AWS Big Data Blog
Accelerate your data warehouse migration to Amazon Redshift – Part 5
This is the fifth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift.
Check out the all the posts in this series:
|
Amazon Redshift is the leading cloud data warehouse. No other data warehouse makes it as easy to gain new insights from your data. With Amazon Redshift, you can query exabytes of data across your data warehouse, operational data stores, and data lake using standard SQL. You can also integrate other AWS services such as Amazon EMR, Amazon Athena, Amazon SageMaker, AWS Glue, AWS Lake Formation, and Amazon Kinesis to use all the analytic capabilities in the AWS Cloud.
Until now, migrating a data warehouse to AWS has been a complex undertaking, involving a significant amount of manual effort. You need to manually remediate syntax differences, inject code to replace proprietary features, and manually tune the performance of queries and reports on the new platform.
Legacy workloads may rely on non-ANSI, proprietary features that aren’t directly supported by modern databases like Amazon Redshift. For example, many Teradata applications use SET tables, which enforce full row uniqueness—there can’t be two rows in a table that are identical in all of their attribute values.
If you’re an Amazon Redshift user, you may want to implement SET semantics but can’t rely on a native database feature. You can use the design patterns in this post to emulate SET semantics in your SQL code. Alternatively, if you’re migrating a workload to Amazon Redshift, you can use the AWS Schema Conversion Tool (AWS SCT) to automatically apply the design patterns as part of your code conversion.
In this post, we describe the SQL design patterns and analyze their performance, and show how AWS SCT can automate this as part of your data warehouse migration. Let’s start by understanding how SET tables behave in Teradata.
Teradata SET tables
At first glance, a SET table may seem similar to a table that has a primary key defined across all of its columns. However, there are some important semantic differences from traditional primary keys. Consider the following table definition in Teradata:
We populate the table with four rows of data, as follows:
Notice that we didn’t define a UNIQUE PRIMARY INDEX (similar to a primary key) on the table. Now, when we try to insert a new row into the table that is a duplicate of an existing row, the insert fails:
Similarly, if we try to update an existing row so that it becomes a duplicate of another row, the update fails:
In other words, simple INSERT-VALUE and UPDATE statements fail if they introduce duplicate rows into a Teradata SET table.
There is a notable exception to this rule. Consider the following staging table, which has the same attributes as the target table:
The staging table is a MULTISET table and accepts duplicate rows. We populate three rows into the staging table. The first row is a duplicate of a row in the target table. The second and third rows are duplicates of each other, but don’t duplicate any of the target rows.
Now we successfully insert the staging data into the target table (which is a SET table):
If we examine the target table, we can see that a single row for (2022-01-05, 500) has been inserted, and the duplicate row for (2022-01-01, 100) has been discarded. Essentially, Teradata silently discards any duplicate rows when it performs an INSERT-SELECT statement. This includes duplicates that are in the staging table and duplicates that are shared between the staging and target tables.
Essentially, SET tables behave differently depending on the type of operation being run. An INSERT-VALUE or UPDATE operation suffers a failure if it introduces a duplicate row into the target. An INSERT-SELECT operation doesn’t suffer a failure if the staging table contains a duplicate row, or a duplicate row is shared between the staging and table tables.
In this post, we don’t go into detail on how to convert INSERT-VALUE or UPDATE statements. These statements typically involve one or a few rows and are less impactful in terms of performance than INSERT-SELECT statements. For INSERT-VALUE or UPDATE statements, you can materialize the row (or rows) being created, and join that set to the target table to check for duplicates.
INSERT-SELECT
In the rest of this post, we analyze INSERT-SELECT statements carefully. Customers have told us that INSERT-SELECT operations can comprise up to 78% of the INSERT workload against SET tables. We are concerned with statements with the following form:
The schema of the staging table is identical to the target table on a column-by-column basis. As we mentioned earlier, a duplicate row can appear in two different circumstances:
- The staging table is not set-unique, meaning that there are two or more full row duplicates in the staging data
- There is a row x in the staging table and an identical row x in the target table
Because Amazon Redshift supports multiset table semantics, it’s possible that the staging table contains duplicates (the first circumstance we listed). Therefore, any automation must address both cases, because either can introduce a duplicate into an Amazon Redshift table.
Based on this analysis, we implemented the following algorithms:
- MINUS – This implements the full set logic deduplication using SQL MINUS. MINUS works in all cases, including when the staging table isn’t set-unique and when the intersection of the staging table and target table is non-empty. MINUS also has the advantage that NULL values don’t require special comparison logic to overcome NULL to NULL comparisons. MINUS has the following syntax:
- MINUS-MIN-MAX – This is an optimization on MINUS that incorporates a filter to limit the target table scan based on the values in the stage table. The min/max filters allow the query engine to skip large numbers of block during table scans. See Working with sort keys for more details.
We also considered other algorithms, but we don’t recommend that you use them. For example, you can perform a GROUP BY to eliminate duplicates in the staging table, but this step is unnecessary if you use the MINUS operator. You can also perform a left (or right) outer join to find shared duplicates between the staging and target tables, but then additional logic is needed to account for NULL = NULL conditions.
Performance
We tested the MINUS and MINUS-MIN-MAX algorithms on Amazon Redshift. We ran the algorithms on two Amazon Redshift clusters. The first configuration consisted of 6 x ra3.4xlarge nodes. The second consisted of 12 x ra3.4xlarge nodes. Each node contained 12 CPU and 96 GB of memory.
