AWS Compute Blog
Visualizing Amazon API Gateway usage plans using Amazon QuickSight
February 12, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
This post is courtesy of Roberto Iturralde, Solutions Architect.
Many customers build applications for their users accessible via HTTP API endpoints. Users provide unique keys in their requests for authentication, authorization, and optional metering by the service provider. Business and technical owners benefit from detailed analytics across the API endpoints and usage patterns across customers. This information helps understand product adoption and informs future features.
Amazon API Gateway can produce detailed access logs to show who has accessed the API. When using usage plans, a customer identifier is included in the log records. You can use these logs to populate a business intelligence service, such as Amazon QuickSight, to analyze and report on usage patterns across your APIs and customers.
Solution overview

Using enriched API Gateway access logs, you can analyze how customers are accessing your API products. This dashboard shows several visualizations in Amazon QuickSight based on traffic to a sample API Gateway endpoint.
- The pie chart shows the share of month-to-date traffic across all APIs by usage plan.
- The bar chart shows the top customers in the Enterprise usage plan by month-to-date traffic, with bar coloring by HTTP status code.
- The pivot table shows the percent of traffic to each API endpoint by usage plan and customer.
The solution described in this post is meant for business intelligence (BI) analysis. A BI dashboard is useful for historical reporting and typically the data freshness ranges from hours to days.
Solution architecture
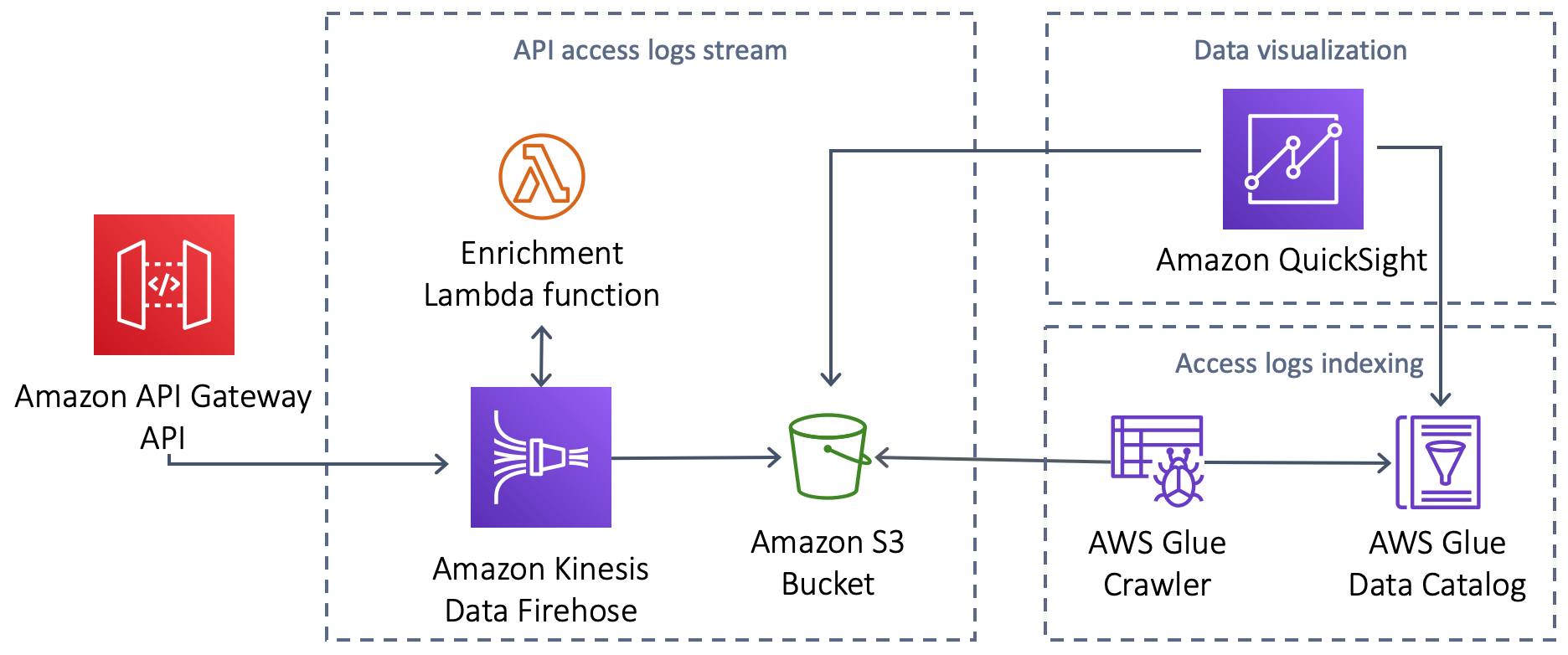
Components:
- API access logs stream – API access logs are streamed in real time from Amazon API Gateway to Amazon Kinesis Data Firehose. Kinesis Firehose buffers the records and enriches them with information from the API usage plans. It then writes the batches of enriched records to an Amazon S3 bucket for durable, secure storage.
- Access logs indexing – Metadata about the API access logs is stored in an AWS Glue Data Catalog that is used by Amazon QuickSight for querying. A nightly AWS Glue crawler detects and indexes newly written access logs. The Glue crawler can run more frequently for fresher data in QuickSight.
- Data visualization – Amazon QuickSight is configured with the S3 location of the access logs as a data source to feed a QuickSight analysis.
Implementation walk-through
This tutorial assumes you already have an API Gateway API with a usage plan configured. If you do not, follow this tutorial to create an API and follow this article to create a usage plan.
First, deploy an AWS SAM template into your account. This template creates an Amazon S3 bucket where the access logs are stored for analysis. It also creates an AWS Lambda function to enrich the API access logs.
Then you create a Kinesis Data Firehose delivery stream to receive access logs from API Gateway. The stream enriches the records using the Lambda function, buffers and batches the records, and writes them to the S3 bucket. Finally, you update a deployed API Gateway stage to write access logs to the Kinesis delivery stream.
Launch the AWS SAM Template
To create some of the resources referenced in this post, you can download the SAM template or choose the button below to launch the stack.
![]()
Choose Next on each screen of the CloudFormation stack creation process. Once the stack creation completes, note the names of the resources on the Outputs tab.

