AWS Partner Network (APN) Blog
How to Build a Real-Time Gaming Leaderboard with Amazon DynamoDB and Rockset
By Kehinde Otubamowo, Solutions Architect at AWS
By Shruti Bhat, SVP Product at Rockset
 |
 |
In this post, we will show you how to build a serverless microservice—a gaming leaderboard—that runs real-time search, aggregations, and joins on Amazon DynamoDB data.
Amazon DynamoDB is a fully-managed, serverless key-value and document database that delivers single-digit millisecond performance at any scale. Game developers build on Amazon DynamoDB for its scalability, durability, and consistency.
For microservices that predominantly write data, DynamoDB provides an “always on” experience at scale without the need for careful capacity planning, resharding, and database maintenance. These capabilities make DynamoDB a popular database service for various parts of game platforms like player data, game state, session history, and leaderboards.
To incentivize players, game developers turn to real-time interactive leaderboards, which can be microservices and operate independently from the core game design. A leaderboard entices competition among players by continuously adding, removing, and updating rankings across millions of users concurrently to display users’ relative placement in real-time.
Leaderboards require complex analytical queries that aggregate and join multiple aspects of game play in real-time for millions of concurrent gamers.
Key-value stores were not designed for analytics and support a limited number of query operators and indexes. That’s why it’s a best practice to pair Amazon DynamoDB with an analytics solution like Rockset that automatically indexes your data for fast search, aggregations, and joins at scale.
Rockset is an AWS Partner Network (APN) Select Technology Partner whose real-time indexing database in the cloud is used for real-time analytics at scale.
Amazon DynamoDB is Built for Write-Heavy Workloads at Scale
Game developers select Amazon DynamoDB for scalability and simplicity. Pennypop, the game developer behind Battle Camp, used DynamoDB to scale to 80,000+ requests per second. Clash of Clans, another developer, used DynamoDB to scale to tens of millions of players a day.
With DynamoDB, developers get the same single-digit millisecond performance at any scale, supporting peaks of more than 20 million requests per second. Furthermore, operating a game at scale does not come with overhead costs as DynamoDB is serverless.
Like other NoSQL databases, speed and scale come at the expense of flexibility. DynamoDB requires developers to identify the access patterns of their application and limit the number of data requests over the network.
For example, when retrieving game session information, it’s a best practice to retrieve start times, end times, users, and other properties using a single query. Designing the data model in DynamoDB requires forethought of what data properties will need to be retrieved, and when, in a gaming application.
For core gaming features, optimizing for the access patterns of the application is necessary to achieve speed at scale. For other analytical use cases where a couple seconds of data delay is sufficient, it makes sense to pair DynamoDB with a system that has greater flexibility at query time and support for search, aggregations, and joins.
Rockset is Built for Read-Heavy Workloads at Scale
Offloading read-heavy microservices gives game developers greater flexibility, as the data model used for writes does not need to carry over for reads.
As Rockset indexes the data, queries can easily be added or modified without being limited by the data modeling in DynamoDB. This makes it faster and easier to spin up new read-heavy microservices.
Fully Managed Sync to DynamoDB Updates
Rockset adopts the same serverless model as Amazon DynamoDB, obviating the need for software and hardware configuration and maintenance. As the number of new data-driven microservices grows, the infrastructure team at gaming companies can continue to stay lean.
The native integration with DynamoDB ensures new data is reflected and queryable in Rockset with only a few seconds delay. For read-heavy workloads, such as leaderboards, this allows game players to get updated scores within a couple of seconds.
Rockset uses a built-in connector with DynamoDB streams API for the data to constantly stay in sync. DynamoDB tables are initially linearly scanned, and then Rockset switches to the streams API to maintain a time-ordered queue of updates. With Rockset’s built-in connector to DynamoDB, a game developer does not need to build or manage their own integration with DynamoDB streams.
Automated Indexing for Fast Search, Aggregations, and Joins
Leaderboard queries need to aggregate player scores and join attributes across Amazon DynamoDB tables. Gaming data that’s stored in DynamoDB may contain heavily nested arrays and objects, mixed data types, and sparse fields. Many analytical backends require upfront schema definition (if they are SQL databases), or do not support joins (if they support flexible schemas). This can make leaderboard queries challenging to execute.
