AWS Big Data Blog
Automate data lineage on Amazon MWAA with OpenLineage
In modern data architectures, datasets are combined across an organization using a variety of purpose-built services to unlock insights. As a result, data governance becomes a key component for data consumers and producers to know that their data-driven decisions are based on trusted and accurate datasets. One aspect of data governance is data lineage, which captures the flow of data as it goes through various systems and allows consumers to understand how a dataset was derived.
In order to capture data lineage consistently across various analytical services, you need to use a common lineage model and a robust job orchestration that is able to tie together diverse data flows. One possible solution is the open-source OpenLineage project. It provides a technology-agnostic metadata model for capturing data lineage and integrates with widely used tools. For job orchestration, it integrates with Apache Airflow, which you can run on AWS conveniently through the managed service Amazon Managed Workflows for Apache Airflow (Amazon MWAA). OpenLineage provides a plugin for Apache Airflow that extracts data lineage from Directed Acyclic Graphs (DAGs).
In this post, we show how to get started with data lineage on AWS using OpenLineage. We provide a step-by-step configuration guide for the openlineage-airflow plugin on Amazon MWAA. Additionally, we share an AWS Cloud Development Kit (AWS CDK) project that deploys a pre-configured demo environment for evaluating and experiencing OpenLineage first-hand.
OpenLineage on Apache Airflow
In the following example, Airflow turns OLTP data into a star schema on Amazon Redshift Serverless.
After staging and preparing source data from Amazon Simple Storage Service (Amazon S3), fact and dimension tables are eventually created. For this, Airflow orchestrates the execution of SQL statements that create and populate tables on Redshift Serverless.

The openlineage-airflow plugin collects metadata about creation of datasets and dependencies between them. This allows us to move from a jobs-centric approach of Airflow to a datasets-centric approach, improving the observability of workflows.
The following screenshot shows parts of the captured lineage for the previous example. It’s displayed in Marquez, an open-source metadata service for collection and visualization of data lineage with support for the OpenLineage standard. In Marquez, you can analyze the upstream datasets and transformations that eventually create the user dimension table on the right.

