AWS Compute Blog
Building federated GraphQL on AWS Lambda
This post is written by Krzysztof Lis, Senior Software Development Engineer, IMDb.
IMDb is the world’s most popular source for movie, TV, and celebrity content. It deals with a complex business domain including movies, shows, celebrities, industry professionals, events, and a distributed ownership model. There are clear boundaries between systems and data owned by various teams.
Historically, IMDb uses a monolithic REST gateway system that serves clients. Over the years, it has become challenging to manage effectively. There are thousands of files, business logic that lacks clear ownership, and unreliable integration tests tied to the data. To fix this, the team used GraphQL (GQL). This is a query language for APIs that lets you request only the data that you need and a runtime for fulfilling those queries with your existing data.
It’s common to implement this protocol by creating a monolithic service that hosts the complete schema and resolves all fields requested by the client. It is good for applications with a relatively small domain and clear, single-threaded ownership. IMDb chose the federated approach, that allows us to federate GQL requests to all existing data teams. This post shows how to build federated GraphQL on AWS Lambda.
Overview
This article covers migration from a monolithic REST API and monolithic frontend to a federated backend system powering a modern frontend. It enumerates challenges in the earlier system and explains why federated GraphQL addresses these problems.
I present the architecture overview and describe the decisions made when designing the new system. I also present our experiences with developing and running high-traffic and high-visibility pages on the new endpoint – improvement in IMDb’s ownership model, development lifecycle, in addition to ease of scaling.
Comparing GraphQL with federated GraphQL

Federated GraphQL allows you to combine GraphQLs APIs from multiple microservices into a single API. Clients can make a single request and fetch data from multiple sources, including joining across data sources, without additional support from the source services.
This is an example schema fragment:
type TitleQuote {
"Quote ID"
id: ID!
"Is this quote a spoiler?"
isSpoiler: Boolean!
"The lines that make up this quote"
lines: [TitleQuoteLine!]!
"Votes from users about this quote..."
interestScore: InterestScore!
"The language of this quote"
language: DisplayableLanguage!
}
"A specific line in the Title Quote. Can be a verbal line with characters speaking or stage directions"
type TitleQuoteLine {
"The characters who speak this line, e.g. 'Rick'. Not required: a line may be non-verbal"
characters: [TitleQuoteCharacter!]
"The body of the quotation line, e.g 'Here's looking at you kid. '. Not required: you may have stage directions with no dialogue."
text: String
"Stage direction, e.g. 'Rick gently places his hand under her chin and raises it so their eyes meet'. Not required."
stageDirection: String
}
This is an example monolithic query: “Get the 2 top quotes from The A-Team (title identifier: tt0084967)”:
{
title(id:"tt0084967"){
quotes(first:2){
lines { text }
}
}
}
Here is an example response:
{
"data": {
"title": {
"quotes": {
"lines": [
{
"text": "I love it when a plan comes together!"
},
{
"text": "10 years ago a crack commando unit was sent to prison by a military court for a crime they didn't commit..."
}
]
}
}
}
}
This is an example federated query: “What is Jackie Chan (id nm0000329) known for? Get the text, rating and image for each title”
{
name(id: "nm0000329") {
knownFor(first: 4) {
title {
titleText {
text
}
ratingsSummary {
aggregateRating
}
primaryImage {
url
}
}
}
}
}The monolithic example fetches quotes from a single service. In the federated example, knownFor, titleText, ratingsSummary, primaryImage are fetched transparently by the gateway from separate services. IMDb federates the requests across 19 graphlets, which are transparent to the clients that call the gateway.
Architecture overview

IMDb supports three channels for users: website, iOS, and Android apps. Each of the channels can request data from a single federated GraphQL gateway, which federates the request to multiple graphlets (sub-graphs). Each of the invoked graphlets returns a partial response, which the gateway merges with responses returned by other graphlets. The client receives only the data that they requested, in the shape specified in the query. This can be especially useful when the developers must be conscious of network usage (for example, over mobile networks).
This is the architecture diagram:
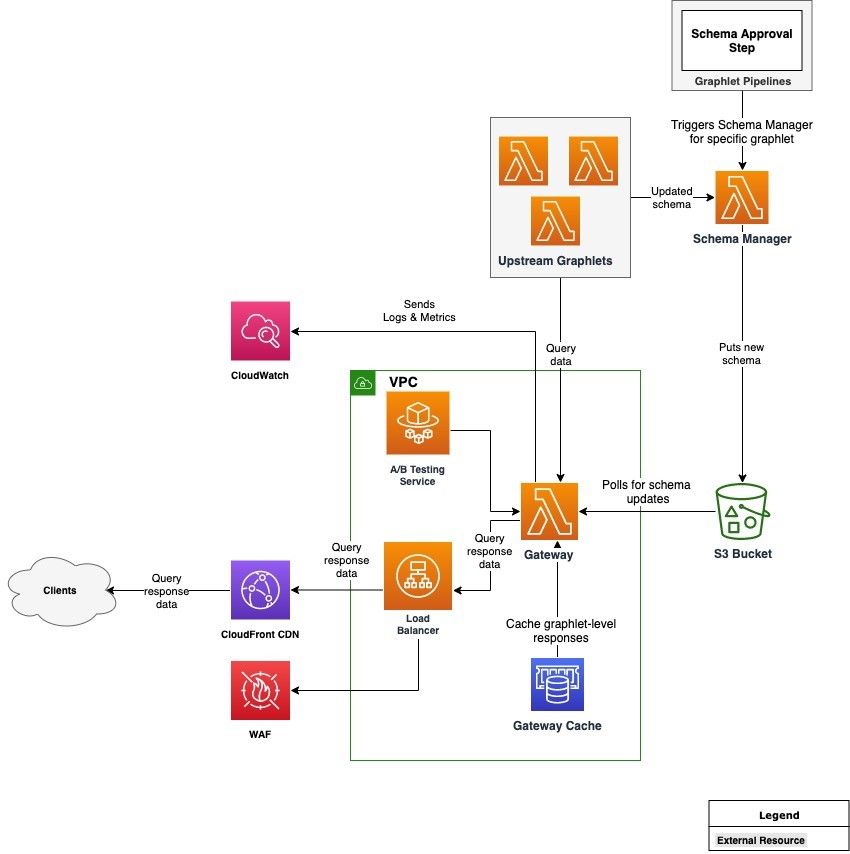
There are two core components in the architecture: the Gateway and Schema Manager, which run on Lambda. The Gateway is a Node.js-based Lambda function that is built on top of open-source Apollo Gateway code. It is customized with code responsible predominantly for handling authentication, caching, metrics, and logging.
