AWS Big Data Blog
Create Tables in Amazon Athena from Nested JSON and Mappings Using JSONSerDe
July 2024: This post was reviewed and updated for accuracy.
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
Most systems use Java Script Object Notation (JSON) to log event information. Although it’s efficient and flexible, deriving information from JSON is difficult.
In this post, you will use the tightly coupled integration of Amazon Data Firehose for log delivery, Amazon S3 for log storage, and Amazon Athena with JSONSerDe to run SQL queries against these logs without the need for data transformation or insertion into a database. It’s done in a completely serverless way. There’s no need to provision any compute.
Amazon SES provides highly detailed logs for every message that travels through the service and, with SES event publishing, makes them available through Firehose. However, parsing detailed logs for trends or compliance data would require a significant investment in infrastructure and development time. Athena is a boon to these data seekers because it can query this dataset at rest, in its native format, with zero code or architecture. On top of that, it uses largely native SQL queries and syntax.
Walkthrough: Establishing a dataset
We start with a dataset of an SES send event that looks like this:
This dataset contains a lot of valuable information about this SES interaction. There are thousands of datasets in the same format to parse for insights. Getting this data is straightforward.
1. Create a configuration set in the SES console or CLI that uses a Firehose delivery stream to send and store logs in S3 in near real-time.
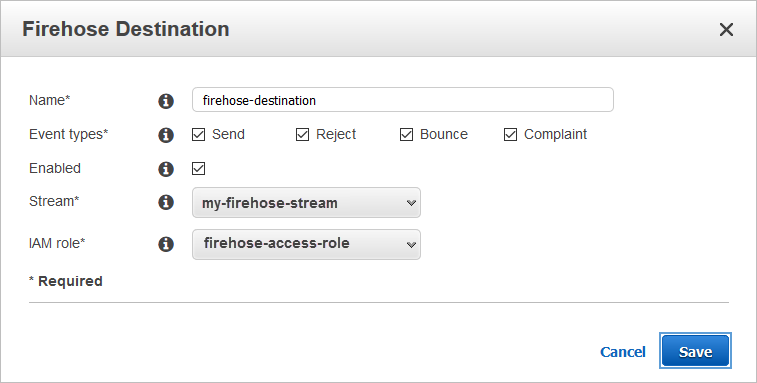
2. Use SES to send a few test emails. Be sure to define your new configuration set during the send.
To do this, when you create your message in the SES console, choose More options. This will display more fields, including one for Configuration Set.
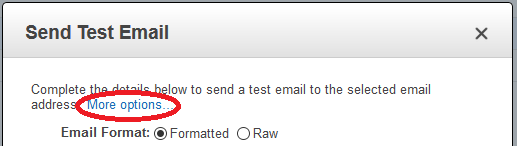
You can also use your SES verified identity and the AWS CLI to send messages to the mailbox simulator addresses.
3. Select your S3 bucket to see that logs are being created.
![]()
Walkthrough: Querying with Athena
Amazon Athena is an interactive query service that makes it easy to use standard SQL to analyze data resting in Amazon S3. Athena requires no servers, so there is no infrastructure to manage. You pay only for the queries you run. This makes it perfect for a variety of standard data formats, including CSV, JSON, ORC, and Parquet.
You now need to supply Athena with information about your data and define the schema for your logs with a Hive-compliant DDL statement. Athena uses Presto, a distributed SQL engine, to run queries. It also uses Apache Hive DDL syntax to create, drop, and alter tables and partitions. Athena uses an approach known as schema-on-read, which allows you to use this schema at the time you execute the query. Essentially, you are going to be creating a mapping for each field in the log to a corresponding column in your results.
If you are familiar with Apache Hive, you might find creating tables on Athena to be pretty similar. You can create tables by writing the DDL statement in the query editor or by using the wizard or JDBC driver. An important part of this table creation is the SerDe, a short name for “Serializer and Deserializer.” Because your data is in JSON format, you will be using org.openx.data.jsonserde.JsonSerDe, natively supported by Athena, to help you parse the data. Along the way, you will address two common problems with Hive/Presto and JSON datasets:
- Nested or multi-level JSON.
- Forbidden characters (handled with mappings).
In the Athena Query Editor, use the following DDL statement to create your first Athena table. For LOCATION, use the path to the S3 bucket for your logs:
In this DDL statement, you are declaring each of the fields in the JSON dataset along with its Presto data type. You are using Hive collection data types like Array and Struct to set up groups of objects.
Walkthrough: Nested JSON
Defining the mail key is interesting because the JSON inside is nested three levels deep. In the example, you are creating a top-level struct called mail which has several other keys nested inside. This includes fields like messageId and destination at the second level. You can also see that the field timestamp is surrounded by the backtick (`) character. timestamp is also a reserved Presto data type so you should use backticks here to allow the creation of a column of the same name without confusing the table creation command. On the third level is the data for headers. It contains a group of entries in name:value pairs. You define this as an array with the structure of <name:string,value:string> defining your schema expectations here. You must enclose `from` in the commonHeaders struct with backticks to allow this reserved word column creation.
Now that you have created your table, you can fire off some queries!
This output shows your two top-level columns (eventType and mail) but this isn’t useful except to tell you there is data being queried. You can use some nested notation to build more relevant queries to target data you care about.
“Which messages did I bounce from Monday’s campaign?”
“How many messages have I bounced to a specific domain?”
“Which messages did I bounce to the domain amazonses.com?”
