AWS Partner Network (APN) Blog
IBM Cloud Pak for Data Simplifies and Automates How You Turn Data into Insights
By Mark Brown, Sr. Partner Solutions Architect – AWS
By Linh Lam, Sr. Partner Solution Architect – AWS
 |
| IBM |
 |
Many data-driven workloads will take advantage of artificial intelligence (AI), but businesses still face challenges in delivering real AI solutions operationally. Data is often locked up in silos or is not business-ready in other important ways.
Customers also face strains in their on-premises data infrastructure due to aging, high maintenance, resource and energy costs, and expansion requirements. Many have chosen Amazon Web Services (AWS) for its wide range of cost-effective data storage services and industry-leading technical resources.
AWS and IBM recently announced that IBM Cloud Pak for Data, a unified platform for data and AI, has been made available on AWS Marketplace. You can easily test, subscribe to, and deploy the Cloud Pak for Data platform on AWS.
By running on Red Hat OpenShift and being integrated with AWS services, the platform simplifies data access, automates data discovery and curation, and safeguards sensitive information by automating policy enforcement for all users in your organization.
IBM Cloud Pak for Data comes with well-known applications in categories such as:
- Built-in data governance applications (IBM Watson Knowledge)
- Data quality and integration applications (IBM DataStage)
- Model automation (IBM Watson Studio)
- Purpose-built AI model risk management
By offering a unified suite of data management and governance, AI, and machine learning (ML) products, the platform delivers on the following use cases:
- Data access and availability: Eliminate data silos and simplify your data landscape to enable faster, cost-effective extraction of value from your data.
- Data quality and governance: Apply governance solutions and methodologies to deliver trusted business data.
- Data privacy and security: Fully understand and manage sensitive data with a pervasive privacy framework.
- ModelOps: Automate the AI lifecycle and synchronize application and model pipelines to scale AI deployments.
- AI governance: Ensure your AI is transparent, compliant, and trustworthy with greater visibility into model development.
Unlocking the Value of Your Data
Built on Red Hat’s OpenShift Container Platform, IBM Cloud Pak for Data gives you access to market-leading IBM Watson AI technology on AWS’ highly available, on-demand infrastructure. In addition, auto scaling capabilities enable you to rapidly establish a single data and AI platform at global scale.
Customers gain a streamlined data pipeline, leveraging the AWS services they are using to collect data and feed it directly into IBM Cloud Pak for Data to generate actionable insights in real time. This gives you the ability to create a federated data model and extend data and business services to pull data from multiple sources
Prerequisites
This product requires a moderate level of familiarity with AWS services. If you’re new to AWS, visit the Getting Started with AWS and AWS Training and Certification pages. These sites provide materials for learning how to design, deploy, and operate your infrastructure and applications on the AWS Cloud.
This product also assumes basic familiarity with IBM Cloud Pak for Data components and services. If you’re new to IBM Cloud Pak for Data and Red Hat OpenShift, please see these additional resources.
It’s highly recommended the IBM Cloud Pak for Data Deployment Guide be consulted and reviewed prior to using this product.
Using AutoAI in Cloud Pak for Data
In this post, we will introduce you to AutoAI as an example to demonstrate one of Cloud Pak for Data’s capability to simplify the model automation process.
AutoAI is a graphical tool in Watson Studio that automatically analyzes your data and generates candidate model pipelines customized for your predictive modeling problem.
IBM Cloud Pak for Data comes ready to connect to your AWS data sources:
- Amazon RDS for MySQL
- Amazon RDS for Oracle
- Amazon RDS for PostgreSQL
- Amazon Redshift
- Amazon S3
- Amazon Athena
For example, if your data is in Amazon Simple Storage Service (Amazon S3), you can connect S3 to IBM Cloud Pak for Data at a platform level, making your S3 files accessible for use by Watson services.
The easy-to-use instructions on how to make the connection are found in the IBM documentation.
To create the connection asset, you need these connection details:
- Bucket name that contains the files.
- Endpoint URL: Include the region code. For example, https://s3.<region-code>.amazonaws.com. For the list of region codes, see AWS service endpoints.
- Region: This is the AWS region. If you specify an endpoint URL that is not for the AWS default region, then you should also enter a value for Region.
- Credentials:
- Access key
- Secret key
Let’s start by picking the data source; in this case, we’re using a market data set and would like to predict mortgage default risk. The following screenshot demonstrates the AutoAI configuration in a graphic interface.
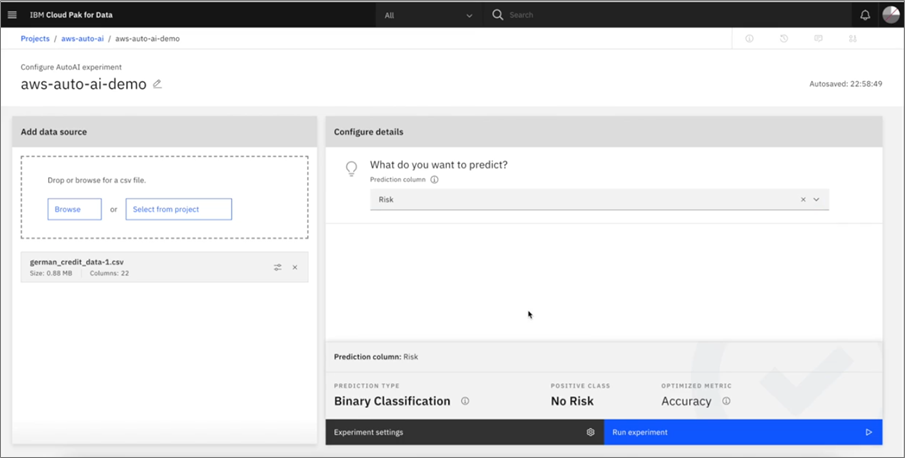
Figure 1 – Configuring an AutoAI experiment.