Rockset has native support for search, aggregation, and joins, and does not require data prep to run queries on JSON, CSV, XML, Avro, or Parquet data. At the time of ingest, Rockset automatically indexes your data in an inverted index for search and filter queries, a column index for large range scans, and a row index for random reads.
Rockset’s custom SQL-based query engine selects the best index for the query, returning searches, aggregations, and joins in milliseconds.
In Rockset, a leaderboard query uses the columnar index, fetching, and aggregating data only from the columns required, such as game scores and the gamer profile. When the dataset has a large number of columns, this leads to significant performance gains over a more traditional row-based approach since only a small fraction of the total data needs to be processed.
In contrast, you may want to use Rockset to search for individual player scores or attributes. These types of queries use the inverted index, fetching a list of records that match a selective predicate (player ID, for example). This means queries using selective predicates in Rockset return in tens of milliseconds regardless of the size of your dataset.
Automated indexing in Rockset provides developers support for a wide range of analytical queries, without cumbersome data cleaning.
Serverless Auto-Scaling for High QPS
Leaderboards need to compute millions of gamers’ positions in near real-time. With a disaggregated underlying architecture, Rockset can scale ingest compute, storage, and query compute independently to support these high queries per second (QPS) workloads.
If you need faster queries and high QPS, Rockset can horizontally scale out resources efficiently for your microservice. Gamers select DynamoDB for the scalability of writes and want the same scalability for reads, without the overhead of infrastructure maintenance.
Leaderboard Architecture
Take a look at the architecture for building a real-time leaderboard using Amazon DynamoDB and Rockset. Gamer-generated data is written to DynamoDB, and the Scan and Stream API keeps Rockset in sync and makes new data queryable with only a two-second delay.
Rockset automatically indexes data and serves complex leaderboard queries at scale.

Figure 1 – Leaderboard architecture.
How to Create a Leaderboard
We generated mock data of a fantasy soccer game to demonstrate how to build a real-time leaderboard using Amazon DynamoDB and Rockset.
The Datasets
Fantasy football or fantasy soccer is a game in which participants assemble an imaginary team of real-life footballers and score points based on those players’ actual statistical performance or their perceived contribution on the field of play. Fantasy games are very popular, with most variants having millions of players worldwide.
In fantasy soccer, points are gained or deducted depending on players’ performances each game week. Points systems vary between games, but points are typically awarded for achievements like scoring a goal, earning an assist, or keeping a clean sheet.
For the purpose of this demo, teams will consist of seven players—a typical selection would include a goalkeeper, four outfield players, and two substitutes. We’ll assign random points to each soccer player each week. To model this game, we used three tables—Gamers, Soccer_Players, and Gamer_Teams.
For demo purposes, we modeled the fantasy soccer demo application with three tables. Note that in most application use cases, you can store related items close together on the same DynamoDB table. For more info, please refer to our documentation on Best Practices for Modeling Relational Data in DynamoDB.
The Gamers table stores information about gamers playing the game.
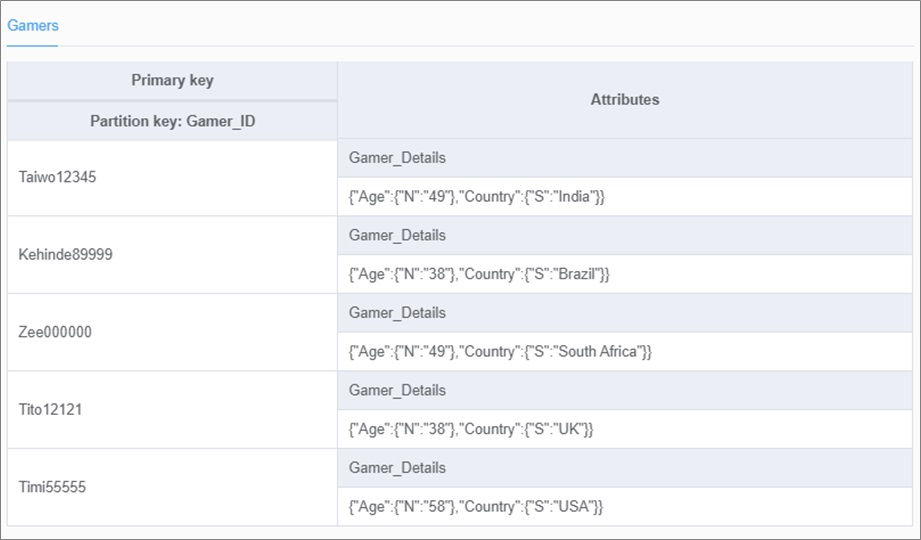
Figure 2 – Gamers table.
