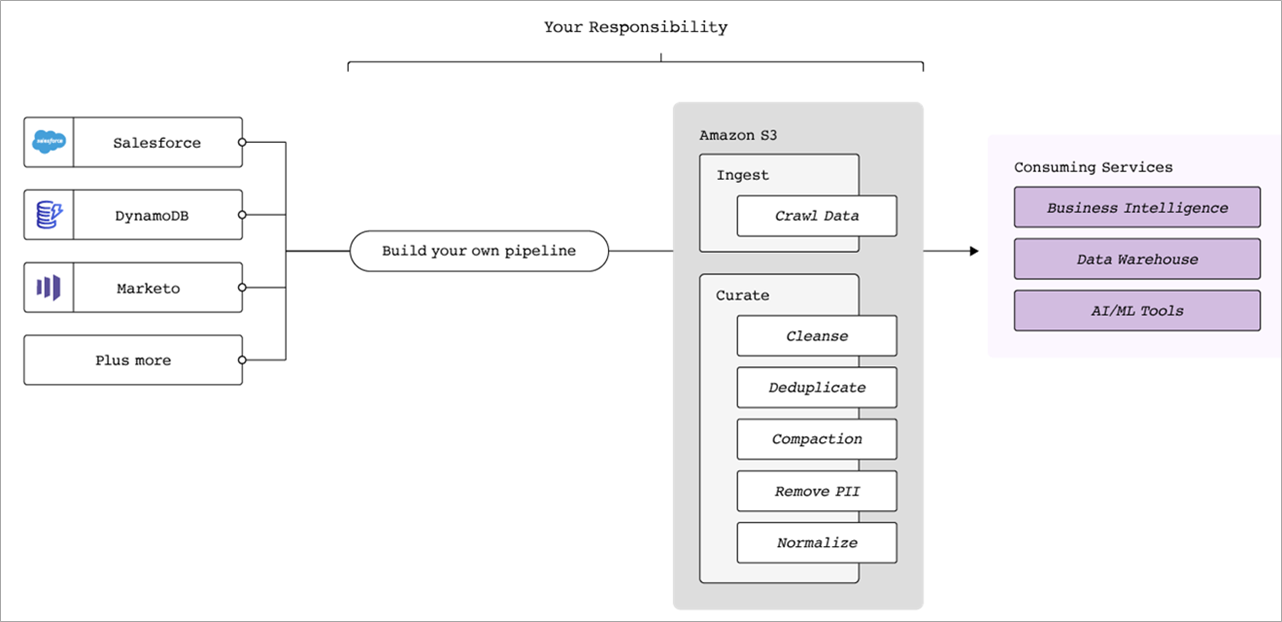
Figure 2 – Traditional data pipeline architecture diagram.
Building a data pipeline can be an incredibly involved process; and maintaining it even more so. Many data engineers have experienced the pain and stress of broken data pipelines, despite their best efforts, in the form of a pager alert waking them up in the middle of the night.
In a typical data pipeline, there are a huge number of operations to perform and services involved, including data cleansing, de-duplication, compaction, anonymization/removal of personally identifiable information (PII), and normalization.
Keep in mind, too, that this is for a single data pipeline. A typical enterprise may have dozens and dozens of data sources, each requiring its own custom data pipeline. Once the pipeline is built, other issues can crop up, such as idempotency/ensuring no duplicate records, change data capture (CDC), upstream API changes, schema evolution, and data pipeline maintenance.
Rather than building this all yourself, Fivetran automates away the risk, complexity, and technical debt.
Amazon S3 and Apache Iceberg – Powered by Fivetran
Fivetran’s support for Amazon S3 as a destination automates away the work required to land your data in the data lake and makes it immediately usable. Choose from over 300+ data connectors, and then Fivetran takes on the work of converting your files to Parquet, cleansing, de-duplicating, and normalizing your data.
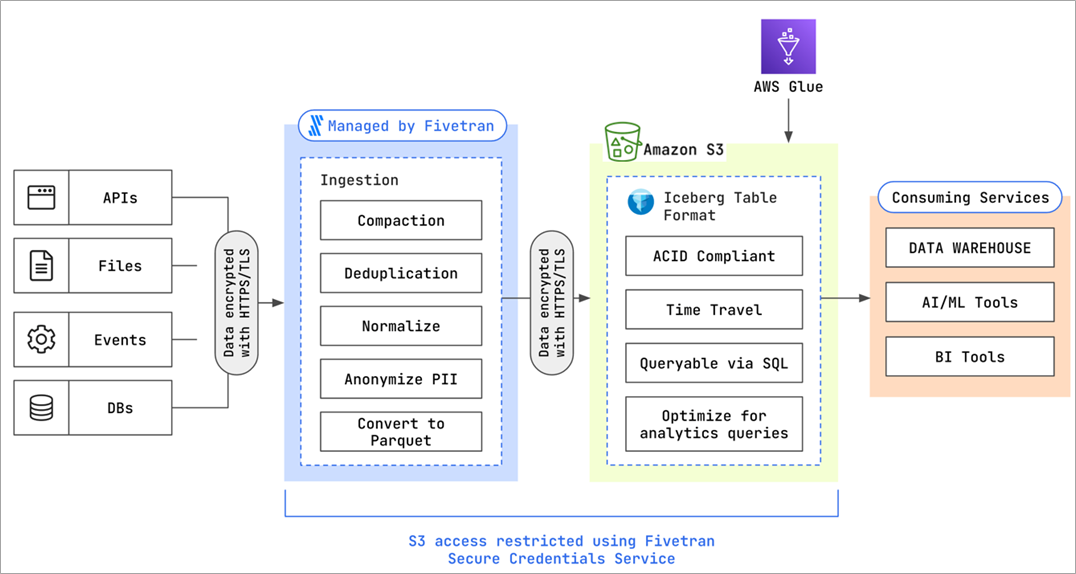
Figure 3 – Data ingestion into Amazon S3 with Fivetran and Apache Iceberg.
Apache Iceberg allows for incremental syncs of data with support for record modification. Fivetran’s idempotent pipelines use this capability to automatically sync records so they are up-to-date and accurate.
The Fivetran pipeline alleviates the need to implement stringent processes around building consistent pipelines. Further, the automated and no-code nature of Fivetran eliminates maintenance costs for data ingestion and integration.
Once the data has moved through the Fivetran pipeline and landed in Apache Iceberg, you can instantly query it right on the data lake with Amazon Athena, Amazon Redshift, or other query engines.
In terms of data security, Fivetran complies with high security standards, such as encryption of data in transit and at rest. Learn more in the Fivetran documentation.
Conclusion
Data lakes that are unwieldy and difficult to keep compliant are becoming a thing of the past. Fivetran and Amazon S3 with Apache Iceberg tables enable customers to modernize the data lake, making it compliant, consistent, and easy to consume for end users.
With security and governance controls— from source to destination to consuming services— users can feel comfortable with critical data as it moves through the pipeline. With Fivetran powering pipelines and Apache Iceberg’s ACID compliance and support for incremental syncs, your data is immediately available for any business needs, keeping your data lake a staple of the modern data stack.
Sign up for a free 14-day trial of Fivetran, and learn more about Fivetran in AWS Marketplace.
.

.
Fivetran – AWS Partner Spotlight
Fivetran is an AWS Competency Partner and fully managed data movement platform that automatically ingests and centralizes data from hundreds of sources into ready-to-analyze schemas.