AWS Big Data Blog
Tag: Migration

Ingest data from Google Analytics 4 and Google Sheets to Amazon Redshift using Amazon AppFlow
Amazon AppFlow bridges the gap between Google applications and Amazon Redshift, empowering organizations to unlock deeper insights and drive data-informed decisions. In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup.

Migrate from Apache Solr to OpenSearch
OpenSearch is an open source, distributed search engine suitable for a wide array of use-cases such as ecommerce search, enterprise search (content management search, document search, knowledge management search, and so on), site search, application search, and semantic search. It’s also an analytics suite that you can use to perform interactive log analytics, real-time application […]

How BookMyShow saved 80% in costs by migrating to an AWS modern data architecture
This is a guest post co-authored by Mahesh Vandi Chalil, Chief Technology Officer of BookMyShow. BookMyShow (BMS), a leading entertainment company in India, provides an online ticketing platform for movies, plays, concerts, and sporting events. Selling up to 200 million tickets on an annual run rate basis (pre-COVID) to customers in India, Sri Lanka, Singapore, […]
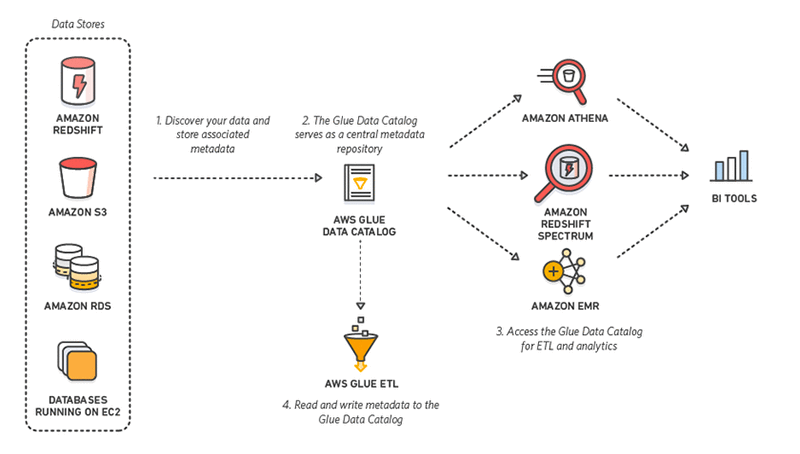
Harmonize, Query, and Visualize Data from Various Providers using AWS Glue, Amazon Athena, and Amazon QuickSight
Have you ever been faced with many different data sources in different formats that need to be analyzed together to drive value and insights? You need to be able to query, analyze, process, and visualize all your data as one canonical dataset, regardless of the data source or original format. In this post, I walk […]

Eight Tips for Using S3DistCp on Amazon EMR to Move Data Efficiently Between HDFS and Amazon S3
Although it’s common for Amazon EMR customers to process data directly in Amazon S3, there are occasions where you might want to copy data from S3 to the Hadoop Distributed File System (HDFS) on your Amazon EMR cluster. Additionally, you might have a use case that requires moving large amounts of data between buckets or regions. In these use cases, large datasets are too big for a simple copy operation.

Tips for Migrating to Apache HBase on Amazon S3 from HDFS
Starting with Amazon EMR 5.2.0, you have the option to run Apache HBase on Amazon S3. Running HBase on S3 gives you several added benefits, including lower costs, data durability, and easier scalability. HBase provides several options that you can use to migrate and back up HBase tables. The steps to migrate to HBase on […]

Near Zero Downtime Migration from MySQL to DynamoDB
Many companies consider migrating from relational databases like MySQL to Amazon DynamoDB, a fully managed, fast, highly scalable, and flexible NoSQL database service. For example, DynamoDB can increase or decrease capacity based on traffic, in accordance with business needs. The total cost of servicing can be optimized more easily than for the typical media-based RDBMS. […]
Create Tables in Amazon Athena from Nested JSON and Mappings Using JSONSerDe
July 2024: This post was reviewed and updated for accuracy. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Most systems use Java Script Object Notation (JSON) to log event information. Although it’s efficient and flexible, deriving information from JSON is […]

Migrate External Table Definitions from a Hive Metastore to Amazon Athena
For customers who use Hive external tables on Amazon EMR, or any flavor of Hadoop, a key challenge is how to effectively migrate an existing Hive metastore to Amazon Athena, an interactive query service that directly analyzes data stored in Amazon S3. With Athena, there are no clusters to manage and tune, and no infrastructure to […]
Converging Data Silos to Amazon Redshift Using AWS DMS
Organizations often grow organically—and so does their data in individual silos. Such systems are often powered by traditional RDBMS systems and they grow orthogonally in size and features. To gain intelligence across heterogeneous data sources, you have to join the data sets. However, this imposes new challenges, as joining data over dblinks or into a […]