AWS Partner Network (APN) Blog
How to Proactively Detect and Repair Common Misconfigurations on AWS Using AvailabilityGuard NXG
By Avi Aharon, VP Head of Cloud Business at Continuity Software
 |
 |
Enterprises are continually searching for ways to perfect the management of their IT environments and operations. High on the list are the avoidance of performance disruptions, service unavailability, and outages.
Companies whose IT environments are hosted on Amazon Web Services (AWS) see fewer of these disruptions, but there are still opportunities to achieve better service and uninterrupted uptime. Misconfigurations and single points of failure in your IT environment are the main causes of disruptions and outages.
So whose responsibility is it to ensure availability and security? In its Shared Responsibility Model, AWS specifies that its obligations extend to operating, managing, and controlling the cloud. This includes “components from the host operating system and virtualization layer down to the physical security of the facilities in which the service operates.”
Customers, meanwhile, assume shared responsibility and management of the IT controls. According the Shared Responsibility Model: “Just as the responsibility to operate the IT environment is shared between AWS and its customers, so is the management, operation and verification of IT controls shared.”
Though the division of responsibility is clear, the reality of maintaining a fully operational cloud environment can be challenging. In addition to on-premises and legacy infrastructure, environments are often hybrid and employ diverse technologies (such as microservices and containers), layers, connections, and dependencies.
In this post, I will discuss several resilience assurance challenges faced by organizations when deploying critical production workloads on AWS. I will also present common misconfigurations we’ve encountered working with leading enterprise customers. Lastly, I’ll share recommendations on how you can proactively prevent misconfigurations using Continuity’s AvailabilityGuard NXG solution.
Continuity Software is an AWS Partner Network (APN) Advanced Technology Partner that helps enterprises achieve resilience in every type of IT environment. Our solutions help customers and proactively prevent outages and data loss incidents on critical IT infrastructure.
Factors Contributing to Complexity and Misconfigurations
Although AWS does its part to maintain the configuration of infrastructure devices, there are circumstances that cause a cloud environment to be more prone to misconfigurations.
While AWS provides building blocks, higher-level constructs, and prescriptive guidance, it’s ultimately the customers’ responsibility to architect, assemble, and operate them properly as a cohesive solution.
High Velocity of Changes
AWS releases new capabilities or services almost every day. For customers, that means your IT team must review these changes and upgrades often, understand their impact on the resilience of your cloud environment, and decide which to implement.
To ensure your environment operates smoothly, AWS best practices must be followed. Your other IT vendors will also change their best practices often, and these new recommendations and updates need to be tracked and implemented.
Knowledge Gaps Between People and Teams
The number of different professionals and teams working to maintain your cloud environment may also contribute to its complexity.
These people and teams may often work in isolation from one another and may not be aware of what others have done. Furthermore, they may not be aware of the most recent best practices. As a result, this lack of coordination can introduce new risks into the environment.
Insufficient Controls and Lack of Visibility
The massive number of changes made to a company’s IT environment can cause teams to be uncertain about the health of their overall environment. You may not truly know whether new applications or updates will improve, or perhaps harm, the environment’s operational availability and stability.
In a perfect world, changes made to IT environments would be tested so their impact on resilience and reliability could be seen before going live. However, the dynamic and urgent conditions of IT activity make manually testing each new app and service an unrealistic option for many organizations.
Sample Misconfigurations
Here are two examples of fairly common infrastructure resilience misconfigurations our customers have encountered in their AWS environments. Manual detection and resolution of these incidents is practically impossible because of the dynamic nature of IT environments.
It’s important to point out that these examples are by no means the most frequent or the only misconfigurations that may occur. As you’ll see, our examples may seem minor and be overlooked by IT teams, but that only means they are more likely to continue undiscovered until they lead to a disruption or downtime.
We’ve included steps for resolving each of these issues.
Example #1: Exceeding Service Limits on Amazon EC2 Resources
Amazon Elastic Compute Cloud (Amazon EC2) provides secure, resizable compute capacity on the AWS Cloud. Designed to make web-scale cloud computing easier for developers, Amazon EC2 allows you to obtain and configure capacity with minimal friction. It provides complete control of your computing resources and lets you run on Amazon’s proven computing environment.
In many organizations, the issue is that the same Amazon EC2 service is used by a number of teams—and one is not aware of the other. At peak times, when load is high, multiple Auto Scaling Groups may require more resources at the same time, and so the aggregated maximum size could potentially exceed the limit. This can lead to unplanned downtime when groups scale up at the same time.
