AWS Compute Blog
Accelerating workloads using parallelism in AWS Step Functions
This post is written by Justin Callison, Senior Manager, AWS Step Functions.
In this blog, you use AWS Step Functions to build an application that uses parallel processing to complete four hours of work in around 60 seconds.
Parallel processing is a common computing approach to help solve large problems in a shorter period of time. By running the components of a problem concurrently, the total duration is greatly reduced. For example, to process 1,000 log files for one minute each, it takes over 16 hours to complete if sequentially processed. When processed in parallel, the same task takes only one minute.
Effective parallel processing requires scalable computing capacity. It also adds complexity for you to orchestrate the parallel components and to produce a consistent result. These challenges increase with the amount of parallelism that you seek to apply. The scalability of AWS and the orchestration capabilities of AWS Step Functions help you overcome these challenges.
Deploying the test runner sample application
With this sample application, you deploy a serverless test system using Step Functions that has thousands of degrees of parallelism. You learn how to decompose this problem into multiple state machines and how this approach yields improved scalability and manageability. You also learn how to monitor this system with Amazon CloudWatch and AWS X-Ray.
The sample application is built using the AWS Serverless Application Model (AWS SAM) and the Python programming language. Use the following commands to deploy this application to your AWS account.
git clone https://github.com/aws-samples/aws-stepfunctions-examples.git
cd aws-stepfunctions-examples/sam/app-decompose-for-parallelism
sam build
sam deploy --guided --profile <profile_name> --region <region code>
The sample application includes four state machines:
- TestRunner-Main is the entry point to the application.
- TestRunner-Distributor recursively invokes parallel instances of the test.
- TestRunner-ResultRecorder records the results of tests in Amazon DynamoDB and CloudWatch metrics.
- TestRunner-Test-SimpleWait is a mock test that waits for a random number of seconds between 1 and 5.

To initiate a test run, go to Step Functions in the AWS Management Console and navigate to the TestRunner-Main state machine. Choose the Start execution button. By default, the application runs a single iteration. To initiate a run with 5,000 iterations, enter {"iteration_count": 5000} for input. You can also specify a meaningful name for your test run in the Name field. Then choose Start execution.

In the console, you can monitor the test run as it progresses through to completion.

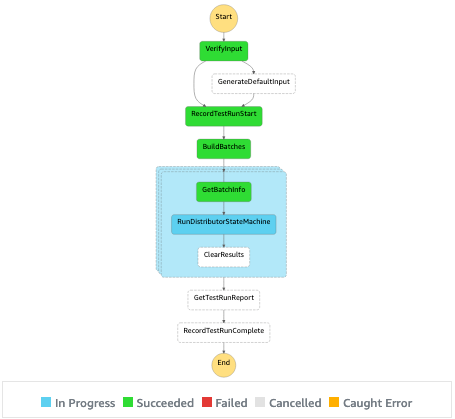
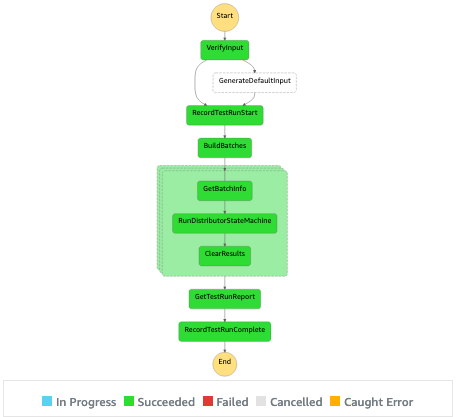
You find results from the run, including both a summary and detailed results per test, in the execution output. You see that 5,000 iterations of this test were completed in 60 seconds through parallel processing. Sequential execution would have taken around 4 hours.
{
"summary": {
"test_count": 5000,
"successful_count": 5000,
"failed_count": 0,
"average_duration_ms": 3002.588,
"fastest_test_ms": 1000,
"slowest_test_ms": 5020,
"results_truncated": true
},
"test_results": [
…
How it works
This section explains how this feature works in more detail.
Managing state size limits
Step Functions limits the size of input passed between states to 256 kB. For higher numbers of iteration_count, the sample application exceeds that value. To avoid reaching this limit, the sample application uses Amazon S3 to store the data for the test run and only reads the data necessary for the workflow.
Managing maximum history events per execution
Step Functions limits the number of history events per execution to 25,000. A large test run may exceed this limit. The sample application manages this by splitting the work into multiple smaller units. The TestRunner-Main state machine invokes the TestRunner-Distributor state machine using the Step Functions service integration.
"RunDistributorStateMachine": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.sync:2",
"Parameters": {
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"tests-to-run.$": "$.stateoutputs.GetBatchInfo.Payload.tests-to-run",
"test-run-id.$": "$$.Execution.Id"
},
"StateMachineArn": "${StateMachineDistributor}",
"Name.$": "States.Format('{}_batch{}',$$.Execution.Name,$['stateoutputs']['GetBatchInfo']['Payload']['batchnumber'])"
},
Aside from managing the maximum history events per execution, this decomposition pattern helps to simplify the solution. Decomposing a bigger problem into a set of smaller and simpler ones is a common approach to manage complexity. The distinct state machines in this sample application have a single purpose that can be more easily understood.
Monitoring and troubleshooting are easier, because you can focus on isolated units of work. Maintenance is easier because changes do not impact other parts of the application. And re-use is also easier, allowing you to develop common capabilities and use the same definitions in different applications. This composition is made easier through the Step Functions service integration.
Managing maximum parallelization with map state
The Step Functions map state helps to achieve dynamic parallelization in your state machine. It starts a separate instance of the iterator for each item of the input array. However, the map state runs at most 40 of these iterations concurrently. To achieve higher degrees of concurrency, the TestRunner-Main state machine groups test iterations into at most 40 batches before entering the map state.
"BuildBatches": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "${FunctionBuildList}",
"Payload": {
"iteration_count.$": "$.iteration_count",
"execution_name.$": "$$.Execution.Name "
}
},
"OutputPath": "$.Payload",
"Next": "RunTests",
"TimeoutSeconds": 905,
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 1,
"BackoffRate": 2,
"MaxAttempts": 15
}
]
},
"RunTests": {
"Type": "Map",
"ItemsPath": "$.batch_index",
"Parameters": {
"batch_id.$": "$$.Map.Item.Value",
"test-run-id.$": "$$.Execution.Id",
"s3_bucket.$": "$.s3_bucket",
"s3_key.$": "$.s3_key"
},
The RunTests map state then invokes the TestRunner-Distributor, which itself uses the map state to invoke one test per iteration. The TestRunner-Distributor state machine first checks to see if the expected number of iterations exceeds 40. If so, it again creates batches of up to 40 iterations and calls itself recursively. In this way, the app ensures that concurrency is not restricted.