The example in this post is based on SQL and Amazon Redshift. OpenLineage also supports other transformation engines and data stores such as Apache Spark and dbt.
Solution overview
The following diagram shows the AWS setup required to capture data lineage using OpenLineage.
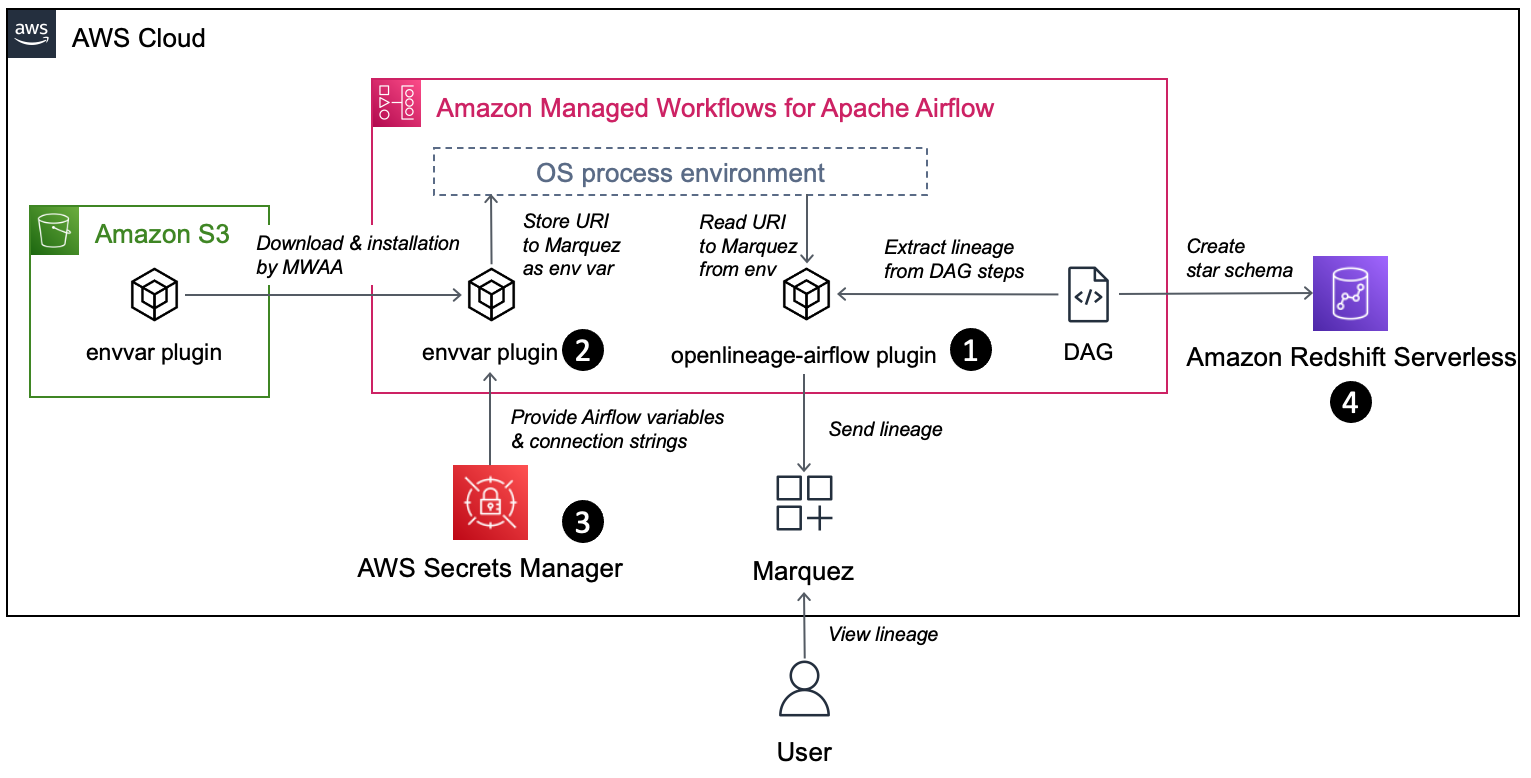
The workflow includes the following components:
- The openlineage-airflow plugin is configured on Airflow as a lineage backend. Metadata about the DAG runs is passed by Airflow core to the plugin, which converts it into OpenLineage format and sends it to an external metadata store. In our demo setup, we use Marquez as the metadata store.
- The openlineage-airflow plugin receives its configuration from environment variables. To populate these variables on Amazon MWAA, a custom Airflow plugin is used. First, the plugin reads source values from AWS Secrets Manager. Then, it creates environment variables.
- Secrets Manager is configured as a secrets backend. Typically, this type of configuration is stored in Airflow’s native metadata database. However, this approach has limitations. For instance, in case of multiple Airflow environments, you need to track and store credentials across multiple environments, and updating credentials requires you to update all the environments. With a secrets backend, you can centralize configuration.
- For demo purposes, we collect data lineage from a data pipeline, which creates a star schema in Redshift Serverless.
In the following sections, we walk you through the steps for end-to-end configuration.
Install the openlineage-airflow plugin
Specify the following dependency in the requirements.txt file of the Amazon MWAA environment. Note that the latest Airflow version currently available on Amazon MWAA is 2.4.3; for this post, use the compatible version 0.19.2 of the plugin:
For more details on installing Python dependencies on Amazon MWAA, refer to Installing Python dependencies.
For Airflow < 2.3, configure the plugin’s lineage backend through the following configuration overrides on the Amazon MWAA environment and load it immediately at Airflow start by disabling lazy load of plugins:
For more information on configuration overrides, refer to Configuration options overview.
Configure the Secrets Manager backend with Amazon MWAA
Using Secrets Manager as a secrets backend for Amazon MWAA is straightforward. First, provide the execution role of Amazon MWAA with read permission to Secrets Manager. You can use the following policy template as a starting point:
Second, configure Secrets Manager as a backend in Amazon MWAA through the following configuration overrides:
For more information configuring a secrets backend in Amazon MWAA, refer to Configuring an Apache Airflow connection using a Secrets Manager secret and Move your Apache Airflow connections and variables to AWS Secrets Manager.
Deploy a custom envvar plugin to Amazon MWAA
Apache Airflow has a built-in plugin manager through which it can be extended with custom functionality. In our case, this functionality is to populate OpenLineage-specific environment variables based on values in Secrets Manager. Natively, Amazon MWAA allows environment variables with the prefix AIRFLOW__, but the openlineage-airflow plugin expects the prefix OPENLINEAGE__.
The following Python code is used in the plugin. We assume the file is called envvar_plugin.py:
Amazon MWAA has a mechanism to install a plugin through a zip archive. You zip your code, upload the archive to an S3 bucket, and pass the URL to the file to Amazon MWAA:
Upload plugins.zip to an S3 bucket and configure the URL in Amazon MWAA. The following screenshot shows the configuration via the Amazon MWAA console.