When the service limit is reached, new Amazon EC2 instances will not start, and scaling up will fail. As a result, the application does not have sufficient resources to handle the load. This affects performance and could eventually cause downtime.
Identifying this issue before it evolves to an outage is a big challenge. Once identified, however, the resolution is very simple: use the Limits page in the Amazon EC2 console to request an increase in the limits for resources provided by Amazon EC2. Make a separate request for each AWS Region.
Example #2: Incomplete Virtual Machine Snapshot
The data on your Amazon Elastic Block Store (Amazon EBS) volumes can be backed up to Amazon Simple Storage Service (Amazon S3) by taking point-in-time snapshots.
Incomplete snapshots can prevent virtual machine (VM) recovery. If a disaster or security-related incident occurs, and the VM is not recoverable due to incomplete snapshots, significant data loss is likely.
A typical example is that a new disk is added to a VM but is missing a snapshot. To resolve this issue, simply add the missing disks to any future snapshot taken for the VM. For automated snapshots, update relevant scripts, processes, or tools. It may be necessary to take a new, complete snapshot, and then delete all incomplete copies.
A cost-saving tip: at times, partial copies are leftovers from maintenance or a data migration project. In these cases, there’s no data loss risk, but there is an opportunity to cut costs by deleting all incomplete copies.
Proactively Detect and Repair Misconfigurations with AvailabilityGuard NXG
For AWS customers with highly complex environments and large volumes of ongoing changes, it can be difficult to manually identify risks across their environment. As a result, occasional misconfigurations are a common symptom.
Continuity Software’s resilience assurance solution, AvailabilityGuard NXG, provides IT teams with a proven, simply-initiated, and non-intrusive routine to proactively and consistently pinpoint and repair misconfigurations in your AWS environment that may lead to service disruptions and downtime.
Among the key benefits of AvailabilityGuard NXG are:
- Preventing outages and data-loss incidents before they impact your business.
- Proactive resilience validation as part of a modern CI/CD pipeline.
- Facilitating automated self-healing to achieve greater reliability while decreasing operational costs.
AvailabilityGuard NXG’s read-only mode scans your IT environments, covering VMs, virtual networks, load balancers, databases, cloud storage, Domain Name System (DNS), and more. Scan results are compared against our proprietary knowledge base of best practices.
The knowledge base, which is continually updated and growing, contains hundreds of AWS, vendor, industry, and power-user best practices relevant for the applications and solutions used by any enterprise.
The comparison between scan results and knowledge base reveals best practice deviations. These are immediately forwarded to the IT teams or business owners responsible for handling them, and include guidelines for repair. Since each issue is ranked in terms of urgency and impact to the business, teams know which point of failure they should tackle first.
Enterprises using AvailabilityGuard NXG can gain additional insights through the solution’s dashboard, where you get a top-level view of the environment’s resilience status. Users can also drill down to obtain the relevant details behind the figures and statuses displayed in the dashboard.
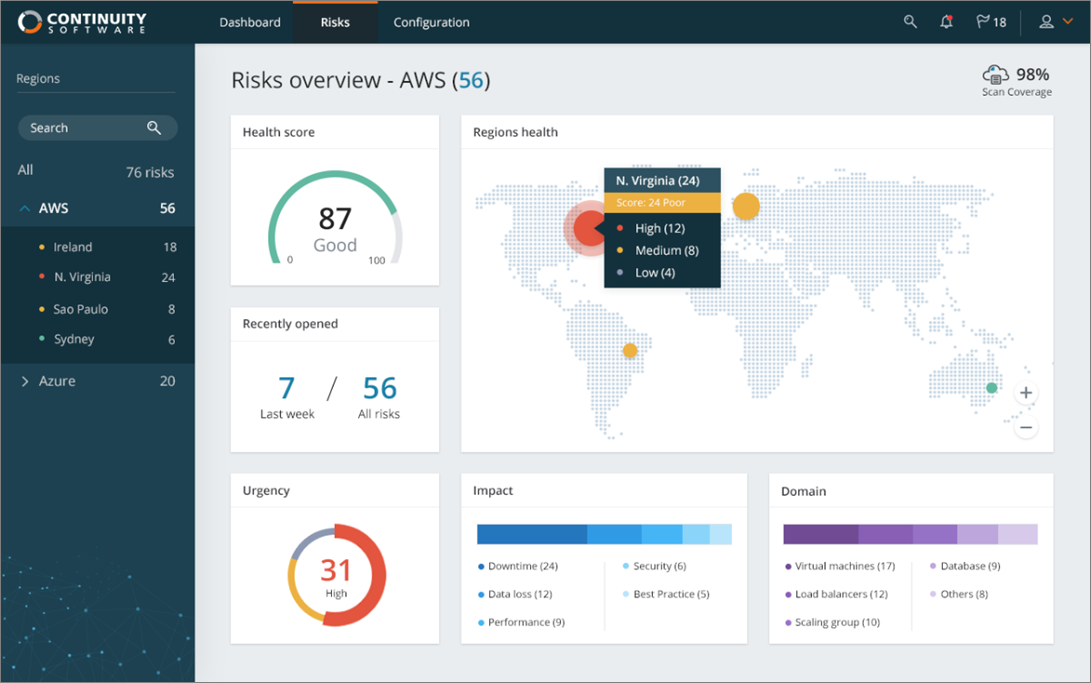
Figure 1 – Dashboard showing resilience risks by region and business impact.
