AWS News Blog
AWS Batch – Run Batch Computing Jobs on AWS
I entered college in the fall of 1978. The Computer Science department at Montgomery College was built around a powerful (for its time) IBM 370/168 mainframe. I quickly learned how to use the keypunch machine to prepare my card decks, prefacing the actual code with some cryptic Job Control Language (JCL) statements that set the job’s name & priority, and then invoked the FORTRAN, COBOL, or PL/I compiler. I would take the deck to the submission window, hand it to the operator in exchange for a job identifier, and then come back several hours later to collect the printed output and the card deck. I studied that printed output with care, and was always shocked to find that after my jobs spent several hours waiting for its turn to run, the actual run time was just a few seconds. As my fellow students and I quickly learned, jobs launched by the school’s IT department ran at priority 4 while ours ran at 8; their jobs took precedence over ours. The goal of the entire priority mechanism was to keep the expensive hardware fully occupied whenever possible. Student productivity was assuredly secondary to efficient use of resources.
Batch Computing Today
Today, batch computing remains important! Easier access to compute power has made movie studios, scientists, researchers, numerical analysts, and others with an insatiable appetite for compute cycles hungrier than ever. Many organizations have attempted to feed these needs by building in-house compute clusters powered by open source or commercial job schedulers. Once again, priorities come in to play and there never seems to be enough compute power to go around. Clusters are expensive to build and to maintain, and are often comprised of a large array of identical, undifferentiated processors, all of the same vintage and built to the same specifications.
We believe that cloud computing has the potential to change the batch computing model for the better, with fast access to many different types of EC2 instances, the ability to scale up and down in response to changing needs, and a pricing model that allows you to bid for capacity and to obtain it as economically as possible. In the past, many AWS customers have built their own batch processing systems using EC2 instances, containers, notifications, CloudWatch monitoring, and so forth. This turned out to be a very common AWS use case and we decided to make it even easier to achieve.
Introducing AWS Batch
Today I would like to tell you about a new set of fully-managed batch capabilities. AWS Batch allows batch administrators, developers, and users to have access to the power of the cloud without having to provision, manage, monitor, or maintain clusters. There’s nothing to buy and no software to install. AWS Batch takes care of the undifferentiated heavy lifting and allows you to run your container images and applications on a dynamically scaled set of EC2 instances. It is efficient, easy to use, and designed for the cloud, with the ability to run massively parallel jobs that take advantage of the elasticity and selection provided by Amazon EC2 and EC2 Spot and can easily and securely interact with other other AWS services such as Amazon S3, DynamoDB, and SNS.
Let’s start by taking a look at some important AWS Batch terms and concepts (if you are already doing batch computing, many of these terms will be familiar to you, and still apply). Here goes:
Job – A unit of work (a shell script, a Linux executable, or a container image) that you submit to AWS Batch. It has a name, and runs as a containerized app on EC2 using parameters that you specify in a Job Definition. Jobs can reference other jobs by name or by ID, and can be dependent on the successful completion of other jobs.
Job Definition – Specifies how Jobs are to be run. Includes an AWS Identity and Access Management (IAM) role to provide access to AWS resources, and also specifies both memory and CPU requirements. The definition can also control container properties, environment variables, and mount points. Many of the specifications in a Job Definition can be overridden by specifying new values when submitting individual Jobs.
Job Queue – Where Jobs reside until scheduled onto a Compute Environment. A priority value is associated with each queue.
Scheduler – Attached to a Job Queue, a Scheduler decides when, where, and how to run Jobs that have been submitted to a Job Queue. The AWS Batch Scheduler is FIFO-based, and is aware of dependencies between jobs. It enforces priorities, and runs jobs from higher-priority queues in preference to lower-priority ones when the queues share a common Compute Environment. The Scheduler also ensures that the jobs are run in a Compute Environment of an appropriate size.