Aside from managing the maximum concurrency for map state, this approach is also important to work with the maximum history events per execution. A larger number of iterations per execution yields a larger number of history events. The recursive decomposition ensures that any given execution will not reach this limit.
Using Express Workflows for short duration, idempotent segments
Express state machines have lower cost and lower latency than standard state machines for short duration, idempotent workflows. Express state machines are defined like standard state machines but they have different execution behavior. They have an at-least-once execution semantic and they do not store execution history in the service (optionally, it can be emitted to CloudWatch Logs). If the needs of your workflow align with this behavior, Express Workflows can reduce the cost and improve the performance of your application.
This is not a binary decision and you can use Express Workflows for portions of your workflow by again using the Step Functions service integration. In the sample application, once test execution completes, the results are passed to the express TestRunner-ResultRecorder state machine. The application does not require the execution history from these steps and it can tolerate this portion running more than once. By breaking this portion into a separate express state machine, the sample application simplifies the TestRunner-Distributor state machine while also achieving lower cost and reduced latency.

Monitoring
The sample application uses both built-in and custom instrumentation to support observability.
Monitoring: CloudWatch metrics
Step Functions emits execution metrics automatically to CloudWatch. The TestRunner-ResultRecorder stores results of test executions into DynamoDB for later reporting, but it also emits custom metrics to CloudWatch metrics. These metrics are then surfaced in the CloudWatch dashboard that is also included in the application.
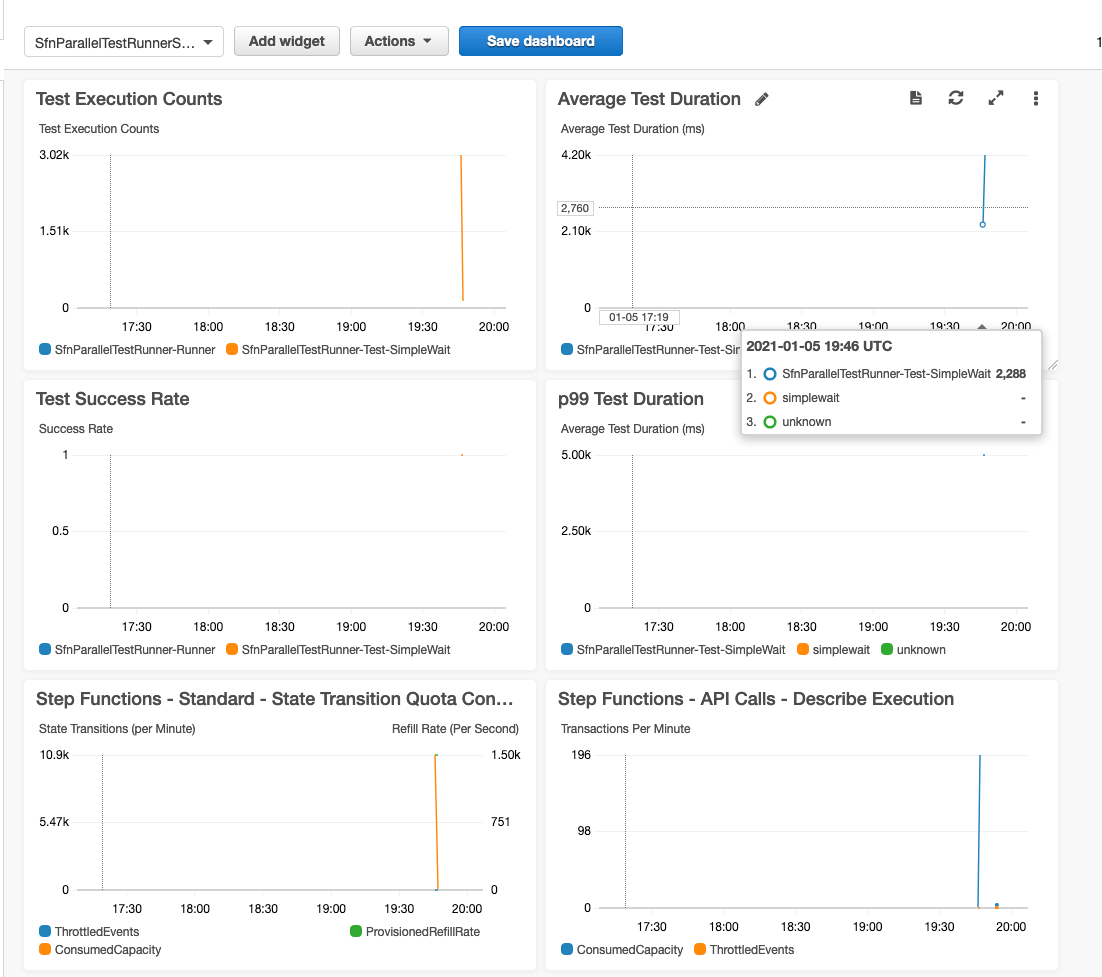
Monitoring: CloudWatch Logs
