AWS Big Data Blog
How SailPoint solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS
This post is co-written with Richard Li from SailPoint.
SailPoint Technologies is an identity security company based in Austin, TX. Its software as a service (SaaS) solutions support identity governance operations in regulated industries such as healthcare, government, and higher education. SailPoint distinguishes multiple aspects of identity as individual identity security services, including cloud governance, SaaS management, access risk governance, file access management, password management, provisioning, recommendations, and separation of duties, as well as access certification, access insights, access modeling, and access requests.
In this post, we share how SailPoint updated its platform for big data operations, and solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS.
The challenge with the legacy data environment
SailPoint acquired a SaaS software platform that processes and analyzes identity, resource, and usage data from multiple cloud providers, and provides access insights, usage analysis, and access risk analysis. The original design criteria of the platform was focused on serving small to medium-sized companies. To quickly process these analytics insights, many of these processing workloads were done inside many microservices through streaming connections.
After acquisition, we set a goal to expand the platform’s capability to handle customers with large cloud footprints over multiple cloud providers, sometime over hundreds or even thousands of accounts producing large amount of cloud event data.
The legacy architecture has a simplistic approach for data processing, as shown in the following diagram. We were processing the vast majority of event data in-service and directly ingested into Amazon Relational Database Service (Amazon RDS), which we then merged with a graph database to form the final view..

We needed to convert this into a scalable process that could handle customers of any size. To address this challenge, we had to quickly introduce a big data processing engine in the platform.
How migrating to Amazon EMR on EKS helped solve this challenge
When evaluating the platform for our big data operations, several factors made Amazon EMR on EKS a top choice.
The amount of event data we receive at any given time is generally unpredictable. To stay cost-effective and efficient, we need a platform that is capable of scaling up automatically when the workload increases to reduce wait time, and can scale down when the capacity is no longer needed to save cost. Because our existing application workloads are already running on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster with the cluster autoscaler enabled, running Amazon EMR on EKS on top of our existing EKS cluster fits this need.
Amazon EMR on EKS can safely coexist on an EKS cluster that is already hosting other workloads, be contained within a specified namespace, and have controlled access through use of Kubernetes role-based access control and AWS Identity and Access Management (IAM) roles for service accounts. Therefore, we didn’t have to build new infrastructures just for Amazon EMR. We simply linked up Amazon EMR on EKS with our existing EKS cluster running our application workloads. This reduced the amount of DevOps support needed, and significantly sped up our implementation and deployment timeline.
Unlike Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2), because our EKS cluster spans over multiple Availability Zones, we can control Spark pods placements using Kubernetes’s pod scheduling and placement strategy to achieve higher fault tolerance.
With the ability to create and use custom images in Amazon EMR on EKS, we could also utilize our existing container-based application build and deployment pipeline for our Amazon EMR on EKS workload without any modifications. This also gave us additional benefit in reducing job startup time because we package all job scripts as well as all dependencies with the image, without having to fetch them at runtime.
We also utilize AWS Step Functions as our core workflow engine. The native integration of Amazon EMR on EKS with Step Functions is another bonus where we didn’t have to build custom code for job dispatch. Instead, we could utilize the Step Functions native integration to seamlessly integrate Amazon EMR jobs with our existing workflow, with very little effort.
In merely 5 months, we were able to go from design, to proof of concept, to rolling out phase 1 of the event analytics processing. This vastly improved our event analytics processing capability by extending horizontal scalability, which gave us the ability to take customers with significantly larger cloud footprints than the legacy platform was designed for.
During the development and rollout of the platform, we also found that the Spark History Server provided by Amazon EMR on EKS was very useful in terms of helping us identify performance issues and tune the performance of our jobs.
As of this writing, the phase 1 rollout, which includes the event processing component of the core analytics processing, is complete. We’re now expanding the platform to migrate additional components onto Amazon EMR on EKS. The following diagram depicts our future architecture with Amazon EMR on EKS when all phases are complete.
