AWS Partner Network (APN) Blog
How to Accelerate SAP Insights with Qlik, Snowflake, and AWS
By Sathisan Vannadil, Sr. Partner Solutions Architect – AWS
By Bosco Albuquerque, Sr. Partner Solutions Architect – AWS
By David Freriks, Emerging Technology Evangelist – Qlik
By Ripu Jain and Matt Marzillo, Sr. Partner Sales Engineers – Snowflake
Order-to-cash is a critical business process for every organization, particularly for the retail and manufacturing enterprise. It starts with booking a sales order (often on credit) followed by fulfilling that order, billing the customer, and finally managing accounts receivable for customer payments.
Sales order fulfillment and billing can impact customer satisfaction, and receivables and payments affect working capital and cash liquidity. As a result, the order-to-cash process is the lifeblood of the business and is critical to optimize.
SAP contains valuable sales orders, distribution, and financial data, but it can be a challenge to access and integrate data in SAP systems with data from other sources to get a full view of the end-to-end process.
For instance, understanding the impact of weather conditions on supply chain logistics could have a direct impact on customer sentiment and their propensity to pay on time. Organizational silos and data fragmentation can make it even more difficult to integrate with modern analytics projects. That, in turn, limits the value you get from your SAP data.
Order-to-cash is a process that requires active intelligence—a state of continuous intelligence that supports the triggering of immediate actions from real-time, up-to-date data. Streamlining this analytics data pipeline typically requires complex data integrations and analytics that can take years to design and build—but it doesn’t have to.
- What if there was a way to combine the power of Amazon Web Services (AWS) and its artificial intelligence (AI) and machine learning (ML) engine with the compute power of Snowflake?
- What if you could use a single Qlik software-as-a-service (SaaS) platform to automate the ingestion, transformation, and analytics for some of the most common SAP centric business transformation initiatives?
- What if suppliers and retailers/manufacturers could better collaborate by enabling reciprocal access to real-time data via Snowflake’s data sharing and marketplace capabilities?
In this post, we discuss the Qlik Cloud Data Integration accelerators for SAP which are being announced in collaboration with Snowflake and AWS.
Qlik Cloud Data Integration
Qlik Technologies is an AWS Data and Analytics Competency Partner that provides an end-to-end, real-time data integration and cloud analytics platform.
Qlik Cloud Data Integration accelerators integrate with Snowflake to automate the ingestion, transformation, and analytics to solve some of the most common SAP business problems. This enables users to derive business insights that can drive decision-making.

Figure 1 – Qlik Cloud Data Integration accelerators for SAP.
Qlik provides a singular platform for extracting data from SAP and lands the data into Snowflake as the data repository. Qlik keeps the data synchronized with its change data capture (CDC) gateway that feeds the transformation engine, allowing Qlik to convert the raw SAP data into business-friendly data ready for analytics.
Qlik uses its Qlik Cloud Analytics service on the SAP data to allow analytics and visualization, and to feed data into Amazon SageMaker to render predictions with the artificial intelligence (AI) and machine learning (ML) engine.
Snowflake: The Data Collaboration Cloud
Snowflake has AWS Competencies in Data and Analytics as well as Machine Learning, and has reimagined the data cloud for today’s digital transformation needs. Organizations across industries leverage Snowflake to centralize, govern, collaborate, and drive actionable insights.
Here are key reasons why organizations trust Snowflake with their data:
- Snowflake is a cloud- and region-agnostic data cloud. If a customer’s SAP data is hosted on AWS, for example, they are able to provision Snowflake on AWS and utilize AWS PrivateLink for secure and direct connectivity between SAP, AWS services, and Snowflake.
- Separation of compute and storage allows users granular controls and isolation, as well as role-based access control (RBAC) policies to different types of workloads. This means extract, transform, load (ETL) jobs can have isolated compute vs. critical business intelligence (BI) reports vs. feature engineering for ML, and users have control over how much compute to throw at each of these workloads.