Step Functions optionally supports emission of execution history events to CloudWatch Logs for both standard and express state machines. The sample app uses this feature and the dashboard includes a CloudWatch Logs Insights widget that surfaces task failures. The following screenshot shows task failures caused by throttled calls to CloudWatch.
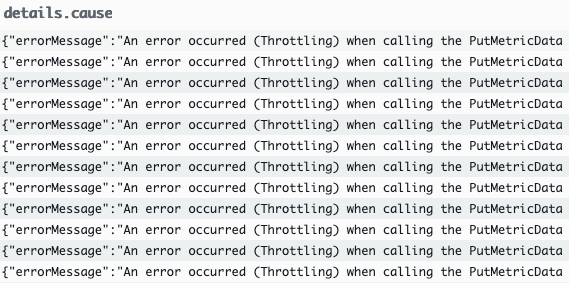
In this case, these errors did not cause the application to fail because the state machine specifies retries and error handling. The ability to handle retries and exceptions without writing custom code is one of the benefits of using Step Functions.
As shown in the following code, the TestRunner-ResultRecorder attempts to record metrics three times with exponential backoff in between attempts. If it is still unsuccessful, the error is handled and the workflow continues because the metrics are provided for observability and not required for the application to function.
"Retry": [ {
"ErrorEquals": [ "States.ALL" ],
"MaxAttempts": 3,
"BackoffRate": 2
} ],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.errors.duration_metric",
"Next": "RecordTestRun-StatusMetric"
}
],
"Next": "RecordTestRun-StatusMetric"
Monitoring: AWS X-Ray
Step Functions also supports optional tracing with AWS X-Ray. Using the console (or by setting a property in the AWS SAM template), you can enable X-Ray tracing that provides an end-to-end view across the services involved in your test run. This includes nested invocation of Step Functions, allowing you to see a trace from TestRunner-Main through to TestRunner-ResultRecorder in a single trace.

Conclusion
In this blog post, you learn how to use AWS Step Functions and parallel processing to complete four hours of work in 60 seconds. You learn how to apply the pattern of decomposition to achieve improved scalability and manageability. And you see how to use built-in and customer instrumentation to monitor and troubleshoot your application.
To learn more about Step Functions, visit Serverless Land.