AWS Database Blog
Category: Amazon Aurora
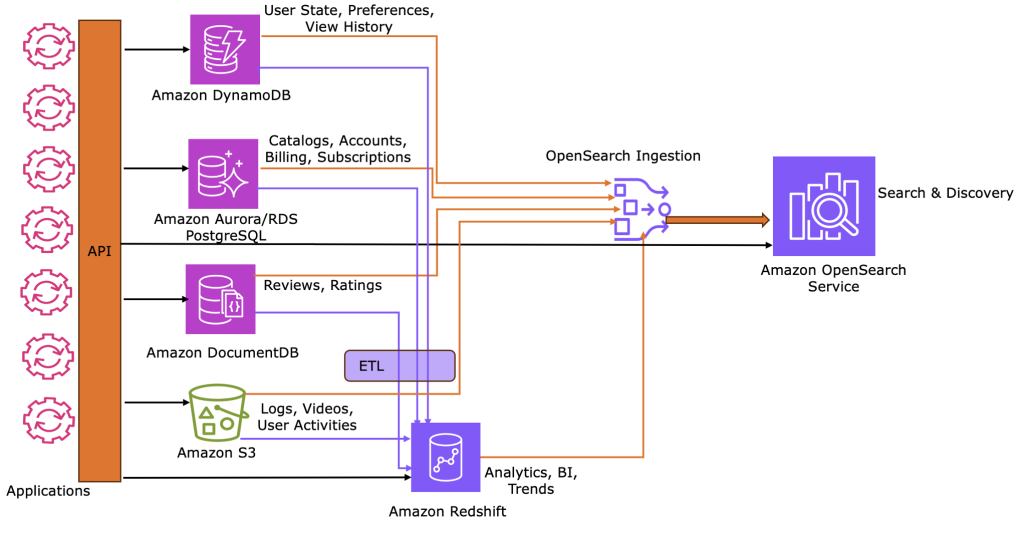
How to build unified JSON search solutions in AWS
Using a movie streaming reference architecture, this post shows how to implement and sync operational, analytical, and search JSON workloads across AWS services. This pattern provides a scalable blueprint for any use case requiring multi-modal JSON data capabilities.

PostgreSQL logical replication: How to replicate only the data that you need
In this post, we show how logical replication with fine-grained filtering works in PostgreSQL, when to use it, and how to implement it using a realistic healthcare compliance scenario. Whether you’re running Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL, or a self-managed PostgreSQL database on an Amazon EC2 instance, the approach is the same.

Optimize full-text search in Amazon RDS for MySQL and Amazon Aurora MySQL
In this post, we show you how to optimize full-text search (FTS) performance in Amazon RDS for MySQL and Amazon Aurora MySQL-Compatible Edition through proper maintenance and monitoring. We discuss why FTS indexes require regular maintenance, common issues that can arise, and best practices for keeping your FTS-enabled databases running smoothly.

Working with identity columns and sequences in Aurora DSQL
Amazon Aurora DSQL now supports PostgreSQL-compatible identity columns and sequence objects, so developers can generate unique integer identifiers with configurable performance characteristics optimized for distributed workloads. In distributed database environments, generating unique, sequential identifiers is a fundamental challenge: coordinating across multiple nodes creates performance bottlenecks, especially under high concurrency workloads. In this post, we show you how to create and manage identity columns for auto-incrementing IDs, selecting between identity columns and standalone sequence objects, and improving cache settings while choosing between UUIDs and integer sequences for your workload requirements.

Automated parameter and option group change monitoring in Amazon RDS and Amazon Aurora
In this post, you will learn how to build a serverless monitoring solution sending detailed alerts whenever Amazon RDS parameter groups are modified, including which databases are affected and whether a restart is required.

Migrate Cloud SQL for MySQL to Amazon Aurora and Amazon RDS for MySQL Using AWS DMS
In this post, we demonstrate how to migrate from Cloud SQL for MySQL 8+ to Amazon RDS for MySQL 8+ or Amazon Aurora MySQL–Compatible using AWS DMS over an AWS Site-to-Site VPN. We cover preparing the source and target environments, exemplifying cross-cloud connectivity, and setting up DMS tasks.

Replicate spatial data using AWS DMS and Amazon RDS for PostgreSQL
In this post, we show you how to migrate spatial (geospatial) data from self-managed PostgreSQL, Amazon RDS for PostgreSQL, or Amazon Aurora PostgreSQL-Compatible Edition to Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL using AWS DMS. Spatial data is useful for applications such as mapping, routing, asset tracking, and geographic visualization. We walk through setting up your environment, configuring AWS DMS, and validating the successful migration of spatial datasets.

Use default encryption at rest for new Amazon Aurora clusters
In this post, you learn how Amazon Aurora now provides encryption at rest by default for all new database clusters using AWS owned keys. You’ll see how to verify encryption status using the new StorageEncryptionType field, understand the impact on new and existing clusters, and explore migration options for unencrypted databases.
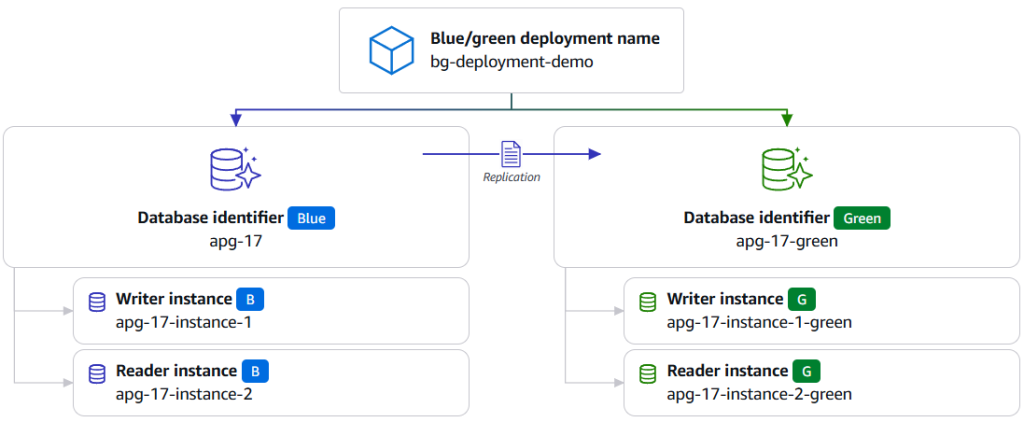
Achieve near-zero downtime database maintenance by using blue/green deployments with AWS JDBC Driver
In this post we introduce the blue/green deployment plugin for the AWS JDBC Driver, a built-in plugin that automatically handles connection routing, traffic management, and switchover detection during blue/green deployment switchovers. We show you how to configure and use the plugin to minimize downtime during database maintenance operations during blue/green deployment switchovers.

Migrate relational-style data from NoSQL to Amazon Aurora DSQL
In this post, we demonstrate how to efficiently migrate relational-style data from NoSQL to Aurora DSQL, using Kiro CLI as our generative AI tool to optimize schema design and streamline the migration process.