Other noteworthy components are Upstream Graphlets and an A/B Testing Service that enables A/B tests in the graph. The Gateway is connected to an Application Load Balancer, which is protected by AWS WAF and fronted by Amazon CloudFront as our CDN layer. This uses Amazon ElastiCache with Redis as the engine to cache partial responses coming from graphlets. All logs and metrics generated by the system are collected in Amazon CloudWatch.
Choosing the compute platform
This uses Lambda, since it scales on demand. IMDb uses Lambda’s Provisioned Concurrency to reduce cold start latency. The infrastructure is abstracted away so there is no need for us to manage our own capacity and handle patches.
Additionally, Application Load Balancer (ALB) has support for directing HTTP traffic to Lambda. This is an alternative to API Gateway. The workload does not need many of the features that API Gateway provides, since the gateway has a single endpoint, making ALB a better choice. ALB also supports AWS WAF.
Using Lambda, the team designed a way to fetch schema updates without needing to fetch the schema with every request. This is addressed with the Schema Manager component. This component improves latency and improves the overall customer experience.
Integration with legacy data services
The main purpose of the federated GQL migration is to deprecate a monolithic service that aggregates data from multiple backend services before sending it to the clients. Some of the data in the federated graph comes from brand new graphlets that are developed with the new system in mind.
However, much of the data powering the GQL endpoint is sourced from the existing backend services. One benefit of running on Lambda is the flexibility to choose the runtime environment that works best with the underlying data sources and data services.
For the graphlets relying on the legacy services, IMDb uses lightweight Java Lambda functions using provided client libraries written in Java. They connect to legacy backends via AWS PrivateLink, fetch the data, and shape it in the format expected by the GQL request. For the modern graphlets, we recommend the graphlet teams to explore Node.js as the first option due to improved performance and ease of development.
Caching
The gateway supports two caching modes for graphlets: static and dynamic. Static caching allows graphlet owners to specify a default TTL for responses returned by a graphlet. Dynamic caching calculates TTL based on a custom caching extension returned with the partial response. It allows graphlet owners to decide on the optimal TTL for content returned by their graphlet. For example, it can be 24 hours for queries containing only static text.
Permissions
Each of the graphlets runs in a separate AWS account. The graphlet accounts grant the gateway AWS account (as AWS principal) invoke permissions on the graphlet Lambda function. This uses a cross-account IAM role in the development environment that is assumed by stacks deployed in engineers’ personal accounts.
Experience with developing on federated GraphQL
The migration to federated GraphQL delivered on expected results. We moved the business logic closer to the teams that have the right expertise – the graphlet teams. At the same time, a dedicated platform team owns and develops the core technical pieces of the ecosystem. This includes the Gateway and Schema Manager, in addition to the common libraries and CDK constructs that can be reused by the graphlet teams. As a result, there is a clear ownership structure, which is aligned with the way IMDb teams are organized.
In terms of operational excellence of the platform team, this reduced support tickets related to business logic. Previously, these were routed to an appropriate data service team with a delay. Integration tests are now stable and independent from underlying data, which increases our confidence in the Continuous Deployment process. It also eliminates changing data as a potential root cause for failing tests and blocked pipelines.
The graphlet teams now have full ownership of the data available in the graph. They own the partial schema and the resolvers that provide data for that part of the graph. Since they have the most expertise in that area, the potential issues are identified early on. This leads to a better customer experience and overall health of the system.
The web and app developers groups are also impacted by the migration. The learning curve was aided by tools like GraphQL Playground and Apollo Client. The teams covered the learning gap quickly and started delivering new features.
One of the main pages at IMDb.com is the Title Page (for example, Shutter Island). This was successfully migrated to use the new GQL endpoint. This proves that the new, serverless federated system can serve production traffic at over 10,000 TPS.
Conclusion
A single, highly discoverable, and well-documented backend endpoint enabled our clients to experiment with the data available in the graph. We were able to clean up the backend API layer, introduce clear ownership boundaries, and give our client powerful tools to speed up their development cycle.
The infrastructure uses Lambda to remove the burden of managing, patching, and scaling our EC2 fleets. The team dedicated this time to work on features and operational excellence of our systems.
Part two will cover how IMDb manages the federated schema and the guardrails used to ensure high availability of the federated GraphQL endpoint.
For more serverless learning resources, visit Serverless Land.