- A thriving data marketplace to enrich customers’ first-party data with third-party listings. The marketplace allows secure data sharing internally as well as externally, without creating duplicate copies of data.
- A strong tech partner ecosystem, providing best-of-breed products in each data category: data integration, data governance, BI, data observability, AI/ML. Qlik is a Snowflake Elite Partner.
- Ability to bring code to data, rather than export/move out the data to separate processing systems, via Snowpark. Code in Java, Scala, or Python is stored in Snowflake.
Joint Solution Overview
Let’s dive into an SAP business use case that all companies share—orders to cash. This process in SAP usually covers the sales and distribution model, but we added accounts payable to complete the story.
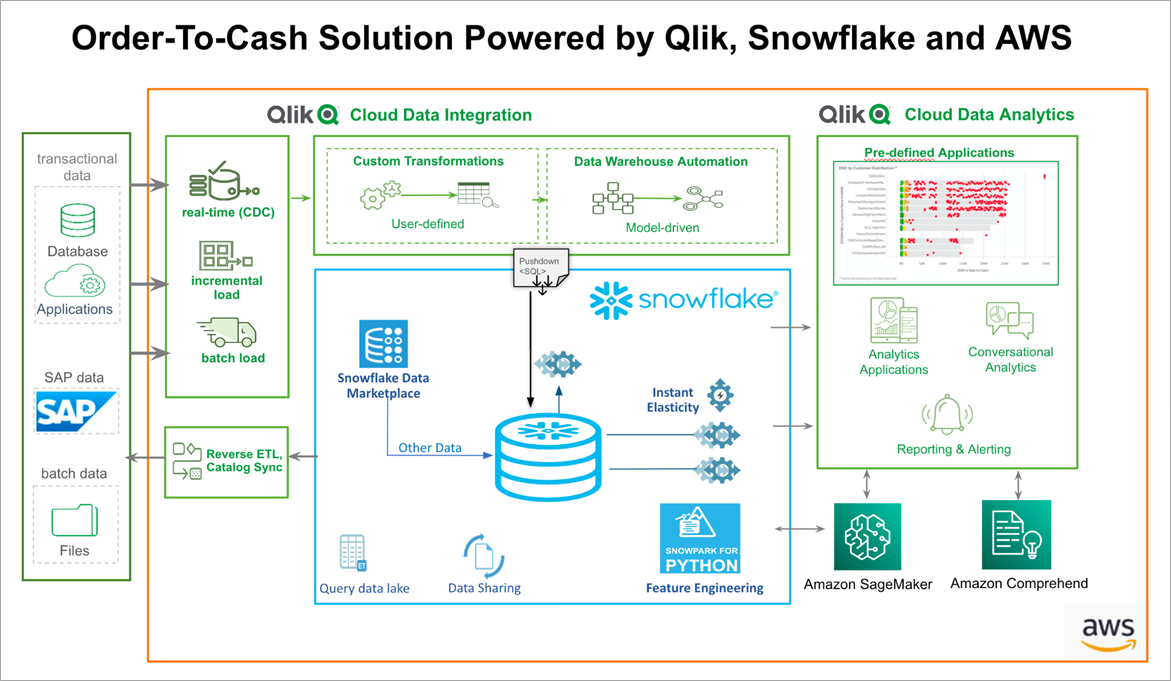
Figure 2 – SAP accelerators architecture for order-to-cash process.
The SAP accelerators use pre-built logic to turn raw SAP data into business-case analytics. It starts with getting the data out of SAP; you can deploy and install Qlik Data Gateway – Data Movement near the SAP system to pull the data from SAP and land it in Snowflake, without impacting the performance of the SAP production system.
For the SAP accelerators, we leveraged the SAP extractors as the foundation of the data layer. This pre-transformed data allows us to use smarter methods of pulling data from SAP. For the order-to-cash use case, we need 28 extractors which would be over 200+ tables if we went straight to the underlying SAP structure.