The Lambda function created by the SAM template performs a few key tasks. During function initialization, it fetches API Gateway usage plan details into memory. On each invocation, it iterates through each access log record from Kinesis Firehose. Each record is decoded from base64 encoded binary and enriched with usage plan name and customer name. Each record is then converted back to base64 encoded binary to return to the Kinesis Firehose stream.
API access logs stream
- Navigate to the Kinesis Data Firehose console and choose Create delivery stream.

- Under Delivery stream name, enter a name in the format amazon-apigateway-{your-delivery-stream-name}. It is required that your stream name begin with amazon-apigateway-.

- Leave the default Source setting of Direct PUT or other sources. Choose Next.
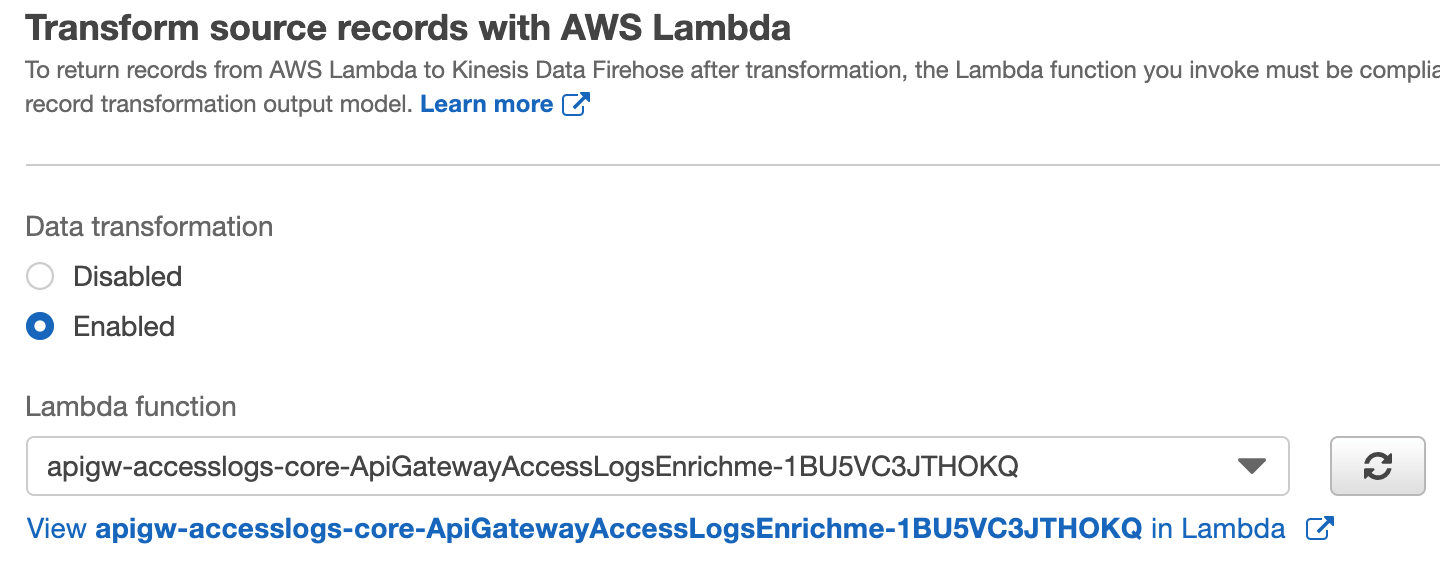
- Under Data transformation, select Enabled. In the Lambda function dropdown, select the function created earlier. Choose Next.