The Soccer_Players table contains information about soccer players that can be selected by gamers each week.

Figure 3 – Soccer_Players table.
Finally, we will store teams selected by each gamer in the Gamer_Teams table.
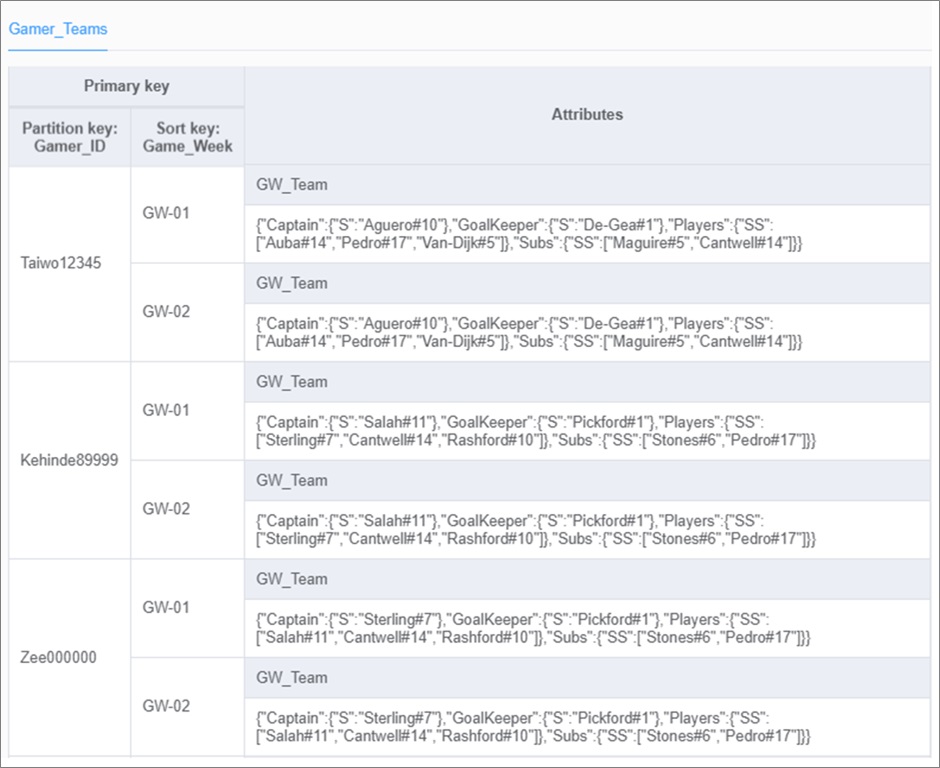
Figure 4 – Gamer_Teams table.
Integrate DynamoDB and Rockset
There are two steps to create an integration to Amazon DynamoDB:
- Configure an AWS Identity and Access Management (IAM) policy with read-only access to your DynamoDB table.
- Grant Rockset permission to access your AWS resource through either Cross-Account IAM Roles (recommended) or AWS access keys.
These permissions enable Rockset to read and index the data from DynamoDB. Find the step-by-step integration instructions in the Rockset docs.
Create a Rockset Collection
Rockset uses a document-oriented data model, with collections being the equivalent of tables in the relational world. You can create a collection in the Rockset console or programmatically using the REST API or a client software developer kit (SDK), including Python, Node.js, Java, or Golang.
We will create three collections, one for each of the DynamoDB tables, and give the collection a name, description, and select the DynamoDB table and AWS region.