Using a single endpoint, we source the data from SAP into Snowflake partitioning the fact data by use cases; however, we use a common set of dimensions to feed the scenarios. Below is what this architecture conceptually looks like.
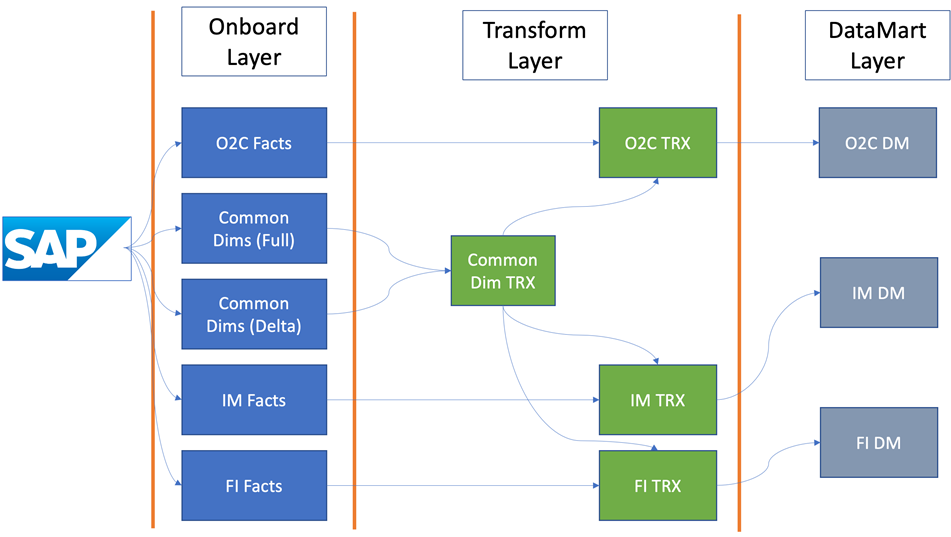
Figure 3 – QCDI data transformation process.
This process allows for easy future addition on new SAP use cases as well.
With our single endpoint, we can simultaneously load the data into our landing and storage areas. The data is only landed once, and Qlik uses views as much as possible to prevent data replication inside Snowflake.
Now, we have two different dimensional loads and some dimensions are not CDC-enabled (called Delta). Those are reloaded on a schedule and merged with the Delta dimension in a transform layer, which presents a single set entity for construction of the data mart layer.
Let’s take a look at the process for orders to cash. We land and store the data in Snowflake, and in the landing layer we add the rules that turn the SAP extractors names and columns into friendly names.
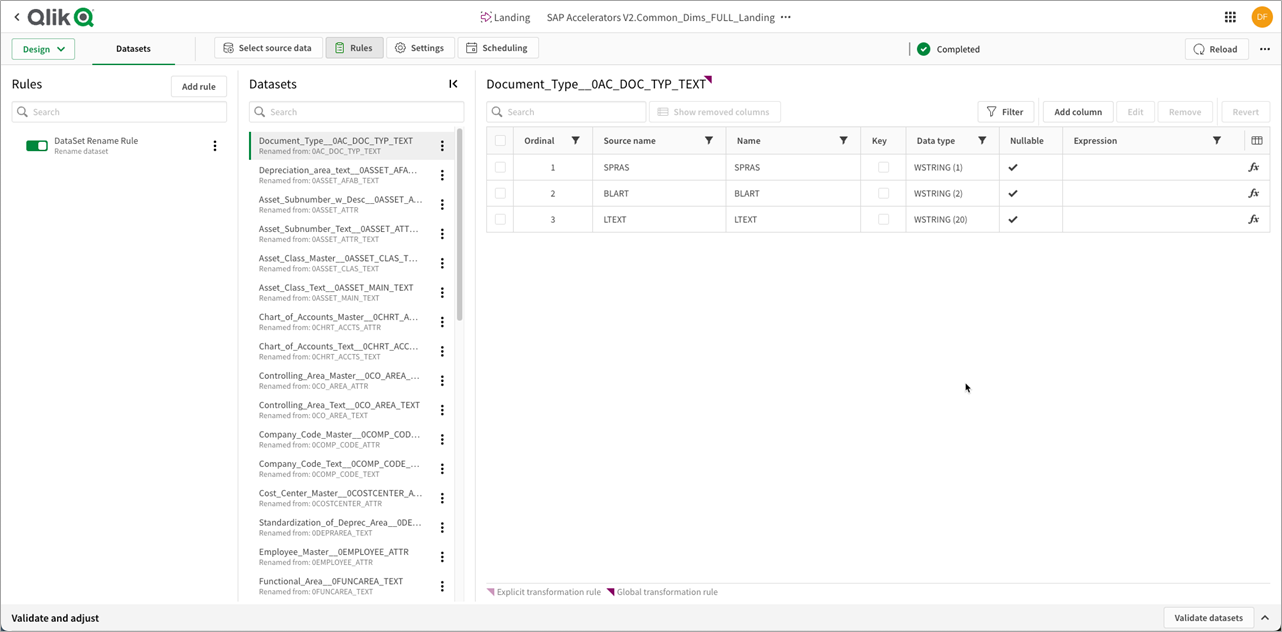
Figure 4 – QCDI SAP rules and metadata engine.
You may notice there are a lot of rules. We have run a report in SAP to extract all of the metadata by extractors, but not all names are the same. KUNNR is ship-to-customer in one extractor and sold-to-customer in another, for example.
Each extractor has its own definition, and we used Qlik Sense to create a metadata dictionary we can apply in the user interface (UI).

Figure 5 – QCDI SAP transformations.
As you can see, several important items are happening simultaneously. Within this no-code UI, we have piped around 80+ extractors into a landing area, renamed, and added views with friendly names in the store layer.
This is important as many SAP solutions require flows or coding for each extractor or table as its own individual piece of code to maintain, yet within Qlik it’s all managed simultaneously through the SaaS UI (no coding required).
Once the data is correctly keyed and renamed, we start running our transformation layers. This process combines the dimension into a single entity, and creates the business-specific process for a use case like orders to cash.
The transform layer is where we start manipulating the data with 100% pushdown SQL to Snowflake. Some example transforms include pivoting currency, flattening descriptive text, and other SQL manipulations.
In addition to the SQL manipulations, a Python Snowpark-stored procedure was created in Snowflake and called via the Qlik SQL pushdown. This demonstrates how engineers familiar with the Python language can build transformation steps as a stored procedure in Snowflake and access it via Qlik.
Once the data is fully mapped, transformed, and prepared, we create the final state data mart layer. Qlik Cloud Data Integration flattens the dimensional flakes into a true star schema ready for analytics, and these star schemas are consolidated under a single data mart layer by business process.