- Select Amazon S3 as the Destination. In the S3 bucket dropdown, select the bucket created earlier.

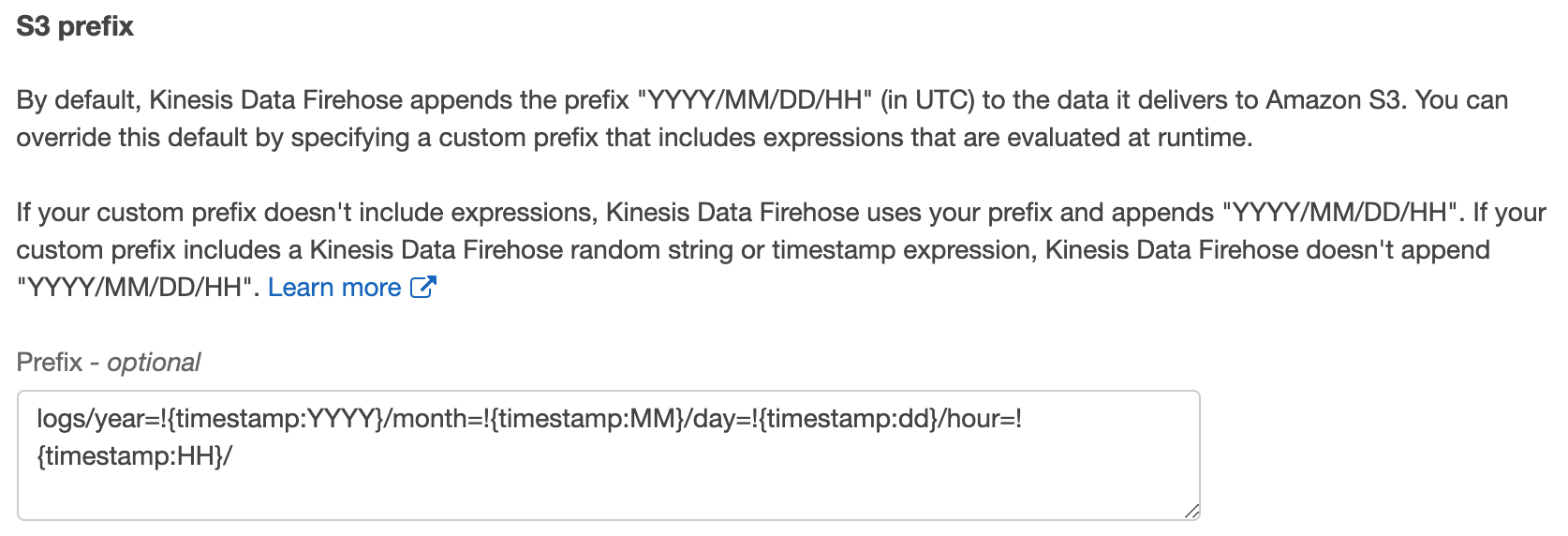
- Under S3 prefix, enter logs/year=!{timestamp:YYYY}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/. This naming convention allows the AWS Glue crawler to automatically partition this data during indexing.

- Under S3 error prefix, enter errors/!{firehose:random-string}/!{firehose:error-output-type}/!{timestamp:yyyy/MM/dd}/. This will write errors encountered by the Firehose delivery stream to a folder named errors in the S3 bucket, followed by folders by error type and error timestamp. Choose Next.

- Leave the default buffer, compression, and other settings. At the bottom of the screen, select Create new or choose to create a new IAM role for this delivery stream. In the window that opens, leave the default settings. Choose Allow.

