AWS Database Blog
Amazon RDS: Snapshot, restore, and recovery demystified
Amazon Relational Database Service (Amazon RDS) is a managed relational database service offering. The managed service automation of Amazon Web Services (AWS) takes care of installation, storage provisioning, storage management, OS and database patching, and snapshot and restore of database instances. Offloading the undifferentiated heavy lifting of database infrastructure management to AWS helps you focus efforts where you can make the biggest difference in your business.
In this post, we dive deep into how snapshot and recovery works for an Amazon RDS instance.
Overview of Amazon RDS snapshots
Amazon RDS snapshots are taken at the storage volume level and are independent of native engine backup tools like RMAN for Oracle or mysqldump for MySQL instances. Snapshots of Amazon RDS volumes are incremental, and automation decides which blocks are to be backed up when a snapshot is running. Each snapshot contains all information needed to restore data to a new volume. Amazon RDS snapshots are stored in a secured and encrypted AWS managed Amazon Simple Storage Service (Amazon S3) buckets for a user-specified retention. You can use snapshot-specific API calls to access the snapshots for copy and restore operations. You can create a new instance from a database snapshot whenever you desire. Although database snapshots serve operationally as full backups, you are billed only for incremental storage use.
There are two types of Amazon RDS snapshots: automated and manual. An automated snapshot gets triggered during a daily backup window, whereas a manual snapshot can be initiated any time using the Amazon RDS create snapshot API. Preferred backup window can be set while creating the DB instance or later you can modify the preferred backup window to a time you would want backup to run. A default 30-minute backup window is set if you don’t choose preferred backup window during instance creation.
To modify the Preferred backup window via AWS console perform below steps.
- Go to instance page
- Choose Modify
- Go to the “Additional Configuration” section
- Under “Backup” section, select the “Choose a window” radio button
- Specify the desired Start time and Duration
- Verify if the time and duration are as expected
- Choose Continue
- Now you can choose to “Schedule modifications” immediately or during the next maintenance window.
To modify the preferred backup window via AWS CLI, you can execute the below command, replace <<mytestinstance>> with the name of your instance. Below CLI command sets the backup window to 30 minutes starting at 19:00 UTC, you could change it your preferred time.
For Amazon RDS in a Multi-AZ setup, the data volume snapshot runs on Multi-AZ standby instance (except for RDS for SQL Server). Similar to how the primary instance has data volumes, the Multi-AZ standby instance has its own data volumes.
The following is a diagram of how Amazon RDS Single-AZ snapshot functions.
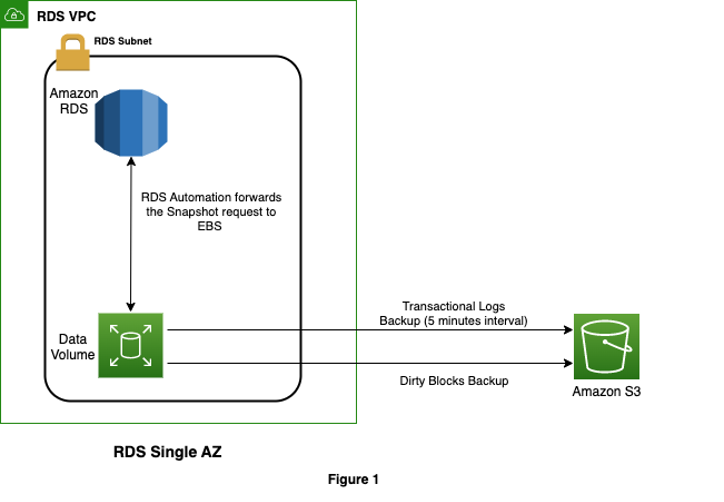
The following is a basic diagram of how Amazon RDS Multi-AZ snapshot works.