Gain Visibility and Control into Resilience Status
With AvailabilityGuard NXG, managers, DevOps and application developer teams gain visibility and control in three major ways, all of which contribute to operational excellence and improving key performance indicators.
First, a clear, intuitive dashboard provides an enterprise-wide view of resilience and health scores, and includes drill-down abilities. Risks are ranked in terms of urgency and impact to business, performance, and more.
Second, you can drill down to see information about individual risks. Incident tickets include details on parameters affecting resilience, all misconfigurations that must be corrected, business impact, urgency, and guidance on how to correct them.
The incidents can be integrated with existing ITSM tools to facilitate automatic incident generation and assignment to subject-matter experts for remediation.
Third, automatic resilience validation becomes an integral part of CI/CD and DevOps processes, and new apps and services implementations.
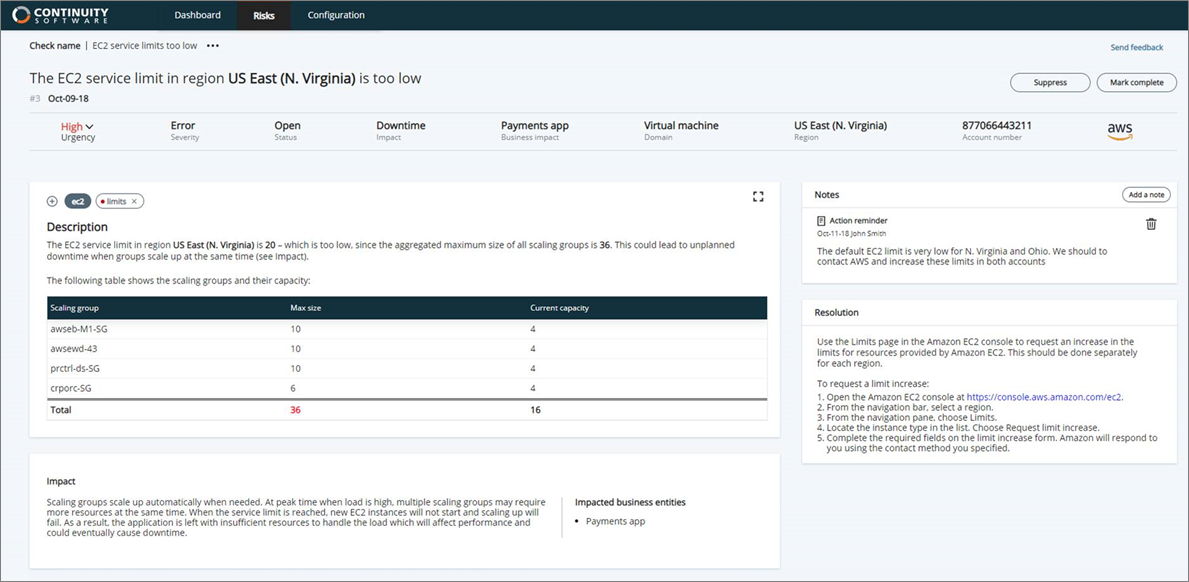
Figure 2 – Example of exceeding service limits on Amazon EC2 resources.
Going back at the sample misconfigurations we described above, you can see in Figure 2 what an Amazon EC2 resources limits risk (example #1) might look like in AvailabilityGuard NXG. The issue here is in the US East (N. Virginia) region, and it affects the payment application with a risk of downtime.
The solution lists specific scaling groups that are related to this problem, and you also get a detailed explanation how to fix the problem using the Amazon EC2 console.