There are much deeper queries that can be written from this dataset to find the data relevant to your use case. You might have noticed that your table creation did not specify a schema for the tags section of the JSON event. You’ll do that next.
Walkthrough: Handling forbidden characters with mappings
Here is a major roadblock you might encounter during the initial creation of the DDL to handle this dataset: you have little control over the data format provided in the logs and Hive uses the colon (:) character for the very important job of defining data types. You need to give the JSONSerDe a way to parse these key fields in the tags section of your event. This is some of the most crucial data in an auditing and security use case because it can help you determine who was responsible for a message creation.
In the Athena query editor, use the following DDL statement to create your second Athena table. For LOCATION, use the path to the S3 bucket for your logs:
In your new table creation, you have added a section for SERDEPROPERTIES. This allows you to give the SerDe some additional information about your dataset. For your dataset, you are using the mapping property to work around your data containing a column name with a colon smack in the middle of it. ses:configuration-set would be interpreted as a column named ses with the datatype of configuration-set. Unlike your earlier implementation, you can’t surround an operator like that with backticks. The JSON SERDEPROPERTIES mapping section allows you to account for any illegal characters in your data by remapping the fields during the table’s creation.
For example, you have simply defined that the column in the ses data known as ses:configuration-set will now be known to Athena and your queries as ses_configurationset. This mapping doesn’t do anything to the source data in S3. This is a Hive concept only. It won’t alter your existing data. You have set up mappings in the Properties section for the four fields in your dataset (changing all instances of colon to the better-supported underscore) and in your table creation you have used those new mapping names in the creation of the tags struct.
Now that you have access to these additional authentication and auditing fields, your queries can answer some more questions.
“Who is creating all of these bounced messages?”
Of special note here is the handling of the column mail.commonHeaders.”from”. Because from is a reserved operational word in Presto, surround it in quotation marks (“) to keep it from being interpreted as an action.
Walkthrough: Querying using SES custom tagging
What makes this mail.tags section so special is that SES will let you add your own custom tags to your outbound messages. Now you can label messages with tags that are important to you, and use Athena to report on those tags. For example, if you wanted to add a Campaign tag to track a marketing campaign, you could use the –tags flag to send a message from the SES CLI:
This results in a new entry in your dataset that includes your custom tag.
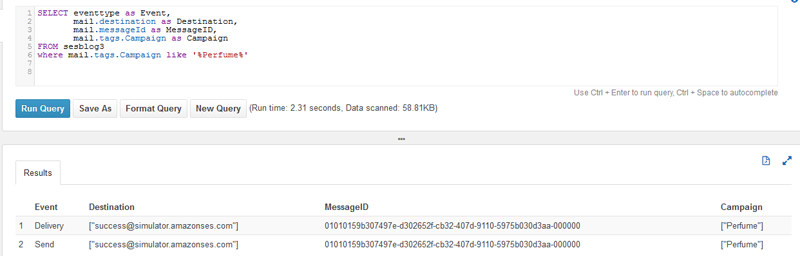
You can then create a third table to account for the Campaign tagging.
Then you can use this custom value to begin to query which you can define on each outbound email.
Walkthrough: Building your own DDL programmatically with hive-json-schema
In all of these examples, your table creation statements were based on a single SES interaction type, send. SES has other interaction types like delivery, complaint, and bounce, all which have some additional fields. I’ll leave you with this, a DDL that can parse all the different SES eventTypes and can create one table where you can begin querying your data.
Building a properly working JSONSerDe DLL by hand is tedious and a bit error-prone, so this time around you’ll be using an open source tool commonly used by AWS Support. All you have to do manually is set up your mappings for the unsupported SES columns that contain colons.
This sample JSON file contains all possible fields from across the SES eventTypes. It has been run through hive-json-schema, which is a great starting point to build nested JSON DDLs.
Here is the resulting DDL to query all types of SES logs:
Conclusion
In this post, you’ve seen how to use Amazon Athena in real-world use cases to query the JSON used in AWS service logs. Some of these use cases can be operational like bounce and complaint handling. Others report on trends and marketing data like querying deliveries from a campaign. Still others provide audit and security like answering the question, which machine or user is sending all of these messages? You’ve also seen how to handle both nested JSON and SerDe mappings so that you can use your dataset in its native format without making changes to the data to get your queries running.
With the new AWS QuickSight suite of tools, you also now have a data source that that can be used to build dashboards. This makes reporting on this data even easier. For information about using Athena as a QuickSight data source, see this blog post.
There are also optimizations you can make to these tables to increase query performance or to set up partitions to query only the data you need and restrict the amount of data scanned. If you only need to report on data for a finite amount of time, you could optionally set up S3 lifecycle configuration to transition old data to Amazon Glacier or to delete it altogether.
Feel free to leave questions or suggestions in the comments.
About the Author
 Rick Wiggins is a Cloud Support Engineer for AWS Premium Support. He works with our customers to build solutions for Email, Storage and Content Delivery, helping them spend more time on their business and less time on infrastructure. In his spare time, he enjoys traveling the world with his family and volunteering at his children’s school teaching lessons in Computer Science and STEM.
Rick Wiggins is a Cloud Support Engineer for AWS Premium Support. He works with our customers to build solutions for Email, Storage and Content Delivery, helping them spend more time on their business and less time on infrastructure. In his spare time, he enjoys traveling the world with his family and volunteering at his children’s school teaching lessons in Computer Science and STEM.
Audit History
Last reviewed and updated in July 2024 by Harshit Kohli | Technical Account Manager (TAM)