- This will return you to the Kinesis Firehose delivery stream creation wizard. Choose Next.
- On the review page, verify the settings and choose Create delivery stream. Wait for the stream to be successfully created.
- You can now configure API Gateway to stream access logs to this Kinesis Firehose delivery stream. Follow these instructions to enable access logging on your API stages using the ARN of the Firehose delivery stream you created.
- Under Log Format, choose the fields to include in the access logs in JSON format. Find examples in the API Gateway documentation as well as the full set of available fields in the $context variable. The below fields and mapped names are required for the enrichment Lambda function. Choose Save Changes.
{ "apiId": "$context.apiId", "identity.apiKeyId": "$context.identity.apiKeyId", "stage": "$context.stage" } - As the API stages where you enabled access logging receive traffic, you will see files written to your Amazon S3 bucket. Note that the Firehose delivery stream buffers data before writing to S3, so it may take some time before files appear.




Access logs for your API are now flowing to an Amazon S3 bucket enriched with usage plan information. You now need to index this data for querying and make it available in Amazon QuickSight for analysis.
Access Logs Indexing
- Navigate to the AWS Glue console. If this is your first time using AWS Glue, choose the Get Started button on the landing page. On the left side of the console select Crawlers. On the Crawlers tab, choose Add crawler.
- Enter a name for the Crawler and choose Next.
- On the Specify crawler source type page, choose Data stores. Choose Next.
- Select S3 as the data store and leave the Connection field empty. In the Include path section, use the folder icon to browse your existing S3 buckets. Use the plus sign to expand the folders beneath the S3 bucket created earlier. Select the logs folder and choose Select. If you don’t see the logs folder, you add it manually later.

- If you did not see a logs folder on the prior screen, you can add it to the end of the S3 location in the input box. Choose Next.

- On the Add another data source screen, leave No selected and choose Next.
- Select Create an IAM Role and enter a name for the IAM role that AWS Glue uses to crawl the S3 bucket. Choose Next.
- Under the Frequency for scheduled crawling, select Daily and choose the time when you want to update your index of access logs. The crawl frequency can be modified later. Choose Next.
- On the crawler output selection page, select Add database to create a new metadata database for the API Gateway access logs. Name your metadata database and choose Create. Back on the output configuration screen, choose Next.
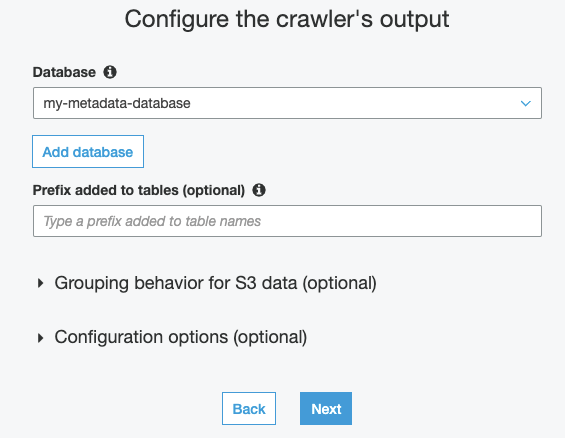
- Choose Finish.
- In the Crawlers tab of the AWS Glue console, select the checkbox next to the crawler you created. Choose Run crawler.

- After the crawler finishes, you see a table named logs in the Glue database. Navigate to the Tables page of the Glue console to view this table. Selecting the table name will show the metadata that the crawler populated, including the file format, number of records, and schema of the access logs records.

You now have an AWS Glue database with metadata of the access logs stored in Amazon S3 and a scheduled Glue crawler. Lastly, you need to make this data available in Amazon QuickSight for visualization and analysis.
Data Visualization
- Navigate to the Amazon QuickSight console.
First-time QuickSight users: Follow these instructions to create a QuickSight account.
All users: Follow these instructions to update your S3 permissions to include the S3 bucket created earlier containing the API Gateway access logs. - In the menu bar, select Manage data.

- On the top left of the Data Sets page, choose New data set.
- On the Create data set page, select Amazon Athena.