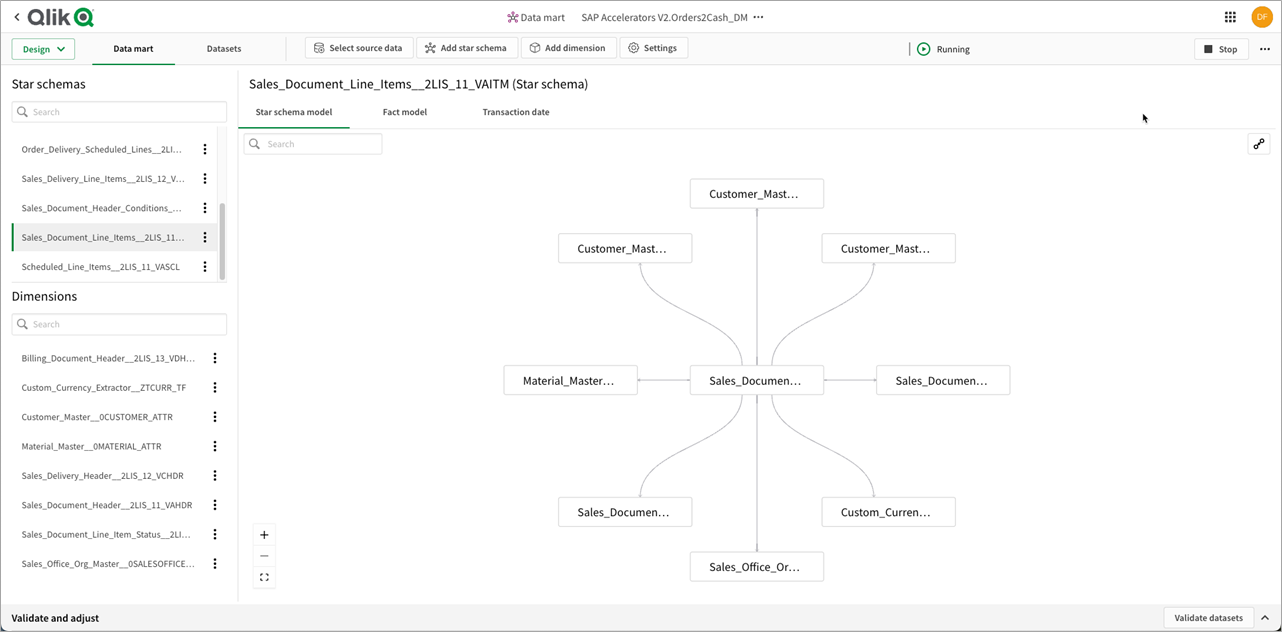
Figure 6 – SAP order-to-cash data marts by subject area.
Our data layer is now complete. We have used the Qlik Cloud Data Integration SaaS platform to load, store, transform, and deliver analytics-ready data marts to feed our Qlik SaaS analytics engine.
The SAP accelerators come with modules for orders to cash, inventory management, financial analytics, and procure to pay.

Figure 7 – QCDI process flow for the SAP accelerators.
SAP from Raw to Ready Analytics
With the data preparation done, we can now add the power of Qlik SaaS analytics. We ingest all of the star schemas from the data mart layer into Qlik and create a semantic layer on top of the pure SQL data.
Qlik’s associative engine is used to combine all parts of the order-to-cash module into a singular connected in-memory model. We also add master measures and online analytical processing (OLAP)-style complex set analysis calculations to create dynamic data entities, such as rolling dates or complex calculations like days sales outstanding.
Here’s what the refined analytics model looks like in Qlik SaaS. Notice how there are multiple fact tables (10) sharing that common set of dimensions.
