AWS Partner Network (APN) Blog
Training Multiple Machine Learning Models Simultaneously Using Spark and Apache Arrow
By Itzik Jan, Sr. Software Developer at Perion Network
By Avi Ben Yossef, Head of AI Team at Perion Network
 |
 |
When working on event-level advertising data, you can easily find yourself dealing with billions of daily events.
Python’s classic data and machine learning (ML) libraries—Pandas, Scikit-learn, XGBoost, and others—were not built for such volumes. This means you may face painful tradeoffs, such as extreme sampling or giving up on important features.
In this post, we’ll focus on a use case of distributing multiple models with Pandas, Scikit-learn, PyArrow, and PySpark to improve the model training and testing performance, as well as the accuracy metrics that are relevant to business goals.
At Perion Network, an AWS Partner Network (APN) Select Technology Partner, we are managing and matching supply to demand in the world of internet and mobile advertisement.
Perion’s artificial intelligence (AI) team provides real-time performance optimization services, recommendation systems, and supply/demand forecasting tools. All of this can help customers manage the complex ML modeling process involved in parsing through advertising data.
Background
Our use case is around building a machine learning model pipeline based on billions of records in order to predict and optimize the click-through rate (CTR) and video completion rate (VCR) in our ad delivery engine. We used PySpark for data preparation and Scikit-learn for fitting the ML algorithms.
At the first model training iteration, we got low accuracy and low area under the curve (AUC). It took a long time to train, and had a large footprint. Moreover, when we tried to deploy to production as an experiment, we got poor performance on advertisement products that suffer from low amounts of log data.
After analyzing the history log, which includes data on each advertisement product, we saw that every product behaved in a different manner with huge differences in amount of rows andimpressions and performance events, such as clicks or video completions.
We tried different types of unbalanced data strategies for handling the differences in number of events for every advertisement product. We saw an improvement in accuracy, but not as expected.
Finally, we concluded the model’s performance could be improved by breaking the data into smaller datasets (each dataset has single advertisement product value). From there, we could train each dataset independently to create a model for each advertisement product as unbalanced data handling strategy.
Instead of generating one model, we calculated multiple models—one for each advertisement product. Fortunately, each new model had a higher AUC than the original model, which was ~0.63. The new models ranged between 0.8-0.9.
The following raised new problems:
- The creation and deployment of all models simultaneously ran more than six hours. This alone can cause a scenario that once a model was ready and deployed it was already obsolete.
- We used Scikit-learn as our main framework for training, but it’s not built for distributed execution. We couldn’t utilize the model training and testing parts on Amazon EMR working nodes. The training was in the master node, and worker nodes were in starvation. We had to create the models on a single instance in a serialized manner; one after the other.
- This approach created a complex pipeline requiring additional new management resources. Allocation of resources for multi-models training on Amazon Elastic Compute Cloud (Amazon EC2) instances can increase cost and maintenance.
For solving the above, we started to examine advance type of technologies.
Apache Arrow
Spark 2.3+ supports an integration with Apache Arrow, a cross-language development platform for columnar in-memory data. Apache Spark is a JVM language (written in Scala), but our code is based on Python only.
When using Spark SQL, there is no noticeable difference in performance between two languages. However, problems start when you make a lot of serializations between JVM and Python interpreter, such as writing user-defined functions (UDF) or collecting data locally (using the method toPandas, for example).
It’s worth noting that writing UDFs can be a powerful utility for making operations on a single row, but it has the weakness of not being able to be optimized by the Spark catalyst optimizer.
At a high level, Apache Arrow has the following benefits:
In-Memory Data
Apache Arrow is a common platform for in-memory data. The image in Figure 1 from Apache Arrow illustrates that once using Arrow memory format, you can use it as a connector between different technologies, such as Apache Spark, Pandas, and Apache Parquet.

Figure 1 – Serialization and deserialization between different technologies happens only once.
Columnar Memory
Being columnar in memory, Apache Arrow manages memory more efficiently than row storage and takes advantage of modern CPU and GPU. The image in Figure 2 illustrates a row versus column memory in RAM (the columnar memory has advantages for analytics functions).