Similarly, the screen shot in Figure 3 demonstrates what an incomplete VM snapshot risk (example #2) might look like in AvailabilityGuard NXG. This issue is impacting the M&O service with a risk of data loss, and you can see when the partial snapshot is from and decide what should be done with it.
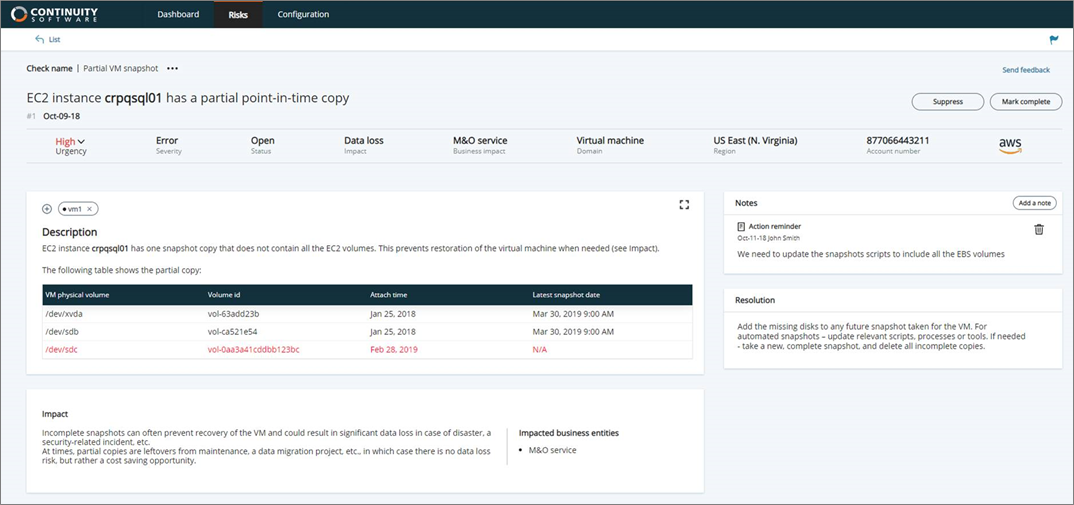
Figure 3 – Example of an incomplete virtual machine snapshot.
Customer Success Stories
One of our Fintech customers used AvailabilityGuard NXG to scan and analyze configuration data from all of the AWS infrastructure layers. The scans detected more than 300 configuration risks in Amazon EC2, Amazon CloudFront, Amazon S3, Elastic Load Balancer, and other AWS services.
The results were an eye-opening revelation for the customer’s DevOps team, who realized that with AvailabilityGuard NXG for AWS they could more reliably provide uninterrupted availability to their customer base in the high-pressure world of online trading.
Another of Continuity Software’s customers, a large European telco is characteristic of the modern enterprise where the core of business operations resides in complex and interconnected and hybrid IT environments that are prone to misconfigurations and outages. The profusion of changes, updates, fixes, and upgrades that routinely occur in such environments makes attaining and maintaining resilience a real challenge.
Using AvailabilityGuard NXG, this customer’s DevOps and development teams were able to quickly validate and improve the operational resilience of their critical environment, and ensure that the highest levels of resilience are continuously maintained.
The team at the European telco concluded that AvailabilityGuard NXG helps them to “be more confident about our infrastructure.”
Summary
During the past decade or so, IT environments have changed profoundly. As a consequence, the challenges of keeping them resilient have grown even greater.
In a highly complex technology environment, and with lots of ongoing changes and ever-evolving best practices, it’s difficult to manually identify risks. Thus, misconfigurations are a natural result.
At Continuity Software, we’ve seen how AvailabilityGuard NXG helps customers proactively discover and remediate resilience assurance challenges while deploying critical production workloads on AWS.
If you’re interested in checking our what AvailabilityGuard NXG can uncover in your AWS environment, out starter package allows you to scan up to 1,000 nodes and discover the misconfigurations that have potential to cause performance disruptions and outages.
Get started with AvailabilityGuard NXG on AWS Marketplace >>
You can also join our upcoming webinar to learn more: Proactively Detecting and Repairing Misconfigurations in Your AWS Environment
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Continuity Software – APN Partner Spotlight
Continuity Software is an APN Advanced Technology Partner. Their solutions proactively prevent outages and data loss incidents on critical IT infrastructure. As a result, unplanned outages are reduced and configuration errors are resolved before they turn into costly service incidents.
Contact Continuity Software | Solution Overview | Buy on Marketplace
*Already worked with Continuity Software? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.