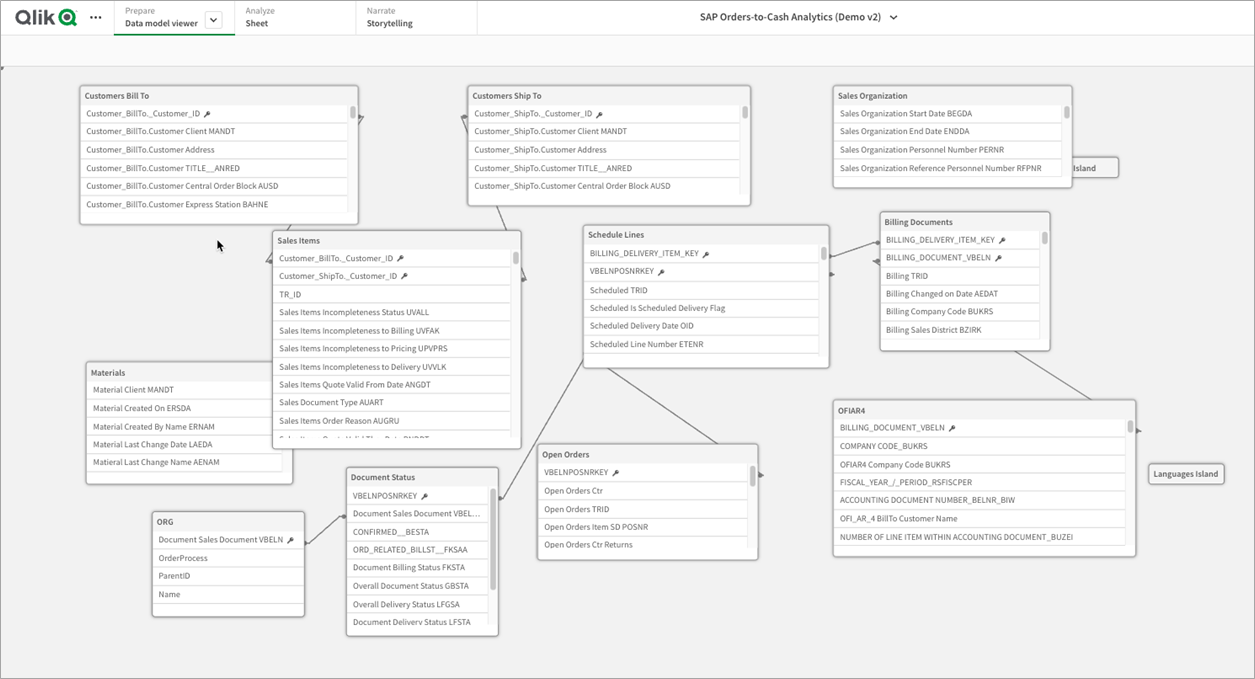
Figure 8 – Qlik SaaS data model.
Having access to all of that data allows us to see the big picture around the orders to cash process in SAP.
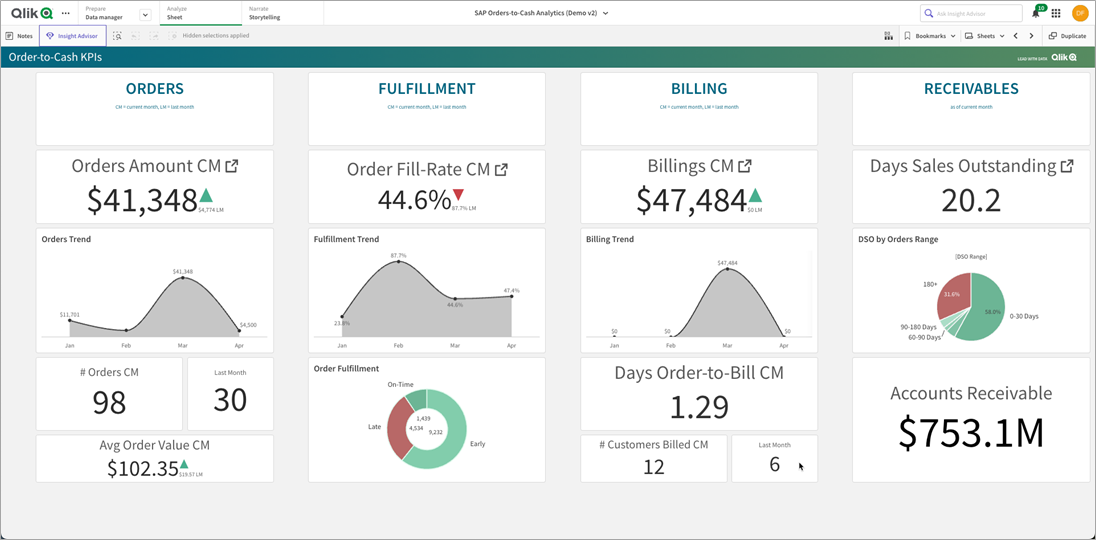
Figure 9 – Order-to-cash Qlik application.