Compute Environment – A set of managed or unmanaged compute resources that are used to run jobs. Managed environments allow you to specify desired instance types at several levels of detail. You can set up Compute Environments that use a particular type of instance, a particular model such as c4.2xlarge or m4.10xlarge, or simply specify that you want to use the newest instance types. You can also specify the minimum, desired, and maximum number of vCPUs for the environment, along with a percentage value for bids on the Spot Market and a target set of VPC subnets. Given these parameters and constraints, AWS Batch will efficiently launch, manage, and terminate EC2 instances as needed. You can also launch your own Compute Environments. In this case you are responsible for setting up and scaling the instances in an Amazon Elastic Container Service (Amazon ECS) cluster that AWS Batch will create for you.
A Quick Tour
You can access AWS Batch from the AWS Management Console, AWS Command Line Interface (AWS CLI), or via the AWS Batch APIs. Let’s take a quick console tour!
The Status Dashboard displays my Jobs, Job Queues, and Compute Environments:
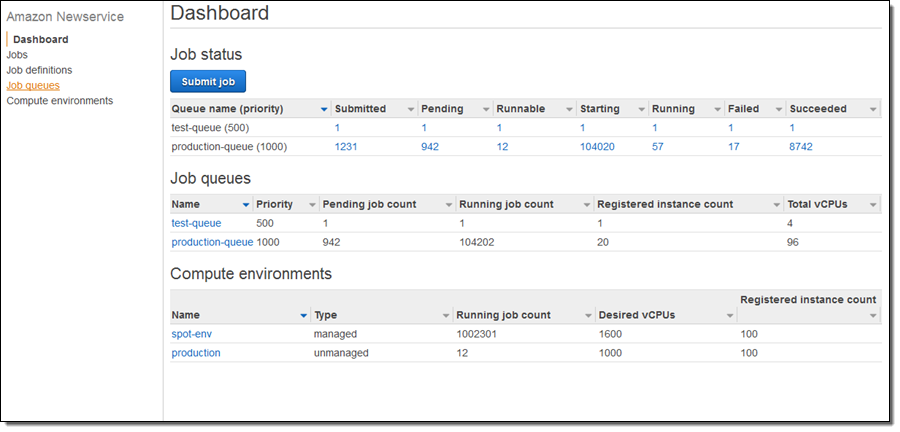
I need a place to run my Jobs, so I will start by selecting Compute environments and clicking on Create environment. I begin by choosing to create a Managed environment, give it a name, and choosing the IAM roles (these were created automatically for me):
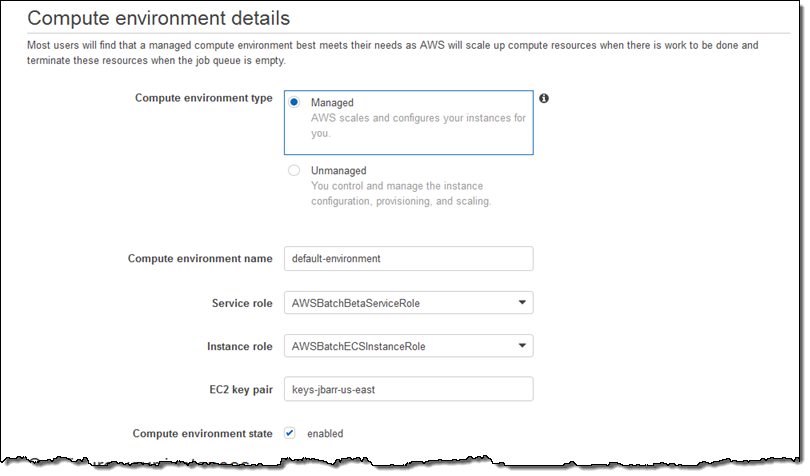
Then I set up the provisioning model (On-Demand or Spot), choose the desired instance families (or specific types), and set the size of my Compute Environment (measured in vCPUs):
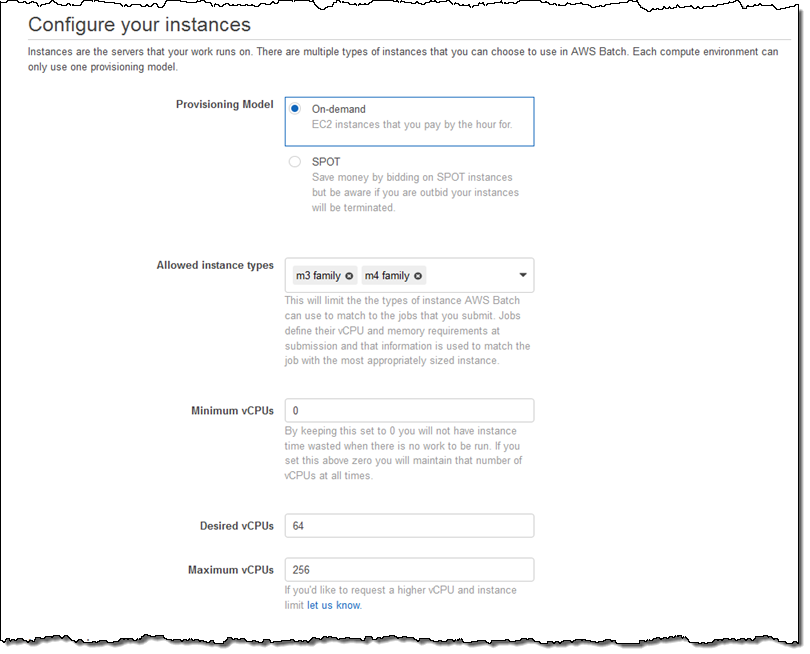
I wrap up by choosing my VPC, the desired subnets for compute resources, and the security group that will be associated with those resources:
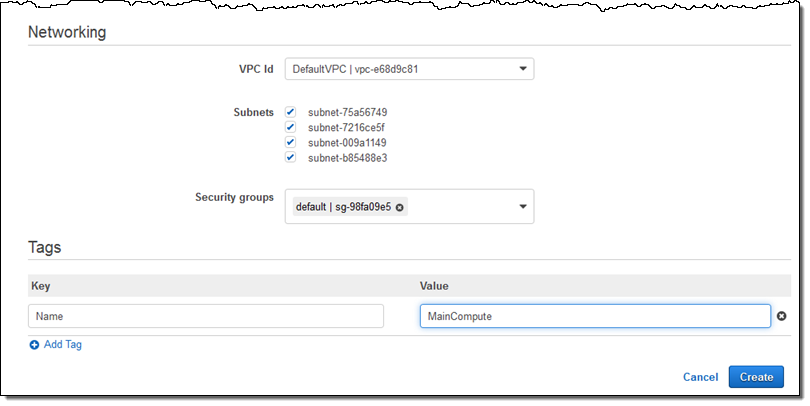