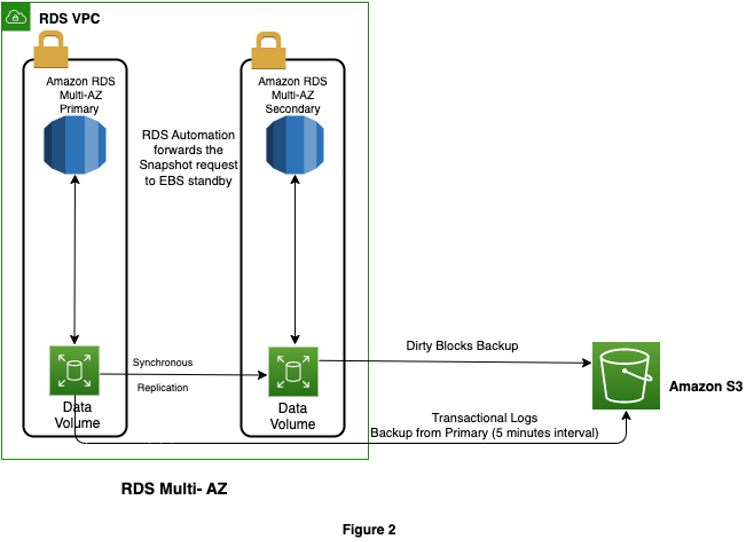
Irrespective of Single-AZ or Multi-AZ configuration, transaction logs are backed up every 5 minutes from the primary instance when automated snapshot is enabled.
If you are looking for a fully-managed service to centralize and automate data protection across AWS services, then we encourage to you explore AWS Backup. AWS Backup supports features such as backup frequency, automated lifecycle management, separate backup access policies, immutable backups with AWS Backup Vault Lock, and compliance monitoring with AWS Backup Audit Manager.
In this post, we focus on how Amazon RDS snapshot and restore are managed via Amazon RDS Automation and Amazon RDS snapshot specific APIs. Let’s get into the details of how snapshot and restore works in Amazon RDS.
Automated snapshot
You can use an automated snapshot to restore an instance to the time when the snapshot was taken. You can also use it to perform a point-in-time restore to any time within the retention window.
The following screenshot of the Amazon RDS console shows how you can restore an automated snapshot to the time when it was taken.
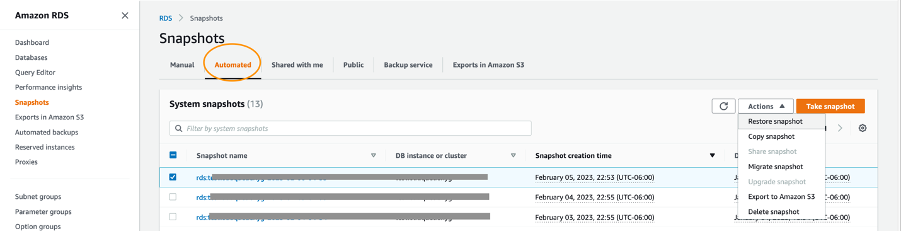
Manual snapshot
Manual snapshots are user-initiated snapshots that you can use to restore only to the time when the snapshot was taken. Restoring a manual snapshot is like restoring the automated snapshot. The difference is that you can take a manual snapshot any time, but an automated snapshot is initiated only during a scheduled window. The manual snapshot doesn’t get deleted until it’s explicitly deleted via an API call, whereas automated snapshots are deleted based on the automated snapshot retention window.
Backup times for Multi-AZ failover
After a Multi-AZ failover, why does the first Amazon RDS snapshot take longer?
As discussed in the Amazon RDS snapshot architecture, a snapshot of an Amazon RDS instance volume is always taken from the Multi-AZ standby instance and is incremental. The Amazon Elastic Block Store (Amazon EBS) volumes for the Multi-AZ standby instance are different from those for the Multi-AZ primary instance; therefore, if a previous snapshot from volumes of the new Multi-AZ standby isn’t available or was taken a long time ago, a snapshot has to back up all the blocks that aren’t backed up from this volume, which can take time based on the volume of changes to the data blocks.
Point-in-time recovery
You can initiate point-in-time recovery (PITR) only when automated snapshots are enabled. With PITR, the Amazon RDS instance is restored from an automated snapshot of database volumes, and then transaction logs are applied to bring the instance to the time specified in the API call. You can retain the automated snapshots for a maximum of 35 days.
While performing PITR or restore of an automated or manual snapshot, a new instance is created.
Sometimes, Amazon RDS PITR takes significant time to complete, and sometimes PITR completes quickly. What’s the reason behind that?