SAP Order-to-Cash Analytics
The business question of how does an order move from the product being ordered, to when it was shipped, to when it was billed, to when the customer paid is what the order-to-cash module was built to answer.
Let’s take a look at an order a customer placed. That order (5907) was placed initially on 6/17/1999 and payment completed on 12/12/1999. That’s a days sales outstanding (DSO) of 194 days!
That would be the end of the question from using a simple SQL-based query tool, but with the Qlik associative model we can glean what occurred.
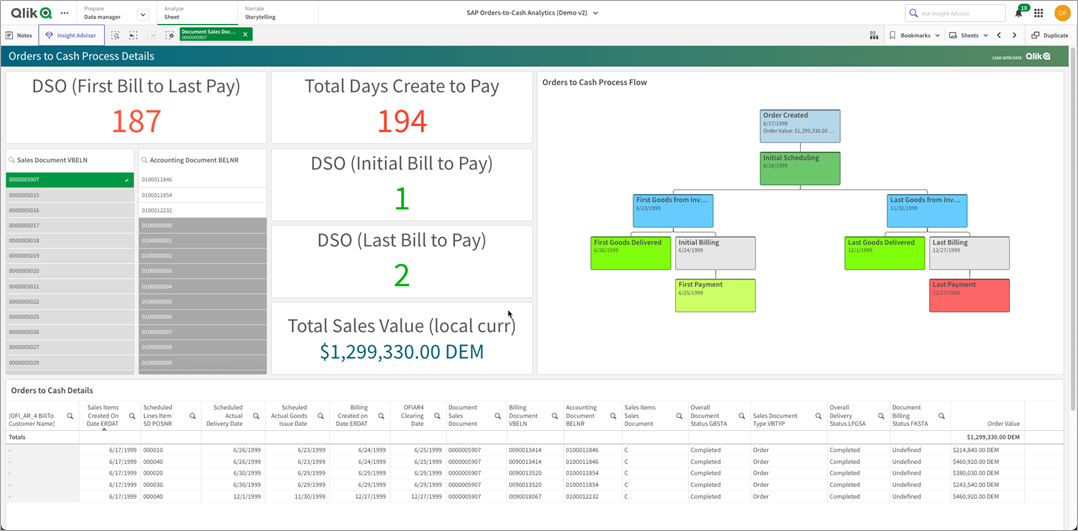
Figure 10 – Visual of the order-to-cash process in Qlik from SAP.
There wasn’t material in inventory to ship the whole order, so it was split into three separate shipments and billed/paid for in three documents.
Now, the overall DSO technically was 194 days, but only 187 days from bill to pay—that’s still not the whole story, though. The customer, when billed, actually paid in 1-2 days. This set of details would have been missed without leveraging the Qlik analytics engine.
Even in this use case, we are still only looking backwards at what has occurred. What about looking forwards and identifying trends? For example, parts that aren’t in inventory means we can’t ship everything at once. Using Amazon SageMaker, we can predict what issues and delays we may face.
What we have created with the SAP accelerators are plug-and-play templates to ask the hard questions of SAP data, with Snowflake and AWS as the engines driving the insights with the Qlik SaaS platform.
Predicting the Future with Amazon SageMaker
One of the more powerful components of the Qlik SaaS architecture is the ability to integrate the data in the Qlik application with the Amazon SageMaker engine. In our order-to-cash use case, we have taken sample data and trained a SageMaker model to make predictions on late vs. on-time delivery.
A quick way to achieve this is to utilize the Snowpark API to perform feature engineering on the dataset, before ultimately bringing the data in for training and deployment to a SageMaker endpoint. Then, for inference, we can use Qlik to access the endpoint and serve predictions right in the dashboard.
How does this work with analytics? Inside Qlik SaaS, we can create a connection to Amazon SageMaker to pass data from the Qlik engine into an endpoint which will predict the aforementioned predictions from the SAP data.