I click on Create and my first Compute Environment (MainCompute) is ready within seconds:
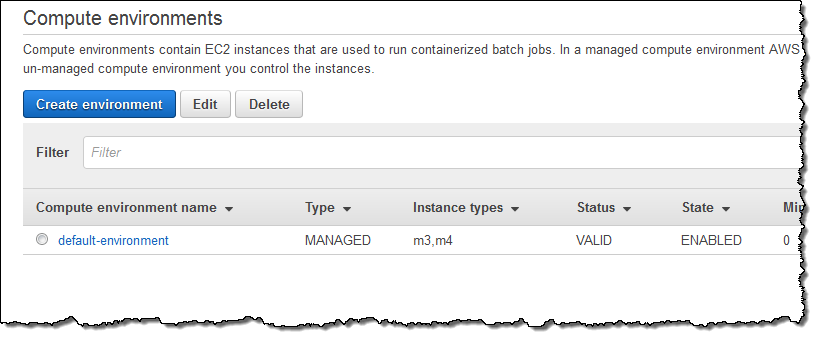
Next, I need a Job Queue to feed work to my Compute Environment. I select Queues and click on Create Queue to set this up. I accept all of the defaults, connect the Job Queue to my new Compute Environment, and click on Create queue:
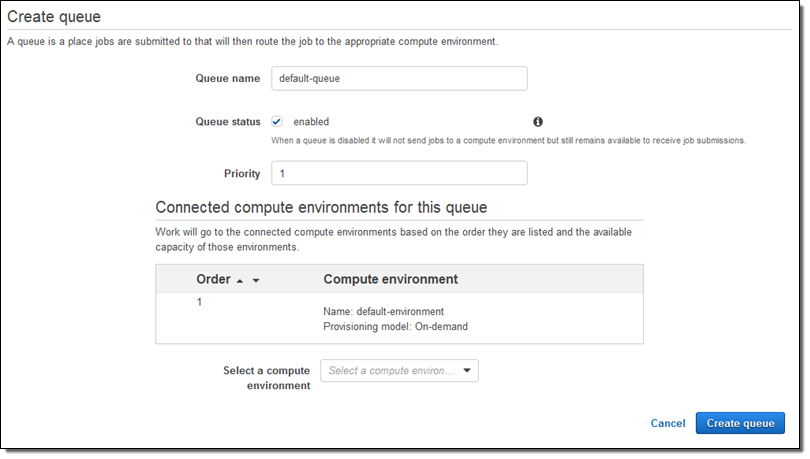
Again, it is available within seconds:
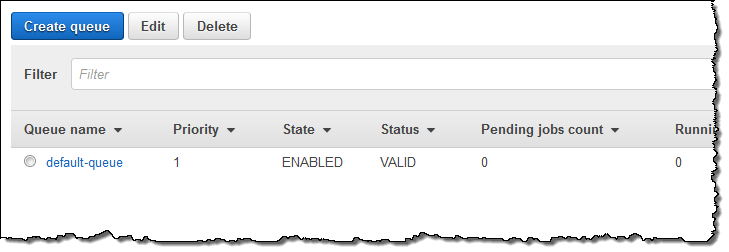
Now I can set up a Job Definition. I select Job definitions and click on Create, then set up my definition (this is a very simple job; I am sure you can do better). My job runs the sleep command, needs 1 vCPU, and fits into 128 MB of memory:
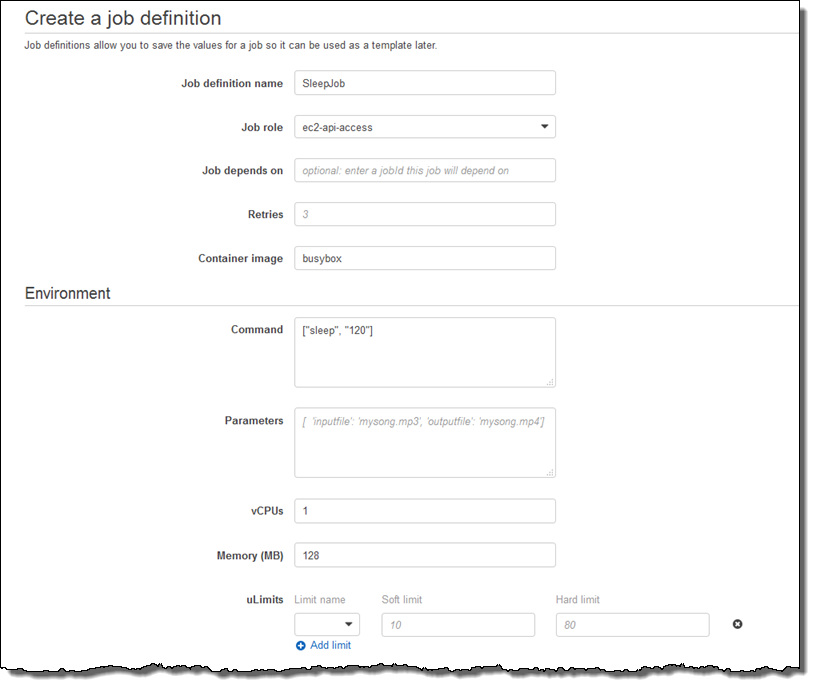
I can also pass in environment variables, disable privileged access, specify the user name for the process, and arrange to make file systems available within the container:
