AWS Database Blog
Accelerating your application modernization with Amazon Aurora Machine Learning
Organizations that store and process data in relational databases are making the shift to the cloud. As part of this shift, they often wish to modernize their application architectures and add new cloud-based capabilities. Chief among these are machine learning (ML)-based predictions such as product recommendations and fraud detection. The rich customer data available in relational databases is a good basis for transforming customer experiences and business operations.
Organizations that store and process relational data seek to adopt ML services in the cloud quickly and broadly. In this post, we see how Amazon Aurora Machine Learning, a feature of Amazon Aurora, makes it easy to make ML-based predictions on relational data, using a video game as a use case.
Databases and ML
Incorporating an ML algorithm into a software application has traditionally required a lengthy integration process. It typically involves having a data scientist, who selects and trains the model, and in some cases an application developer, who needs to write application code to read data from the database, format it for the ML algorithm, call an ML service such as Amazon SageMaker to run the algorithm, format the output, and retrieve the results back to the application.
It can take several days or weeks to build an integration that achieves an application’s scalability requirements, especially if there are low latency requirements measured in milliseconds, which is typical for product recommendations, fraud detection, and many other applications. And after the integration is built, it requires maintenance when updating the ML algorithm or when the input data deviates from the training data.
Aurora Machine Learning simplifies the integration process by making ML algorithms available to run via SQL functions directly in the application. After you deploy the algorithm in SageMaker, you can run a SQL query in Aurora, and Aurora does the heavy lifting of efficiently transferring the data to SageMaker, managing input and output formatting, and retrieving the results. In our example, we show how to train a fraud detection model, then deploy it to SageMaker so a software developer with little to no ML expertise can add predictions via SQL statements.
Let’s play a game!
To demonstrate how we train a fraud detection algorithm and call it from an application via SQL statements, we use a video game use case. Our goal is to find cheaters—players who write bots to play on their behalf or coordinate with other players to gain advantage over legitimate players. Let’s explore which ML models can detect these cheats and how to run the analysis from the customer application using SQL.
The scenario that we simulate uses a successful multiplayer game launched in late 2020 on AWS. Although the game is a lot of fun, the customer care team received complaints about players cheating in the game. Our task is to catch these cheats and remove them from the game, so we want to build a cheat detection system that extends the customer care application and provides hints with good efficacy. We assume the customer care application uses an Aurora MySQL database, and we minimize changes to the application by using Aurora MySQL tools.
The game we use is SuperTuxKart, a free and open-source kart racing game.

Players take actions like collecting and using cans of Nitro. They also use various power-up items obtained by driving into item boxes laid out on the course. These power-ups include mushrooms to give players a speed boost, Koopa shells to be thrown at opponents, and banana peels and fake item boxes that can be laid on the course as hazards.
Player actions are defined as a collection of game actions such as kart steer, brake, drift, look back, and more. Cheating allows bots to benefit from power-up items while steering or braking the karts. Our main goal is to classify player behavior and distinguish between human and bot actions. After classifying suspicious player actions, we cross-reference these players with other customer records that are already stored in the application’s database. Key data includes customer care history such as in-game microtransactions and customer care events.
Therefore, we train two models. The first identifies bots by classifying player moves, and the second detects suspicious in-game microtransactions.
The data pipeline and schema
In our scenario, the game server runs in Amazon Elastic Kubernetes Service (Amazon EKS). The player actions are written to the game server standard output. We used the Fluentbit project to stream the server stdout to Amazon Kinesis Data Firehose. Kinesis Data Firehose stores the player actions in Amazon Simple Storage Service (Amazon S3), and we load the data using an AWS Lambda function to an Aurora table called actions. To enable rapid response to cheat activities in the game, we need to minimize the ingestion latency. In our example, we ingest the game events as online transactions. The time it takes to get player actions into Aurora from the time the game action took place is a few minutes and scales horizontally as Kinesis Data Firehose and Lambda scales.
The game play actions are defined as the struct Action:
The game server emits player game action logs in near-real time as the game progresses. p_guid is the player unique identifier, m_ticks is a counter that increments upon any player action. m_kart_id is the player kart unique ID. The m_value, m_value_l, and m_value_r fields indicate the action’s magnitude; for example, when a player attempts to slow down abruptly, the brake action carries the max integer 32768. It’s similar for acceleration and kart steering.