- On the New Athena data source page, enter a name for this data source. Leave the Athena workgroup on the default setting and select Create data source.
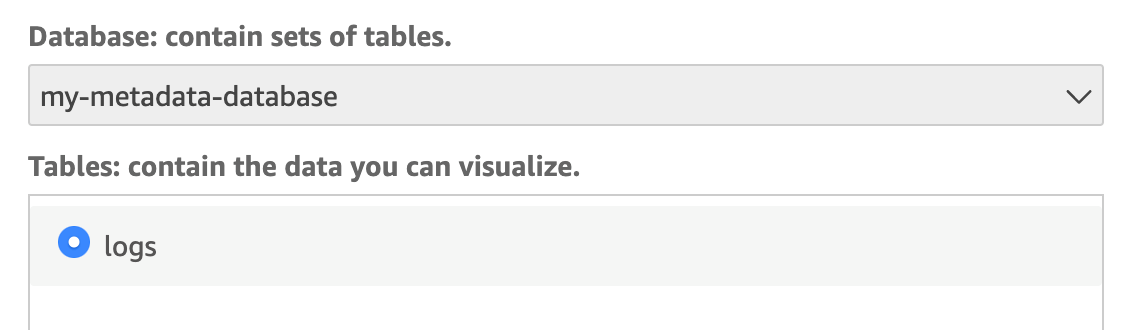
- On the following page, use the Database section to select the Glue database you created earlier. Once selected, you will see the tables available inside that database. Select the database table you created earlier to hold the metadata for the access logs in S3.

- On the final data set creation page, select Direct query your data. You can change this option later to use QuickSight’s native data cache to improve performance. Choose Visualize.
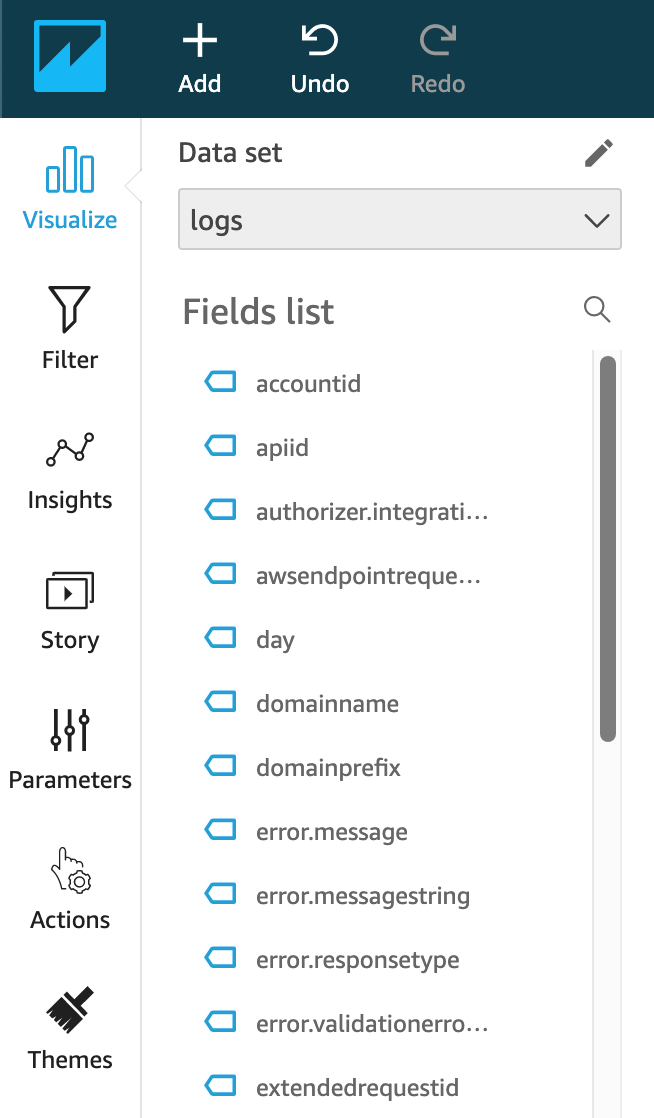
- This will create a QuickSight analysis based on a data set of the API Gateway access logs data. You should see the logs data set selected and the access logs fields available in the Fields list. You can now create visuals based on the API Gateway access logs data.



Conclusion
In this post, I walk through configuring streaming of API access logs from Amazon API Gateway to Amazon S3 via a Kinesis Firehose delivery stream. An AWS Glue crawler periodically updates metadata in an AWS Glue data catalog for the access logs in S3. This metadata is used by Amazon QuickSight to query the data in S3 to populate visuals in a QuickSight analysis. This allows business and technical owners of API-based products to analyze access trends by customers accessing their APIs.
To learn more, read about different types of visualizations available in QuickSight. As a performance and cost optimization, enable compression and format conversion from JSON to a columnar data format in your Kinesis Firehose delivery stream.