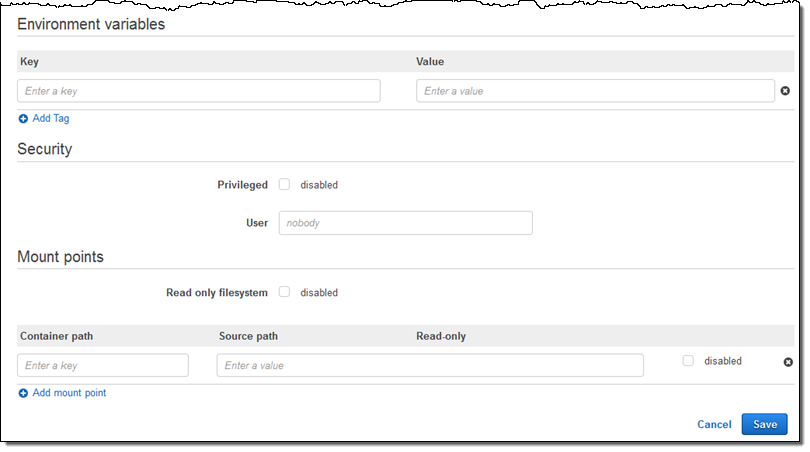
I click on Save and my Job Definition is ready to go:
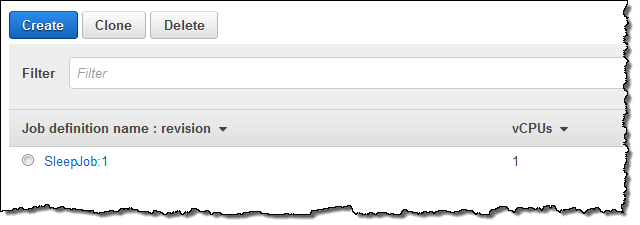
Now I am ready to run my first Job! I select Jobs and click on Submit job:
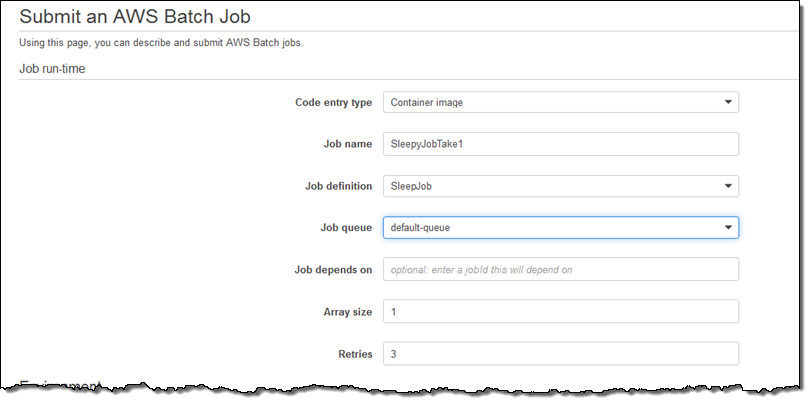
I can also override many aspect of the job, add additional tags, and so forth. I’ll everything as-is and click on Submit:
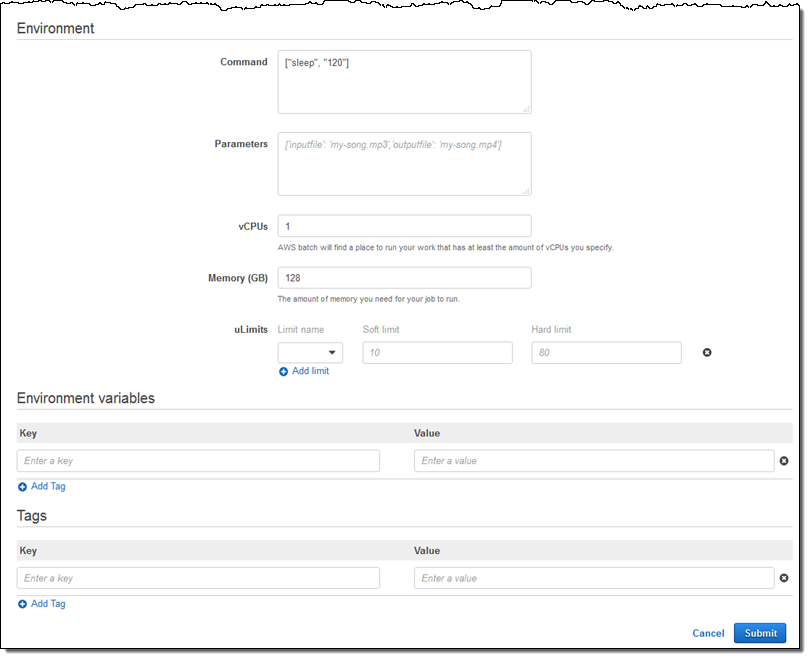
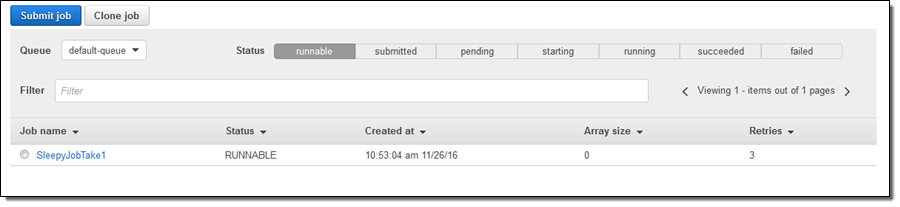
And there it is:
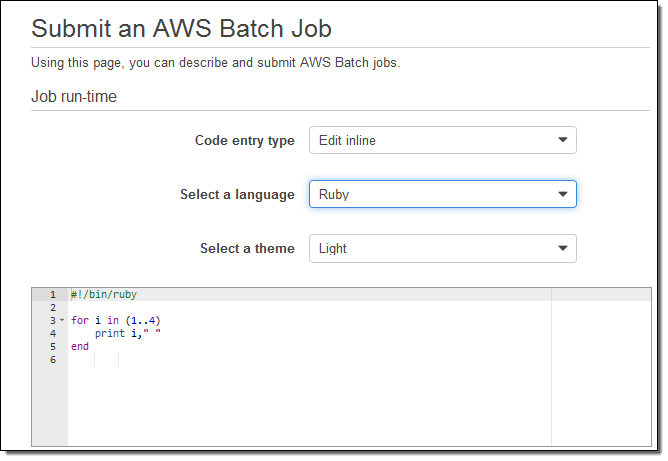
I can also submit jobs by specifying the Ruby, Python, Node, or Bash script that implements the job. For example:
The command line equivalents to the operations that I used in the console include create-compute-environment, describe-compute-environments, create-job-queue, describe-job-queues, register-job-definition, submit-job, list-jobs, and describe-jobs.
I expect to see the AWS Batch APIs used in some interesting ways. For example, imagine a Lambda function that is invoked when a new object (a digital X-Ray, a batch of seismic observations, or a 3D scene description) is uploaded to an S3 bucket. The function can examine the object, extract some metadata, and then use the SubmitJob function to submit one or more Jobs to process the data, with updated data stored in Amazon DynamoDB and notifications sent to Amazon Simple Notification Service (Amazon SNS) along the way.
Pricing & Availability
AWS Batch is in Preview today in the US East (N. Virginia) Region. In addition to regional expansion, we have many other interesting features on the near-term AWS Batch roadmap. For example, you will be able to use an AWS Lambda function as a Job.
There’s no charge for the use of AWS Batch; you pay only for the underlying AWS resources that you consume.
If you’d like to learn more we have a webinar coming December 12th. Register here.
— Jeff;