AWS Partner Network (APN) Blog
How to Use Matillion Data Loader for Batch Loading Data to Amazon Redshift Serverless
By Nidhi Gupta, Sr. Partner Solutions Architect – AWS
By Molly Sandbo, Director Product Marketing – Matillion
 |
| Matillion |
 |
In today’s fast-paced world, analyzing data quickly to make intelligent and confident decisions can make the difference between lagging or leading the market. Amazon Redshift Serverless makes it easier to run and scale analytics without the burden of managing infrastructure.
You can use Matillion Data Loader to extract data from source systems and load it to Amazon Redshift Serverless without having to worry about coding or managing infrastructure. Matillion Data Loader enables organizations that have data coming in from an ever-increasing number of sources and need faster, simpler access to insights and analytics.
In this post, we will learn how to load data easily into Amazon Redshift Serverless using Matillion Data Loader. We’ll go through an example of batch loading from Salesforce to Amazon Redshift Serverless as the destination.
Matillion is an AWS Data and Analytics Competency Partner with the Amazon Redshift specialization. An AWS Marketplace Seller as well, Matillion delivers modern, cloud-native data integration technology solving individual’s and enterprise’s top business challenges.
Matillion Data Loader Overview
Matillion Data Loader is a software-as-a-service (SaaS) data loading platform that extracts data from popular sources and loads it into cloud data platform destinations. It’s designed to have minimal setup and pipeline build time to get you loading data as quickly as possible.
Matillion Data Loader works equally well with Amazon Redshift and Amazon Redshift Serverless as the destination. If you’d like to jump in right away, you can register and start using Matillion Data Loader for free at dataloader.matillion.com or through the Matillion Hub.
Some key features of Matillion Data Loader are:
- No-code pipeline creation to empower more users across organizations and speed up data pipeline creation and loading.
- Platform that supports both batch and change data capture (CDC) pipelines.
- Automatic schema drift propagation without assistance from IT or the need to code, saving time and reducing the number of job failures and delays due to source data schema drift.
- Integration with Matillion ETL for pre-built data transformations.
Matillion Data Loader provides two methods to load data:
- Batch loading
- Change data capture loading
Let’s discuss in detail the steps to load data to Amazon Redshift using Matillion Data Loader.
Prerequisites
You should have the following prerequisites to get started with Matillion Data Loader:
- Active Matillion Hub account. For more information, read the Matillion Hub overview.
- Salesforce account as the data source.
- Amazon Redshift as the destination. Refer to the documents below to set up Amazon Redshift:
- Credentials to allow Matillion Data Loader to connect with the source and destination systems.
Matillion Data Loader batch loading enables users to create new pipelines with minimal configuration and complexity, and without any coding. Data is loaded in batches at periodic intervals like once per day or once per hour. This self-service and serverless data loading saves time, allowing organizations to move enormous amounts of data into the cloud to analyze and gain insights fast.
Incremental batch loading using a high-water mark—like a time, version, or status indicator—is also supported, depending on your source data models to provide only changed data after the initial load.
For loading data to Amazon Redshift, data is staged in Amazon Simple Storage Service (Amazon S3). The data loading process automatically adds audit columns (a batch ID and a timestamp) to facilitate traceability before the staged data is written to the final target tables in Amazon Redshift. The staged data is then deleted from Amazon S3.
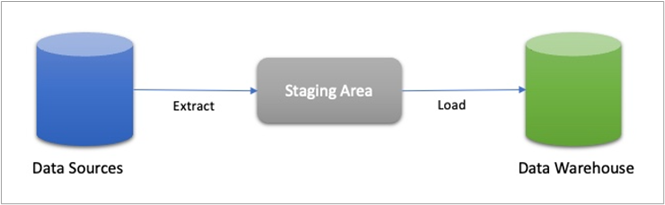
Figure 1 – Batch loading process.
Use Case: Ingest Data from Salesforce by Setting Up a Batch Pipeline
Let’s look at a real-life scenario. A business wants to gain insights about which personas are buying their products so they can implement more targeted sales and marketing campaigns. They set up a batch pipeline to ingest data from the Account and Contact tables within Salesforce on a daily basis.
With Matillion Data Loader, this takes three easy steps: choose the source data, select the destination, and set the frequency of batch loading runs.
Step 1: Choose Your Data Source, Tables, and Columns
The first step is to select your data, and Matillion Data Loader connects to most popular data sources directly.
