AWS Database Blog
Category: Database
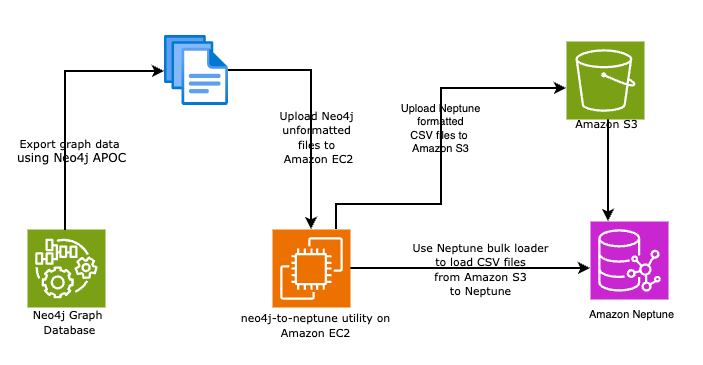
Automate your Neo4j to Amazon Neptune migration using the neo4j-to-neptune utility
In this post, we walk you through two methods to automate your Neo4j database to Neptune using the neo4j-to-neptune utility. This tool offers a fully automated end-to-end process in addition to a step-by-step manual process.
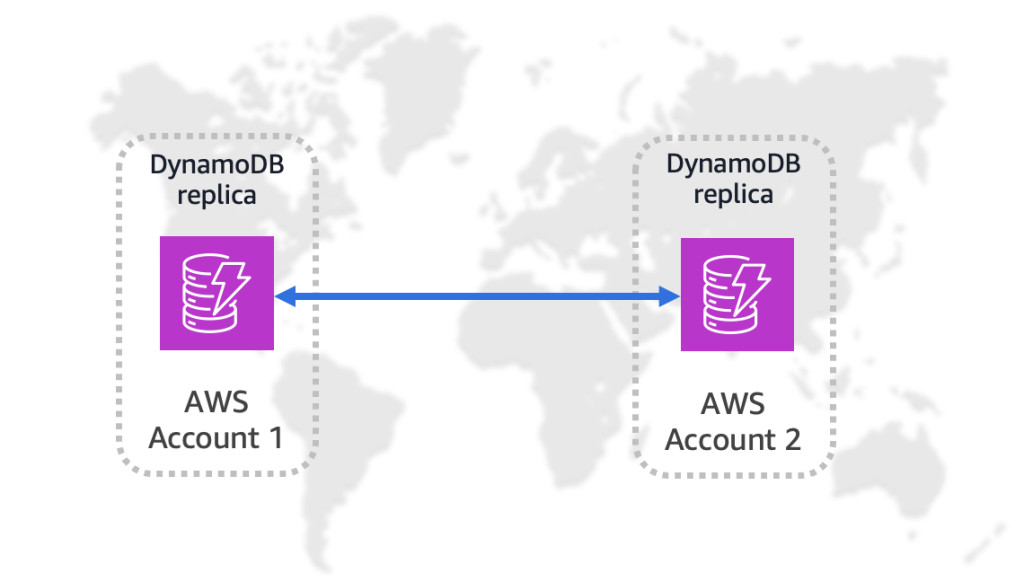
Amazon DynamoDB global tables now support replication across AWS accounts
Today, we’re announcing multi-account global tables for Amazon DynamoDB, which let you replicate DynamoDB table data across multiple AWS accounts and AWS Regions. This feature adds account-level isolation to global tables, so you can replicate DynamoDB table data across multiple AWS accounts and Regions for stronger isolation and resiliency. In this post, we show you how to create and configure a multi-account global table, and introduce use cases highlighting the value of using this feature.

Optimize LLM response costs and latency with effective caching
In this post, we talk about the benefits of caching in generative AI applications. We also elaborated on a few implementation strategies that can help you create and maintain an effective cache for your application.

Introducing pre-warming for Amazon Keyspaces tables
Amazon Keyspaces now supports the pre-warming feature to provide you with proactive throughput management. With pre-warming, you can set minimum warm throughput values that your table can handle instantly, avoiding the cold start delays that occur during dynamic partition splits. In this post, we discuss the Amazon Keyspaces pre-warming feature capabilities and demonstrate how it can enhance your throughput performance.