Once it parses the data file, it will give the option to pick one or more features or attributes of that data set for use during production. The experiment is an automation that enables us to go through the data sets, build out features, and automatically apply transformation to the data.
The next screenshot shows the tool in the process of going through candidate algorithms to build “pipelines” for the data processing that will produce models.
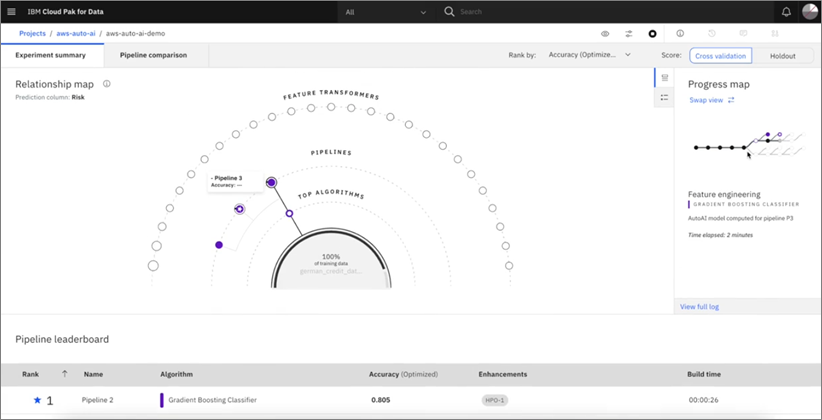
Figure 2 – Map of algorithmic paths.
While this process can take some time depending on the amount and complexity of the data sets, the end result is a set of eight pipelines ordered by accuracy.
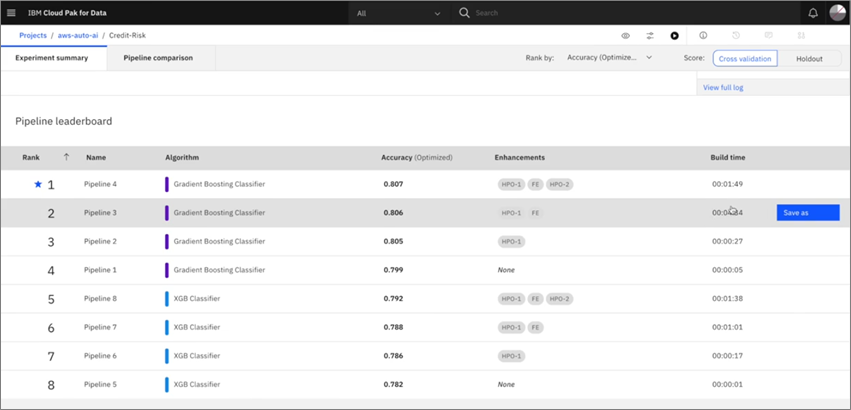
Figure 3 – Pipeline selection.
These are models you can save, deploy, and expose as endpoints. Once the endpoint has been created, users can look at examples of how to consume that model’s invoked predictions in various different program languages.
Here’s an example Scala code snippet for use with the model just created.
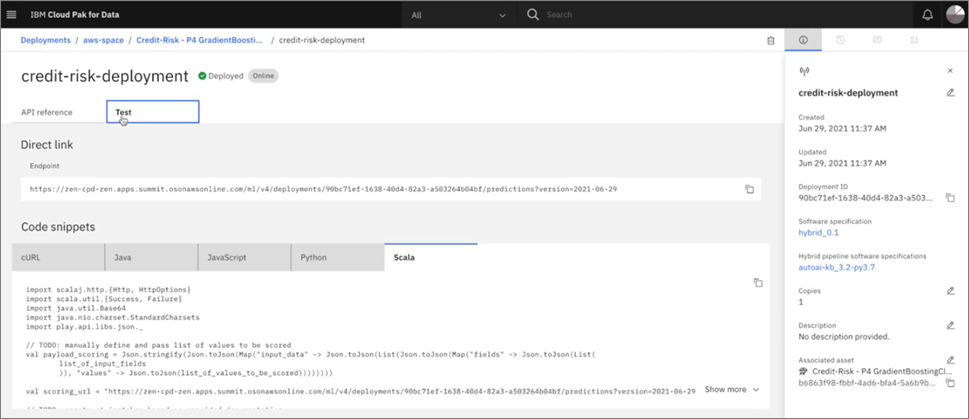
Figure 4 – Sample code in popular languages.
Conclusion
IBM and AWS have provided a unified way to acquire and deploy IBM Cloud Pak for Data using Red Hat OpenShift. This solution enables your organization to simplify and automate how it collects, organizes, and analyzes data using AI and machine learning technologies.
Additionally, IBM Cloud Pak for Data users can use this same mechanism to purchase and deploy the optional additional software, known as cartridges, to their IBM Cloud Pak installation using the same selection and billing model.
Customers can spend more time using their system and less time managing multiple payment and licensing environments.
To get started, download IBM Cloud Pak for Data on AWS Marketplace.
.

.
IBM – AWS Partner Spotlight
IBM is an AWS Partner that provides advanced cloud technologies and the deep industry expertise of IBM services and solutions professionals and consultants.
Contact IBM | Partner Overview | AWS Marketplace
*Already worked with IBM? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.