When you log in to Matillion Data Loader for the first time, a welcome page is displayed, inviting you to create your first pipeline by clicking Add pipeline. Be sure to select your region using the region selector on the bottom right of the page. Refer to MDL Pipeline UI in the documentation to follow along.
For this example, we want to load data from Salesforce. You can either scroll down the list or start typing “Salesforce” in the search filter. Then select Salesforce.
Next, provide your Open Authorization (OAuth) credentials to connect to Salesforce. OAuth is a fully-secure authentication protocol that allows you to approve an application interacting with another on your behalf without giving away your password.
To add a new OAuth credential, click the “OAuth” drop-down and press Add new credential.
Now, type a unique name for your OAuth and press Authorize, which will take you to the Salesforce login page. Go back to the Matillion Data Loader page and press Continue.
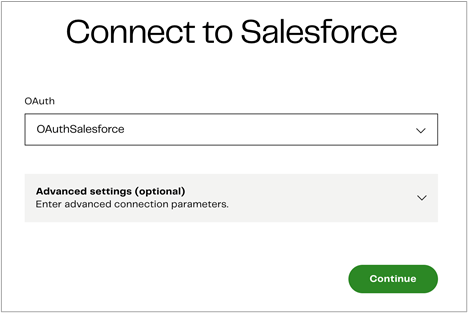
Figure 2 – Use OAuth credentials to connect to Salesforce.
When you click Continue, Matillion Data Loader will connect to Salesforce and bring up a list of tables. You can select any tables you want to include in the pipeline. Let’s choose the Account and Contact tables.
You can also choose to sync deleted records if desired, which will delete records from the target table that have been deleted from Salesforce in the last 30 days.
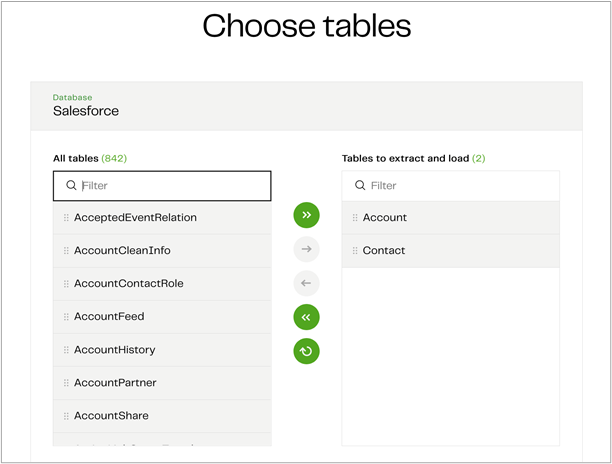
Figure 3 – Choose source table from Salesforce.
For batch loading, you can be even more specific and deselect specific columns from your tables (all columns are loaded by default).
To do this, review your dataset by selecting the source table. This brings up a window to deselect specific columns. For example, if you want to exclude personally identifiable information (PII), you can deselect the columns that contain PII like name and phone number.
When you are done with this step, click Continue to move on to selecting your data destination.
Step 2: Choose Your Destination
The second step is to choose your data destination, and you can either use Amazon Redshift or Amazon Redshift Serverless. To follow along with Matillion’s documentation, refer to Set up Amazon Redshift.
You must have an active AWS account and instance with permissions to create and manage security groups to allow Matillion’s IP addresses, view database details, and have privileges that let you create users and grant privileges.
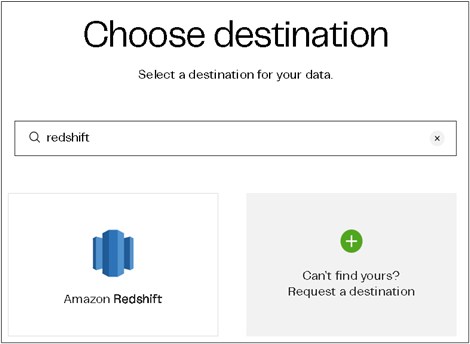
Figure 4 – Choose Amazon Redshift as destination cloud data warehouse.
Once you select Amazon Redshift, input your AWS access credentials and provide the additional information to connect to Amazon Redshift.