We created the stage and target tables with identical sort and distribution keys to minimize data movement. We loaded the same target dataset into both clusters. The target dataset consisted of 1.1 billion rows of data. We then created staging datasets that ranged from 20 million to 200 million rows, in 20 million row increments.
The following graph shows our results.
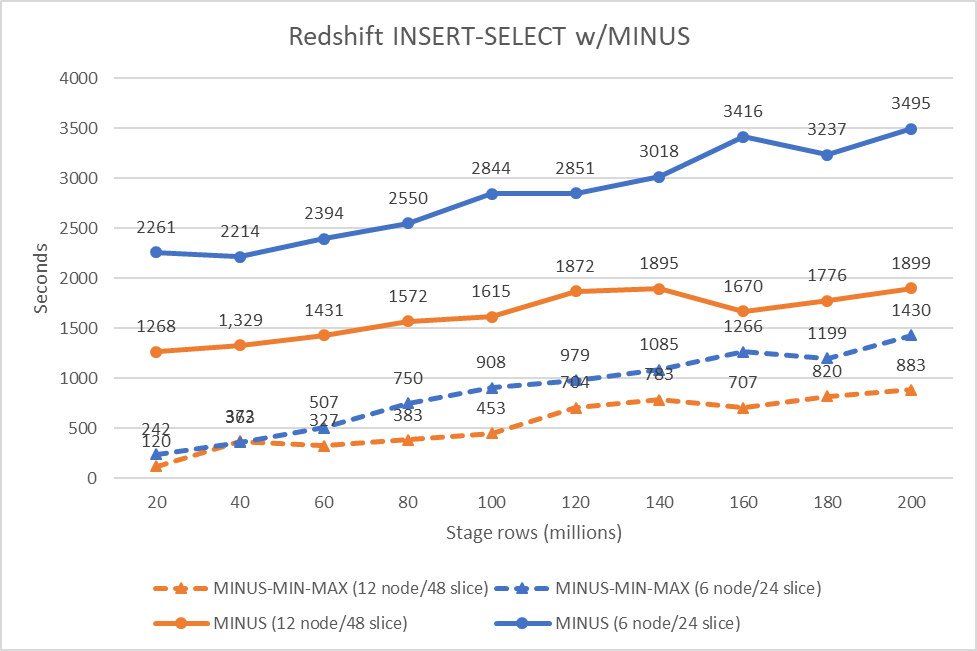
The test data was artificially generated and some skew was present in the distribution key values. This is manifested in the small deviations from linearity in the performance.
However, you can observe the performance increase that is afforded the MINUS-MIN-MAX algorithm over the basic MINUS algorithm (comparing orange lines or blue lines to themselves). If you’re implementing SET tables in Amazon Redshift, we recommend using MINUS-MIN-MAX because this algorithm provides a happy convergence of simple, readable code and good performance.
Automation
All Amazon Redshift tables allow duplicate rows, i.e., they are MULTISET tables by default. If you are converting a Teradata workload to run on Amazon Redshift, you’ll need to enforce SET semantics outside of the database.
We’re happy to share that AWS SCT will automatically convert your SQL code that operates against SET tables. AWS SCT will rewrite INSERT-SELECT that load SET tables to incorporate the rewrite patterns we described above.
Let’s see how this works. Suppose you have the following target table definition in Teradata:
The stage table is identical to the target table, except that it’s created as a MULTISET table in Teradata.
Next, we create a procedure to load the fact table from the stage table. The procedure contains a single INSERT-SELECT statement:
Now we use AWS SCT to convert the Teradata stored procedure to Amazon Redshift. First, select the stored procedure in the source database tree, then right-click and choose Convert schema.

AWS SCT converts the stored procedure (and embedded INSERT-SELECT) using the MINUS-MIN-MAX rewrite pattern.

And that’s it! Presently, AWS SCT only performs rewrite for INSERT-SELECT because those statements are heavily used by ETL workloads and have the most impact on performance. Although the example we used was embedded in a stored procedure, you can also use AWS SCT to convert the same statements if they’re in BTEQ scripts, macros, or application programs. Download the latest version of AWS SCT and give it a try!
Conclusion
In this post, we showed how to implement SET table semantics in Amazon Redshift. You can use the described design patterns to develop new applications that require SET semantics. Or, if you’re converting an existing Teradata workload, you can use AWS SCT to automatically convert your INSERT-SELECT statements so that they preserve the SET table semantics.
We’ll be back soon with the next installment in this series. Check back for more information on automating your migrations from Teradata to Amazon Redshift. In the meantime, you can learn more about Amazon Redshift and AWS SCT. Happy migrating!
About the Authors
 Michael Soo is a Principal Database Engineer with the AWS Database Migration Service team. He builds products and services that help customers migrate their database workloads to the AWS cloud.
Michael Soo is a Principal Database Engineer with the AWS Database Migration Service team. He builds products and services that help customers migrate their database workloads to the AWS cloud.
 Po Hong, PhD, is a Principal Data Architect of the Modern Data Architecture Global Specialty Practice (GSP), AWS Professional Services. He is passionate about helping customers to adopt innovative solutions and migrate from large scale MPP data warehouses to the AWS modern data architecture.
Po Hong, PhD, is a Principal Data Architect of the Modern Data Architecture Global Specialty Practice (GSP), AWS Professional Services. He is passionate about helping customers to adopt innovative solutions and migrate from large scale MPP data warehouses to the AWS modern data architecture.