When the data is reloaded in the Qlik analytics engine, it feeds the data from relevant in-memory tables as data frames into the SageMaker endpoint where the AI/ML prediction will be calculated. The predictions are returned to the Qlik app and stored in the cache with the original data, and are available for the visualization layer to present.
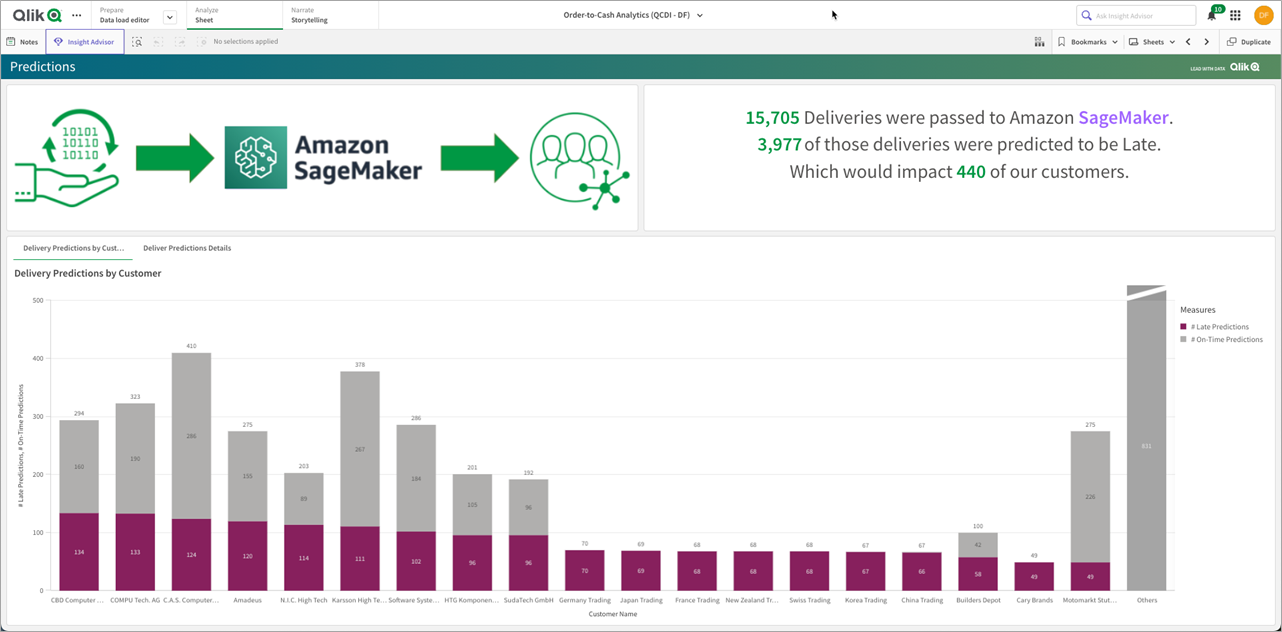
Figure 11 – Amazon SageMaker and Qlik SaaS integration.
We have now completed the circuit of taking historical data from SAP and machining and milling into analytics-ready data using Qlik Cloud Data integration. We have also presented that refined data with Qlik Cloud Analytics, and predicted future outcomes with Amazon SageMaker—all running on the Snowflake data cloud.
Conclusion
In a typical order management cycle, sharing information across organizations has become paramount to the successful operation of the modern enterprise. Improved customer satisfaction, increased competitiveness, and the reduction of supply chain bottlenecks and days sales outstanding are key indicators for an optimized cash flow for the business.
In this post, we discussed how the Qlik Cloud Data Integration SAP accelerator solution, in collaboration with Snowflake and AWS, can speed up your SAP data modernization, enable more agility and cross-organizational collaboration, and quickly deliver business solutions through optimized order-to-cash business insights.
To learn more, contact Qlik to start realizing the full potential of your SAP data.