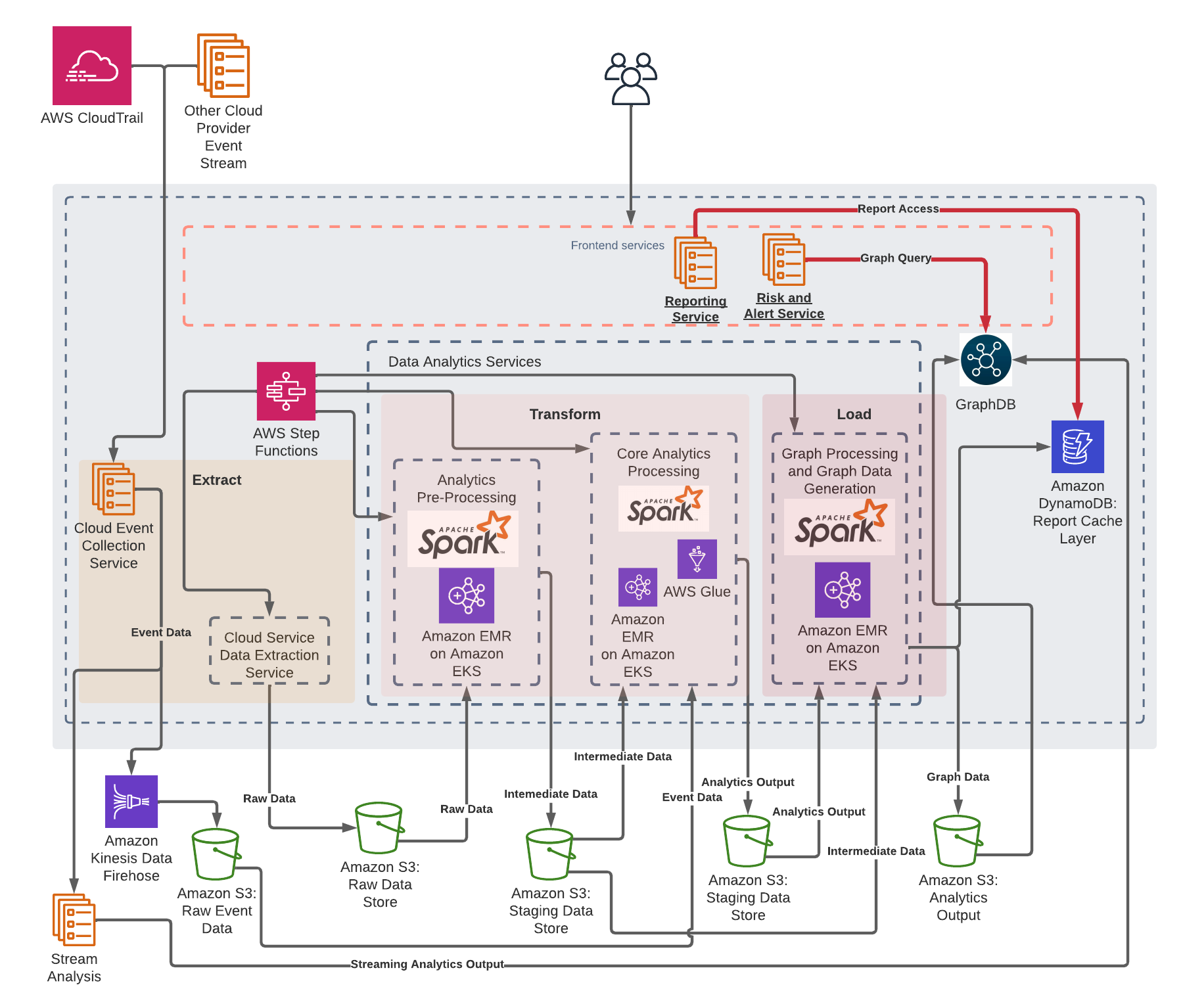
In addition, to improve performances and reduce costs, we’re currently testing the Spark dynamic resource allocation support of Amazon EMR on EKS. This would automatically scale up and down the job executors based on load, and therefore boost performance when needed and reduce cost when the workload is low. Furthermore, we’re investigating the possibility to reduce the overall cost and increase performance by utilizing the pod template feature that would allow us to seamlessly transition our Amazon EMR job workload to AWS Graviton based instances.
Conclusion
With Amazon EMR on EKS, we can now onboard new customers and process vast amounts of data in a cost-effective manner, which we couldn’t do with our legacy environment. We plan to expand our Amazon EMR on EKS footprint to handle all our transform and load data analytics processes.
About the Authors
 Richard Li is a senior staff software engineer on the SailPoint Technologies Cloud Access Management team.
Richard Li is a senior staff software engineer on the SailPoint Technologies Cloud Access Management team.
 Janak Agarwal is a product manager for Amazon EMR on Amazon EKS at AWS.
Janak Agarwal is a product manager for Amazon EMR on Amazon EKS at AWS.
 Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS customers across the globe to strategize, build, develop, and deploy modern data analytics solutions.
Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS customers across the globe to strategize, build, develop, and deploy modern data analytics solutions.