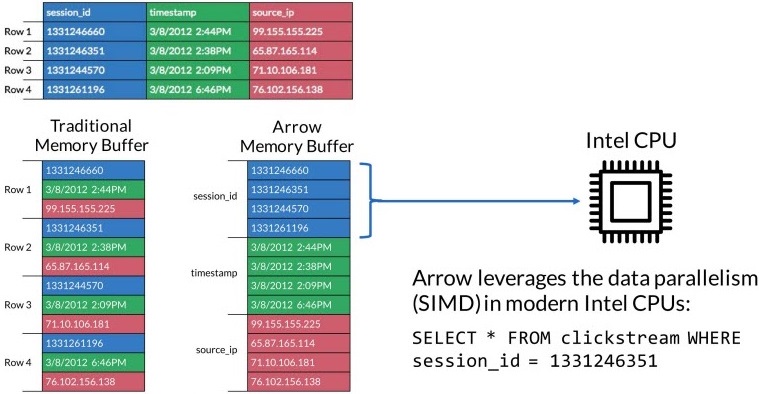
Figure 2 – Memory management in the CPU.
Installing and enabling Apache Arrow in a PySpark project makes an improvement when converting Pyspark DataFrame to Pandas DataFrame.
Doing so also supports two types of vectorized udf(s) named pandas_udf:
- Scalar Pandas UDFs gets input as
pandas.Seriesand returns aspandas.Series. - Grouped Map Pandas UDFs split a Spark DataFrame into groups based on the conditions specified in the group by operator, applies a UDF (pandas.DataFrame > pandas.DataFrame) to each group, combines and returns the results as a new Spark DataFrame.
Our Solution
We wanted to fit and test multiple models simultaneously based on one of the features for optimizing the performance of our ads in the network (CTR and VCR). In our toolset, we had Apache Spark on Amazon EMR as our computation engine.
We can split the fit of the model for two Spark submits:
- Data preparation for fitting the model: We can use Spark SQL for preparing the data, selecting features, and making a sample. As mentioned, we’d like to fit a model for each value of the features (this feature has six values). That way, we can handle # models * 10M sample data in much more optimized and efficient way.
.
The created sample is partitioned per each value and saved to Amazon Simple Storage Service (Amazon S3) as Parquet. Each sample value of the feature should have the same size and we prevent skewness of this feature.
.
Code example:https://gist.github.com/ijan10/d7b11d6906e1b87bedd339b0cc04146f
.
In this code example, we created a dataframe of samples that being partitioned by one of the features.
. - Training the models distributed: Reading the partitioned data from Amazon S3, group by the split feature and apply to Grouped Map Pandas UDFs.
.
Code example of the main function: https://gist.github.com/ijan10/e14b013819ad2536b30097054dfdcdaa
.
Each Pandads UDF gets Pandas DataFrame input of all the feature value samples. Spark partition is not split between executors, and each Spark partition contains all sample data for creating the model.
.
We configure that each executor running Pandas UDF has in its scope a Pandas DataFrame and can prepare features, fit a model (Scikit-learn), prepare it to serve using PMML, cross validate, and save its output to Amazon S3.
.
To learn more, check out our pandas_udf_ctr_create_model.py in GitHub.
We also needed the post validation to be done in a distributed manner just like the model train, so we used the same architecture on data that was created after the deployments of the models (each model tests run in Pandas UDF).
To summarize, we created a generic and simple solution we can configure to train and test a model per combination of attributes and to support many models in parallel without code changes.
Our Amazon EMR Cluster
We are using maximum batches of 10M records for each partition, using EMR Instance Fleets cluster with the following hardware:
- Master – types of 4xlarge (r4.4xlarge, i3.4xlarge, r5.4xlarge and co.)
- 4 core instances of types of 4xlarge (r4.4xlarge, i3.4xlarge, r5.4xlarge and co.)
For the Pandas UDF, we want the maximum executors we can get, because in each executor we are fitting at least one model with batch of 10M records (Pandas and Scikit-learn). To learn more, check out our Spark submit in GitHub.
The 4xlarge instance usually has ~122GB memory and 16 vCpu, so based on the above Spark submit, we are creating one executor in each instance (110 GB total Ram Memory and 14 vCPU).
Summary
Spark is a distributed computing framework that added new features like Pandas UDF by using PyArrow. We can leverage Spark for distributed and advanced machine learning model lifecycle capabilities to build massive-scale products with a bunch of models in production.
In this post, we shared a way to implement a model lifecycle capability to distribute the training and testing stages with few lines of PySpark code. We improved the performance and accuracy of our ML models by using this capability.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Perion Network – APN Partner Spotlight
Perion Network is an APN Select Technology Partner. Its AI team provides real-time performance optimization services, recommendation systems, and supply/demand forecasting tools.
Contact Perion Network | Solution Overview
*Already worked with Perion Network? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.