The names of the collections are: dynamodb_soccer_gamer_teams, dynamodb_soccer_gamers, and dynamodb_soccer_players. A preview of the data is automatically generated as a SQL table.

Figure 5 – A preview of the data is automatically generated as a SQL table.
Leaderboard Query
For the leaderboard, we’ll generate a live, real-time score for the given week that’s made available to gamer teams. If a player scores a goal, the leaderboard will automatically update in near real-time with a new score and ranking of gamer teams.
We’ll also create an API and hit the endpoint every second so the latest scores are captured and displayed in the application. We can write the scores to soccer_score_totals collection to calculate an overall ranking of the gamer teams.
Rockset supports ANSI SQL with certain extensions for nested objects and arrays. You’ll see in the SQL below that we are aggregating the current gamer teams’ scores to display in near real-time.
To aggregate the scores, the SQL query makes use of the UNNEST function that can be used to expand arrays or values of documents to be queried. The query also highlights all of the other SQL goodness—sorts, joins, and aggregations.
Here’s the query results generated from the console:
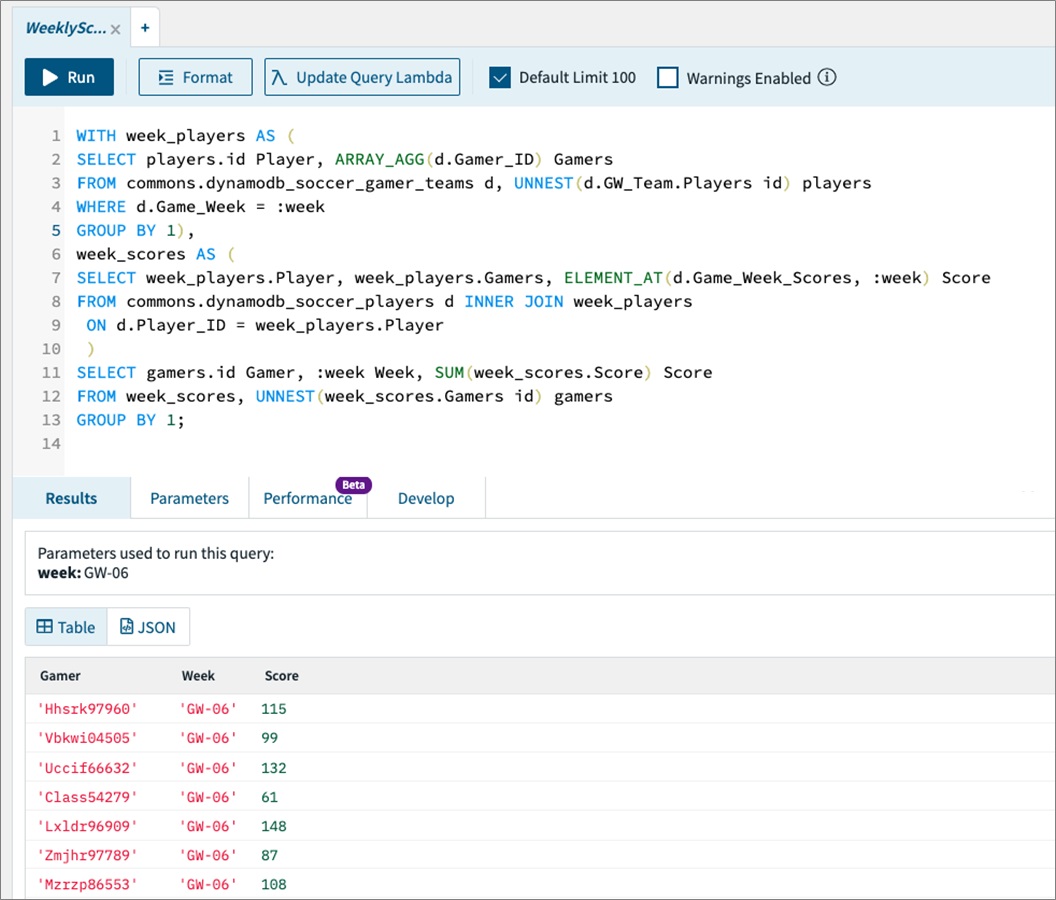
Figure 6 – Query results generated from the console.