Managing IP address exhaustion for Amazon RDS Proxy
In this post, you will learn how to address IP address exhaustion challenges when working with Amazon RDS Proxy. For customers experiencing IP exhaustion with RDS Proxy, migrating to IPv6 address space can be an effective solution if your workload supports IPv6. This post focuses on workloads that cannot support IPv6 address space and provides an alternative approach using IPv4 subnet expansion. The solution focuses on expanding your Amazon Virtual Private Cloud (Amazon VPC) CIDR range, establishing new subnets, and executing a carefully planned switching of your proxy to a new subnet configuration.

Choosing the right code page and collation for migration from mainframe Db2 to Amazon RDS for Db2
In this post, you learn how to select the appropriate code page and collation sequence when migrating from Db2 mainframe (z/OS) to Amazon RDS for Db2 on Linux. You explore the differences between mainframe CCSIDs and Db2 LUW code pages, understand character compatibility requirements, and discover how to prevent data truncation and maintain consistent sorting behavior across platforms.
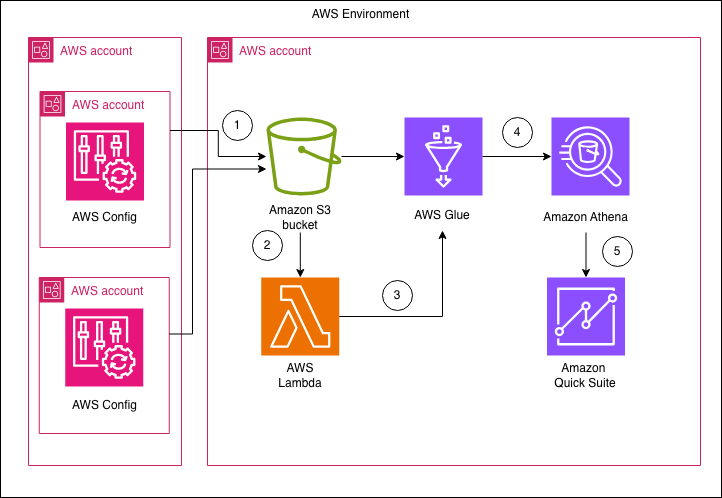
Enhance the visibility of Amazon RDS instances and configuration with AWS Config and Amazon Quick Suite
In this post, we show you how to build a centralized dashboard for monitoring Amazon RDS configurations across your organization by using AWS Config and Amazon Quick Suite. This solution delivers detailed insights across different areas, such as summary metrics, backup configurations, security posture, engine and support information, extended configurations, and resource tagging.

Strategies for upgrading Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL from version 13
In this post, we help you plan your upgrade from PostgreSQL version 13 before standard support ends on February 28, 2026. We discuss the key benefits of upgrading, breaking changes to consider, and multiple upgrade strategies to choose from.

How Tradeshift boosted operational efficiency and scalability with Amazon RDS
In 2023, Tradeshift migrated one of its core PostgreSQL databases from self-managed Amazon Elastic Compute Cloud (Amazon EC2) instances to Amazon Relational Database Service (Amazon RDS) for PostgreSQL. The decision followed mounting operational risks and performance limits that made the existing setup increasingly unsustainable. Tradeshift needed a managed solution that could reduce downtime risk, improve observability, and simplify ongoing operations. Amazon RDS met those requirements. In this post, we explain why we migrated to Amazon RDS, how we executed the migration, and highlight the invaluable benefits it delivered in terms of safety, flexibility, and audit compliance.

MaiCoin case study: Blue/green upgrade from Amazon ElastiCache Redis to Valkey
MaiCoin is a leading cryptocurrency exchange and brokerage platform in Taiwan. The MaiCoin platform previously ran on a set of Amazon ElastiCache deployment clusters on Redis OSS. This post explores MaiCoin’s practical approaches using RedisShake for migrating from Amazon ElastiCache for Redis OSS to Amazon ElastiCache for Valkey using blue/green deployment strategies.