AWS Big Data Blog
Tag: R

Predict Billboard Top 10 Hits Using RStudio, H2O and Amazon Athena
In this walkthrough, you leverage H2O.ai, Amazon Athena, and RStudio to make predictions on whether a song might make it to the Top 10 Billboard charts. You explore the GLM, GBM, and deep learning modeling techniques using H2O’s rapid, distributed and easy-to-use open source parallel processing engine.
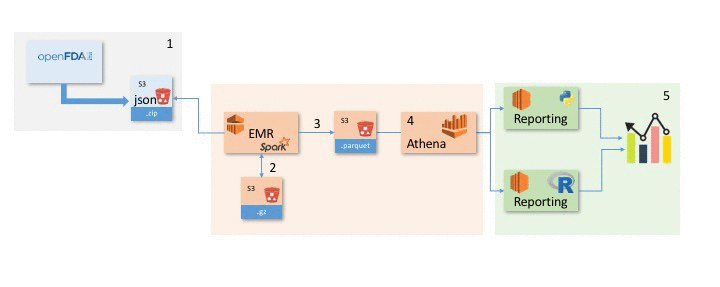
Analyze OpenFDA Data in R with Amazon S3 and Amazon Athena
One of the great benefits of Amazon S3 is the ability to host, share, or consume public data sets. This provides transparency into data to which an external data scientist or developer might not normally have access. By exposing the data to the public, you can glean many insights that would have been difficult with […]
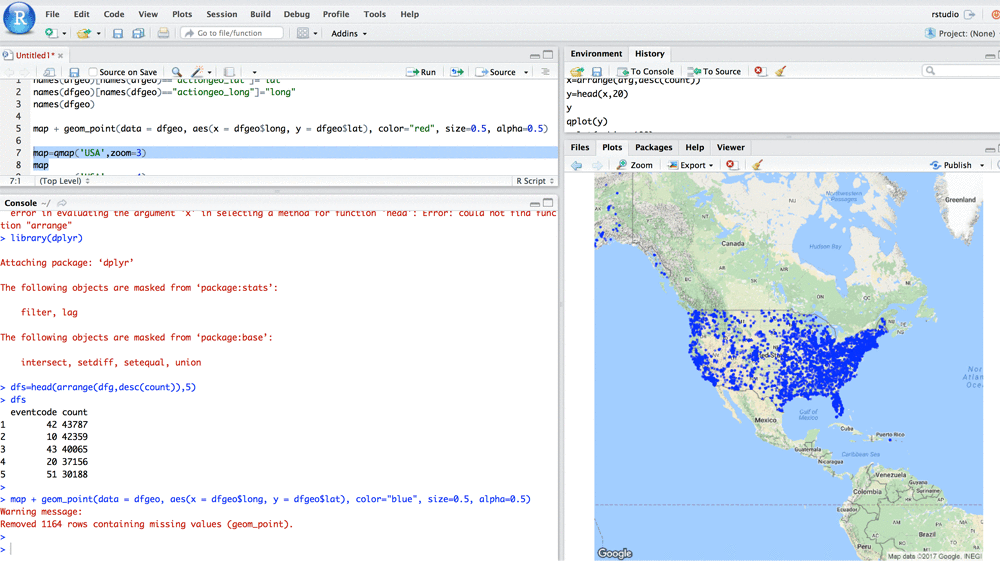
Running R on Amazon Athena
This blog post has been translated into Japanese. Data scientists are often concerned about managing the infrastructure behind big data platforms while running SQL on R. Amazon Athena is an interactive query service that works directly with data stored in S3 and makes it easy to analyze data using standard SQL without the need to […]

Exploring Geospatial Intelligence using SparkR on Amazon EMR
Gopal Wunnava is a Senior Consultant with AWS Professional Services The number of data sources that use location, such as smartphones and sensory devices used in IoT (Internet of things), is expanding rapidly. This explosion has increased demand for analyzing spatial data. Geospatial intelligence (GEOINT) allows you to analyze data that has geographical or spatial […]
Crunching Statistics at Scale with SparkR on Amazon EMR
Christopher Crosbie is a Healthcare and Life Science Solutions Architect with Amazon Web Services. This post is co-authored by Gopal Wunnava, a Senior Consultant with AWS Professional Services. SparkR is an R package that allows you to integrate complex statistical analysis with large datasets. In this blog post, we introduce you running R with the […]

Connecting R with Amazon Redshift
Markus Schmidberger is a Senior Big Data Consultant for AWS Professional Services Amazon Redshift is a fast, petabyte-scale cloud data warehouse for PB of data. AWS customers are moving huge amounts of structured data into Amazon Redshift to offload analytics workloads or to operate their DWH fully in the cloud. Business intelligence and analytic teams […]
Running R on AWS
Many AWS customers already use the popular open-source statistic software R for big data analytics and data science. Other customers have asked for instructions and best practices for running R on AWS. Several months ago, I (Markus) wrote a post showing you how to connect R with Amazon EMR, install RStudio on the Hadoop master node, and use R […]
Statistical Analysis with Open-Source R and RStudio on Amazon EMR
Markus Schmidberger is a Senior Big Data Consultant for AWS Professional Services Big Data is on every CIO’s mind. It is synonymous with technologies like Hadoop and the ‘NoSQL’ class of databases. Another technology shaking things up in Big Data is R. This blog post describes how to set up R, RHadoop packages and RStudio […]