We can modify the query above slightly to write the results into a new collection, dynamodb_soccer_score_totals, using the INSERT INTO command. We can use a select * from dynamo_soccer_score_totals to view the weekly results in the console.
Each week, new scores are generated. Rather than use a set value for the week, we can use a parameter in Rockset to specify the values in the SQL query at runtime.

Figure 7 – A parameter in Rockset can specify the values in the SQL query at runtime.
We can sum the total week’s scores to get a ranking of the gamer teams using the query below.
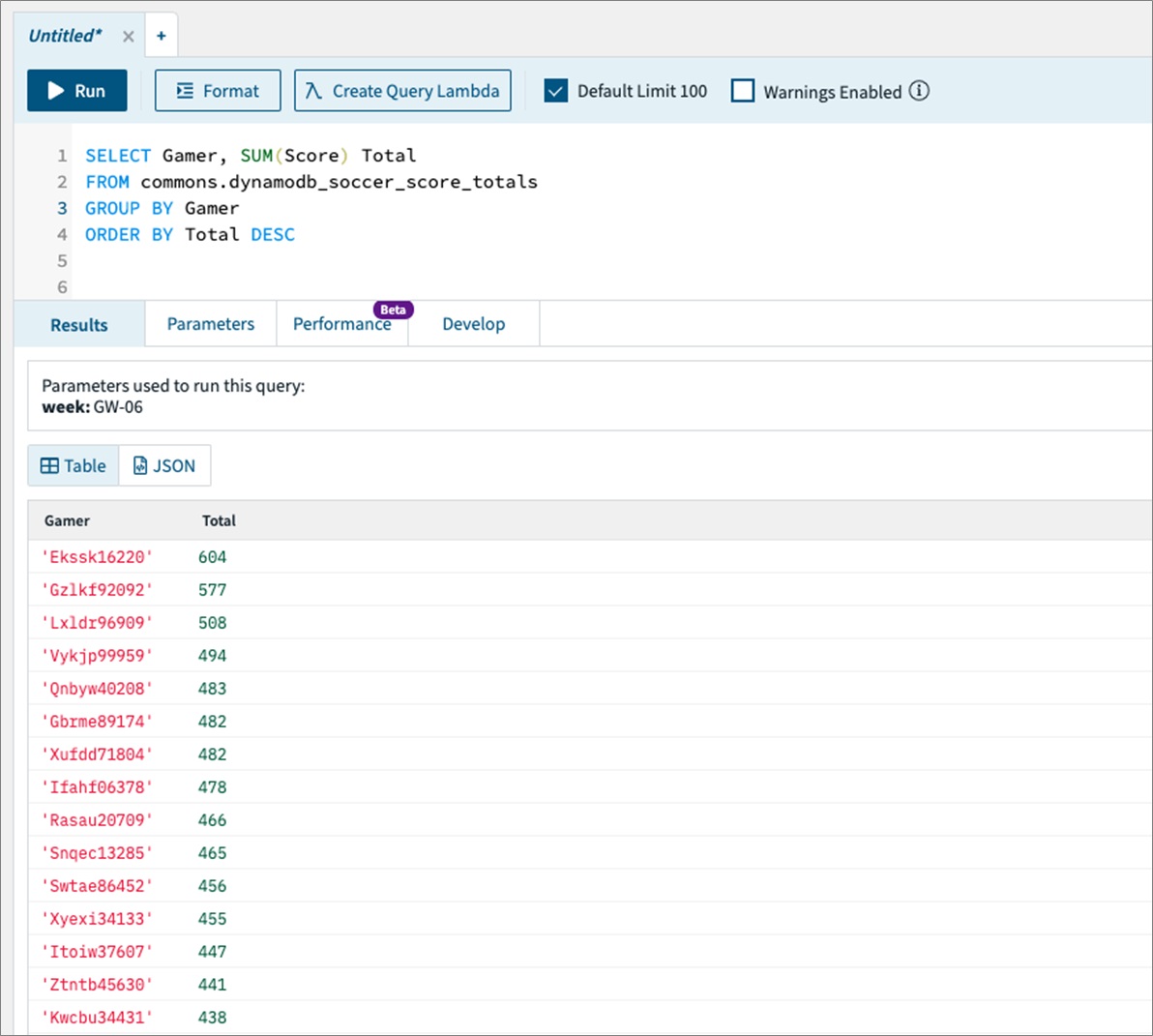
Figure 8 – We can sum the total week’s scores to get a ranking of the gamer teams.