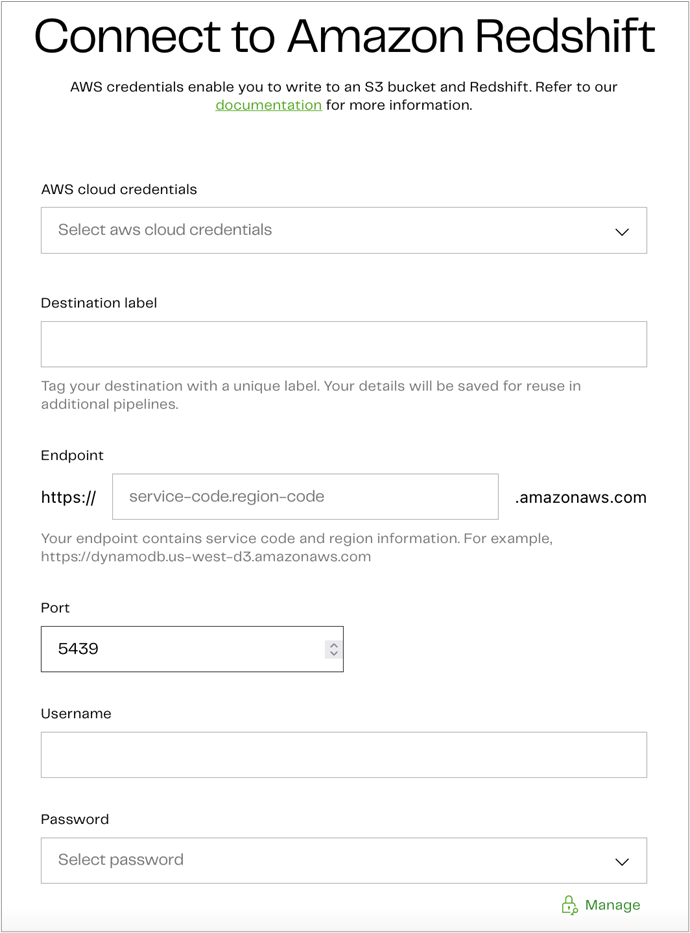
Figure 5 – Enter Amazon Redshift endpoint details.
Click Test and continue to test your settings and move forward.
Step 3: Set the Frequency of Your Batch Runs
The final step is to set the frequency of your batch runs. You can choose a minimum of every five minutes or a maximum of once every seven days. Simply select your desired frequency and click on Create pipeline.
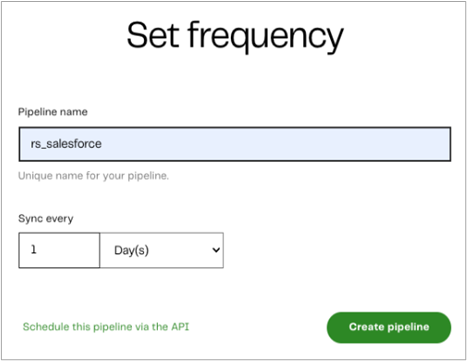
Figure 6 – Set frequency for batch runs.
Matillion Data Loader creates all of the code needed to securely access and extract selected data from your source, and then loads the data into your destination. Connections are tested and confirmed in the three-step process above, giving you a robust batch data pipeline in just minutes.
In the screenshot below, you see the rs_salesforce pipeline is syncing its initial data load. Once the initial loads are complete, you will see the “active” status for each pipeline.

Figure 7 – Matillion Data Loader dashboard.
Once the pipeline runs successfully, follow these steps:
- Sign in to the AWS console and open the Amazon Redshift console.
- On the navigation menu, choose Query editor v2, and then connect to a database in your cluster.
- Query the Amazon Redshift table.

Figure 8 – Amazon Redshift query editor.
If you need assistance at any time, reach out to Matillion Support.
Summary
In this post, we created a batch pipeline for batch loading Salesforce data to Amazon Redshift. You can view the status of the batch pipeline through the Matillion Data Loader dashboard.
To learn more about Matillion Data Loader, visit Matillion’s website, register for a weekly demo, or schedule a demo specifically for your organization.
To get started immediately, you can register and start using Matillion Data Loader for free at dataloader.matillion.com or through the Matillion Hub.
You can also learn more about Matillion on AWS Marketplace.
.

.
Matillion – AWS Partner Spotlight
Matillion is an AWS Partner that delivers modern, cloud-native data integration technology solving individual’s and enterprise’s top business challenges.
Contact Matillion | Partner Overview | AWS Marketplace | Case Studies