To train the cheat detection model, we facilitated hundreds of legitimate multiplayer game sessions and bot simulated game sessions. (One of this post’s authors played many rounds of SuperTuxKart with his 9-year-old son—not a bad way to gain a reputation as a cool dad.) We used the class field to manually classify the game sessions into legitimate and bot sessions. Prior to each game session, we captured the last game sequence ID; after the session, we updated the classified with 1 in the case of a bot simulated session or 0 in the case of a legitimate game session for the sequence of player actions:
Formulating the ML problem
The next step is to look at legitimate player actions and compare them with non-legitimate player (bot) actions. We used SageMaker Jupyter notebooks to discover trends that distinguish between the two groups. In the following graphs, the X axis is the player ID (id) and the Y axis is the value of the ticks (m_ticks).

The red plot shows bot game actions, and the blue plot shows legitimate human player actions. We can see that the bot game action frequency was more consistent than a legitimate human player, which gives us a way to differentiate between the two, as we now discuss.
The game simulates a kart’s motions that move at a dynamic acceleration along a non-straight line. We can use fundamental kinematic physics to calculate the average velocity and acceleration changes and train a linear regression-based model that predicts bot or human kart velocity and acceleration. We found that the values of the actions generated by a bot are distributed differently than a human player. We attribute the findings to a naively written bot, and to the behavior of the specific human player level that tends to generate more hectic action values than a bot that knows the right path to take.
In the real world, bot writers improve their bots continuously to avoid detection, and we have to continuously refine our detection capabilities. The good news is that the methodology we propose here is not limited to the specific bot implementation, and can indeed be continuously refined.
In the following section, we package the SQL statements with MySQL views that calculate the actions’ velocity and acceleration for brevity and demonstration purposes.
Let’s first calculate the player actions’ velocity, vel, in a session for bots and humans, using prev.class=curr.class as follows:
In this example, we assume a session (curr.session=prev.session) is tagged (bot or human) during the data ingestion to Aurora. We also include moves made by a single player curr.m_kart_id=prev.m_kart_id, same party size (curr.party_size=prev.party_size), and same classification (prev.class=curr.class).
We then use the velocity values and calculate the average acceleration, accel, for bots and humans in a similar way, as follows:
To observe the acceleration and velocity patterns, we populated two DataFrames using the following simple queries:
As we discussed earlier, the class column differentiates between bots and humans: class=1 is bot acceleration, class=0 is human acceleration.
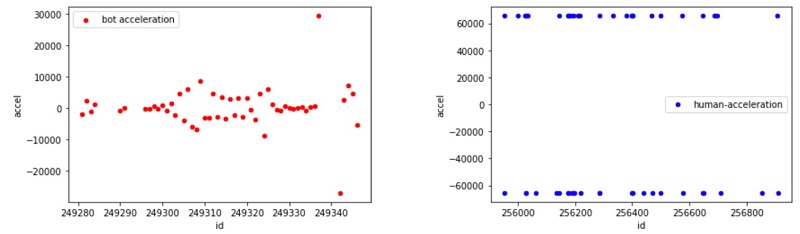
We can see that the kart average acceleration values accel generated by bots (class=1) scatter across a broader range of values, whereas human game actions (class=0) tend to be extreme. The average acceleration distribution can be used as a logistic function to model the classification binary dependent variable that indicates if an action was made by a bot or a human. Therefore, we use the SageMaker linear learner built-in algorithm to predict human or bot action, and combine this player move model with a separate, in-game transaction fraud detection model for a fuller picture.
The cheater detection process
We used Aurora as the data source for data exploration in our Jupyter notebook using the MySQL Python client, and also used Aurora to prepare the data for model training. After the model was trained, we hosted it in SageMaker with the endpoint name stk-bot-detect-actions. We defined a function in Aurora that calls the classification model against freshly streamed player data, as in the following code:
For more information about calling SageMaker endpoints from Aurora, and how the two services work together to simplify ML integration into your applications, see Using machine learning (ML) capabilities with Amazon Aurora.