The query we just ran in the Rockset console can be saved as a REST endpoint to create an API, also known as a Query Lambda. We can specify a default parameter value, like week-, or let the default be set at the query runtime. With a Query Lambda, we can save the query and run it directly from the application.

Figure 9 – Save the query and run it directly from the application using a Query Lambda.
We take the Query Lambda and execute it from a curl REST endpoint.

Figure 10 – Execute the Query Lambda from a curl REST endpoint.
Search Query
We can use Rockset’s inverted index to find the total score for a single gamer team. In a fantasy soccer game, this query could be triggered on login to display the gamer team’s score.
Rockset handles highly-complex search queries involving joins, aggregations, and ordering. These types of queries, even when run on large datasets, return results in milliseconds.
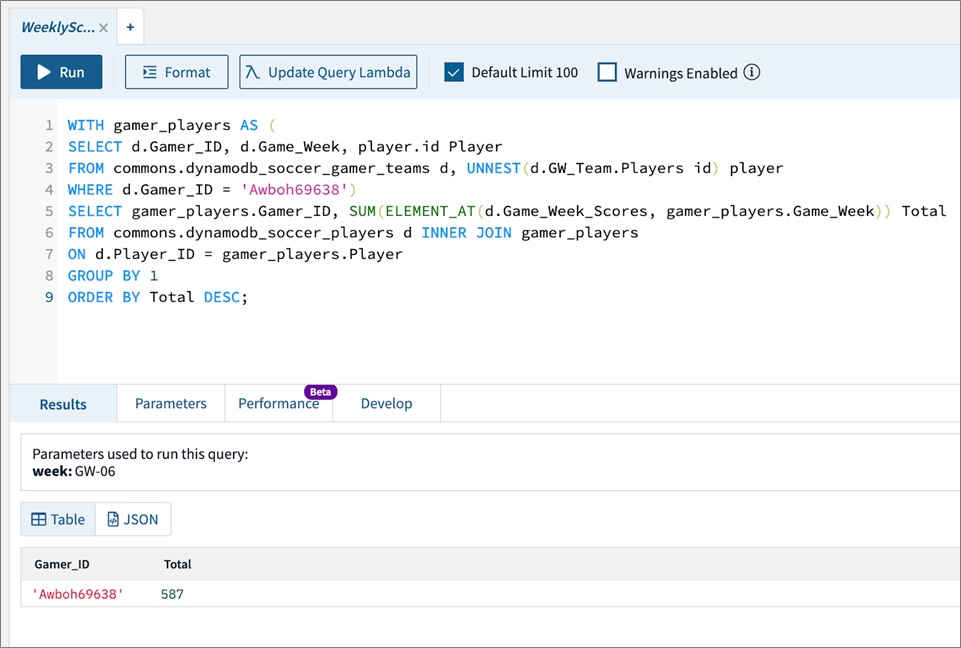
Figure 11 – Search queries, even when run on large datasets, return results in milliseconds.
Summary
With Amazon DynamoDB and Rockset, you have the flexibility to build read-intensive microservices independently of how the data is stored and modeled for the core gaming application.
Developers can synchronize data from DynamoDB to Rockset, run SQL queries on their data, and create APIs without needing to manage indexes, infrastructure, or schemas. The simplicity of Rockset gives developers the ability to quickly iterate on their game development and find new ways to monetize, engage, and grow adoption of their game.
.

.
Rockset – APN Partner Spotlight
Rockset is an APN Select Technology Partner whose real-time indexing database in the cloud is used for real-time analytics at scale.
Contact Rockset | Solution Overview
*Already worked with Rockset? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.