PITR of an Amazon RDS instance has two components: restore and replay of transaction logs. The time required to perform the volume restore is standard. The amount of time required to replay transaction logs is dependent on the number and size of transactions logs that exist between the time that the previous automated snapshot was taken and the time specified in the PITR API call. Therefore, the difference during PITR of the same Amazon RDS instance during different a PITR window is dependent on the duration needed to replay the transaction logs.
Let’s assume that the automated snapshot of the Amazon RDS instance is taken at 7:00 PM daily. If you perform PITR of the Amazon RDS instance to January 26, 2023, 10:00 PM, the Amazon RDS automation will restore from the snapshot taken on January 26 at 7:00 PM and apply all the transaction logs serially until January 26, 10:00 PM. Amazon RDS automation needs to apply 3 hours of transaction logs that were generated between 7:00 PM and 10:00 PM to bring the PITR instance to the time specified in the API call. Therefore, the more transaction logs that need to be applied, the longer it will take for recovery to complete.
PITR also could take longer to complete depending on the contents of the transaction logs applied as part of instance recovery.
Hydration after restore
There is hydration after restore until all the blocks from the snapshot S3 bucket are moved to the data volume. How can this be mitigated?
For Amazon RDS instances that are restored from snapshots (automated and manual), the instances are made available as soon as the needed infrastructure is provisioned. However, there is an ongoing process that continues to copy the storage blocks from Amazon S3 to the EBS volume; this is called lazy loading. While lazy loading is in progress, I/O operations might need to wait for the blocks being accessed to be first read from Amazon S3. This causes increased I/O latency, which doesn’t always have an impact for applications using the Amazon RDS instance. If you want to reduce any slowness due to hydration, read all the data blocks as soon as the restore is complete. The following are options available for different engines to reduce the time taken for hydration to complete. Note that these options are engine-native commands and therefore affect only the primary instance of Multi-AZ Amazon RDS.
In Amazon RDS for Oracle, the following options are available:
- Run a database-level validate command using
rdsadmin.rdsadmin_rman_util.validate_databasepackage. Parallelism can be modified based on the number of vCPU to avoid throttling. - Perform a quick Data Pump full export with parallelism based on engine licensing.
- Perform an explicit select on all the large or most heavily used tables individually with parallel hint as applicable.
In Amazon RDS for PostgreSQL, the following options are available:
- Use the
pg_prewarmshared library module to read through all the tables - Use the
pg_dumputility with jobs and data-only parameters to perform an export of all application schemas - Perform an explicit select on all the large and heavily used tables individually with parallelism
In Amazon RDS for MySQL, the following options are available:
- Perform various selects on all large and heavily used tables in parallel
- Use
mysqldumpto export all tables
In Amazon RDS for SQL Server, the following option is available:
- Perform a manual select on all large and heavily used tables with parallelism
Summary
In this post, we explained how backup and restore works in Amazon RDS, the factors that contribute to increased time for backup and restore, and how to reduce them. We hope that this post has provided much-needed answers to your questions about working with Amazon RDS snapshot and restore operations, and we invite you to try some database restores using the tips we’ve provided.
We welcome your feedback. If you have any questions or suggestions, please leave them in the comments section.
About the Authors
 Arnab Saha
is a Senior Database Specialist Solutions Architect at AWS. Arnab specializes in Amazon RDS, Amazon Aurora, and Amazon EBS. He provides guidance and technical assistance to customers, enabling them to build scalable, highly available, and secure solutions in the AWS Cloud.
Arnab Saha
is a Senior Database Specialist Solutions Architect at AWS. Arnab specializes in Amazon RDS, Amazon Aurora, and Amazon EBS. He provides guidance and technical assistance to customers, enabling them to build scalable, highly available, and secure solutions in the AWS Cloud.
 Deepak Mani works as Cloud Support DBA II in Amazon Web Services. He is a Subject Matter Expert for Amazon RDS for Oracle and Amazon RDS. Deepak has 15 years of experience working with relational databases. At AWS, he works primarily on Premium Support tickets and internal escalations created for Amazon RDS for Oracle, Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL, and AWS DMS.
Deepak Mani works as Cloud Support DBA II in Amazon Web Services. He is a Subject Matter Expert for Amazon RDS for Oracle and Amazon RDS. Deepak has 15 years of experience working with relational databases. At AWS, he works primarily on Premium Support tickets and internal escalations created for Amazon RDS for Oracle, Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL, and AWS DMS.