Our model endpoint accepts a player action record in a multi-player session. The record includes the action value, the average velocity, and average acceleration of the player move. The idea is that the call to the model is done via a SQL query triggered by the customer care app. The app queries the MySQL view v_actions_m_value_accel and m_action_encoding. The following query scans unclassified game records (class is null) and assumes that unclassified game events are the latest to be scanned:
The model query returns suspicious player moves as classified by our model, when cls>0. It’s a good starting point for further investigation of these players, but not necessarily the final determination that these are bots. We also use m_action_encoding, which is populated in the notebook after encoding (OneHotEncoding) the m_action values for better model accuracy.
A customer care representative could now call other models against these suspicious users to get a more accurate picture. For example, the customer care application might use a player microtransaction classifier or player auth activities using the following MySQL queries:
Cheat detection is an ongoing game of cat and mouse between us and the cheaters. As soon as they discover the methods we employ, they’ll surely learn to overcome them. For example, they write bots that produce less predictable player ticks, so the ML problem morphs and requires continuous data exploration. Detecting bots with the players’ actions requires us to look at game session snippets with all their attributes, such as a series of player ticks, activities, and values of a specific player. The supervised algorithms employ a logistic function to model the probability of a bot or a human. We could also explore other model options, such as Naive Bayes or KNN, which are outside the scope of this post.
How a customer care operator can use the model
Our solution implements a stored procedure that, given a player name, compiles the user’s recent game sessions, queries the model, and updates the classification prediction in the players’ session tables (ticks_session_sample). A customer care application can expose the cheating indications in the player page that a customer service representative can view. The representative could trigger calls to other models for detecting potential fraud, such as credit card or suspicious logins. After the representative is satisfied that the determination (human or bot) is correct, we can add the results into the next training of our ML model.
Try it yourself
You can try this end-to-end solution, but for those who don’t have time to set up the EKS cluster, deploy the game server, and train the model, we offer a sample dataset that we trained. If you choose to use the sample dataset, skip steps 1, 2, 4, and 5. You can load the file to your Aurora MySQL and train the model as instructed in step 6.
- Create an EKS cluster with a worker node group.
- Deploy the game server.
- Create an Aurora MySQL cluster and allow SageMaker calls from the database.
- Configure the data pipeline:
-
- Enable player network datagrams.
- Create Kinesis Data Firehose.
- Deploy FluentBit to stream the player actions to Kinesis Data Firehose.
- Play the game, a lot! Then play it against bots.
- Train and deploy the model.
- Play another game with bot and call the function.
Hopefully, you catch the bot!
Conclusion
ML adoption is a complete process that includes integration into data sources, model training, inference, and continuous updating and refinement. As you build or move your applications to the cloud, make sure to take advantage of the ML services and tools AWS built. We encourage you to read recent announcements about these topics, including several at AWS re:Invent 2020. If you’re not ready to build your own models, you can still work with a data scientist or use the many pre-built models available.
About the Authors
 Yahav Biran is a Solutions Architect in AWS, focused on game tech at scale. Yahav enjoys contributing to open-source projects and publishes in the AWS blog and academic journals. He currently contributes to the K8s Helm community, AWS databases and compute blogs, and Journal of Systems Engineering. He delivers technical presentations at technology events and works with customers to design their applications in the cloud. He received his PhD (Systems Engineering) from Colorado State University.
Yahav Biran is a Solutions Architect in AWS, focused on game tech at scale. Yahav enjoys contributing to open-source projects and publishes in the AWS blog and academic journals. He currently contributes to the K8s Helm community, AWS databases and compute blogs, and Journal of Systems Engineering. He delivers technical presentations at technology events and works with customers to design their applications in the cloud. He received his PhD (Systems Engineering) from Colorado State University.
 Yoav Eilat is Senior Product Manager for Amazon RDS and Amazon Aurora. He joined AWS in 2016 after holding product roles for several years at Oracle and other technology companies. At AWS, he managed the launches of Aurora PostgreSQL, Aurora Serverless, Aurora Global Database, and other major features. Yoav currently focuses on new capabilities for the MySQL and PostgreSQL database engines.
Yoav Eilat is Senior Product Manager for Amazon RDS and Amazon Aurora. He joined AWS in 2016 after holding product roles for several years at Oracle and other technology companies. At AWS, he managed the launches of Aurora PostgreSQL, Aurora Serverless, Aurora Global Database, and other major features. Yoav currently focuses on new capabilities for the MySQL and PostgreSQL database engines.