For more information on installing custom plugins on Amazon MWAA, refer to Creating a custom plugin that generates runtime environment variables.
Configure connectivity between the openlineage-airflow plugin and Marquez
As a last step, store the URL to Marquez in Secrets Manager. For this, create a secret called airflow/variables/OPENLINEAGE_URL with value <protocol>://<hostname/ip>:<port> (for example, https://marquez.mysite.com:5000).

In case you need to spin up Marquez on AWS, you have multiple options to host, including running it on Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon Elastic Compute Cloud (Amazon EC2). Refer to Running Marquez on AWS or check out our infrastructure template in the next section to deploy Marquez on AWS.
Deploy with an AWS CDK-based solution template
Assuming you want to set up a demo infrastructure for all of the above in one step, you can use the following template based on the AWS CDK.
The template has the following prerequisites:
- An AWS account.
- Amazon Linux 2 with AWS CDK, Docker CLI, and Python3 installed. Alternatively, setting up an AWS Cloud9 environment will satisfy this requirement.
Complete the following steps to deploy the template:
- Clone GitHub repository and install Python dependencies. Bootstrap the AWS CDK if required.
- Update the value for the variable
EXTERNAL_IPinconstants.pyto your outbound IP for connecting to the internet:This configures security groups so that you can access Marquez but block other clients.
constants.pyis found in the root folder of the cloned repository. - Deploy the VPC_S3 stack to provision a new VPC dedicated for this solution as well as the security groups that are used by the different components:
It creates a new S3 bucket and uploads the source raw data based on the TICKIT sample database. This serves as the landing area from the OLTP database. We then need to parse the metadata of these files through an AWS Glue crawler, which facilitates the native integration between Amazon Redshift and the S3 data lake.
- Deploy the lineage stack to create an EC2 instance that hosts Marquez:
Access the Marquez web UI through
https://{ec2.public_dns_name}:3000/. This URL is also available as part of the AWS CDK outputs for the lineage stack. - Deploy the Amazon Redshift stack to create a Redshift Serverless endpoint:
- Deploy the Amazon MWAA stack to create an Amazon MWAA environment:
You can access the Amazon MWAA UI through the URL provided in the AWS CDK output.
Test a sample data pipeline
On Amazon MWAA, you can see an example data pipeline deployed that consists of two DAGs. It builds a star schema on top of the TICKIT sample database. One DAG is responsible for loading data from the S3 data lake into an Amazon Redshift staging layer; the second DAG loads data from the staging layer to the dimensional model.

Open the Amazon MWAA UI through the URL obtained in the deployment steps and launch the following DAGs: rs_source_to_staging and rs_staging_to_dm. As part of the run, the lineage metadata is sent to Marquez.
After the DAG has been run, open the Marquez URL obtained in the deployment steps. In Marquez, you can find the lineage metadata for the computed star schema and related data assets on Amazon Redshift.
Clean up
Delete the AWS CDK stacks to avoid ongoing charges for the resources that you created. Run the following command in the aws-mwaa-openlineage project directory so that all resources are undeployed:
Summary
In this post, we showed you how to automate data lineage with OpenLineage on Amazon MWAA. As part of this, we covered how to install and configure the openlineage-airflow plugin on Amazon MWAA. Additionally, we provided a ready-to-use infrastructure template for a complete demo environment.
We encourage you to explore what else can be achieved with OpenLineage. A job orchestrator like Apache Airflow is only one piece of a data platform and not all possible data lineage can be captured on it. We recommend exploring OpenLineage’s integration with other platforms like Apache Spark or dbt. For more information, refer to Integrations.
Additionally, we recommend you visit the AWS Big Data Blog for other useful blog posts on Amazon MWAA and data governance on AWS.
About the Authors
 Stephen Said is a Senior Solutions Architect and works with Digital Native Businesses. His areas of interest are data analytics, data platforms and cloud-native software engineering.
Stephen Said is a Senior Solutions Architect and works with Digital Native Businesses. His areas of interest are data analytics, data platforms and cloud-native software engineering.
 Vishwanatha Nayak is a Senior Solutions Architect at AWS. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable modern data platforms using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.
Vishwanatha Nayak is a Senior Solutions Architect at AWS. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable modern data platforms using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.
 Paul Villena is an Analytics Solutions Architect with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure-as-code, serverless technologies and coding in Python.
Paul Villena is an Analytics Solutions Architect with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure-as-code, serverless technologies and coding in Python.