AWS Database Blog
Category: Technical How-to

Managing IP address exhaustion for Amazon RDS Proxy
In this post, you will learn how to address IP address exhaustion challenges when working with Amazon RDS Proxy. For customers experiencing IP exhaustion with RDS Proxy, migrating to IPv6 address space can be an effective solution if your workload supports IPv6. This post focuses on workloads that cannot support IPv6 address space and provides an alternative approach using IPv4 subnet expansion. The solution focuses on expanding your Amazon Virtual Private Cloud (Amazon VPC) CIDR range, establishing new subnets, and executing a carefully planned switching of your proxy to a new subnet configuration.

Choosing the right code page and collation for migration from mainframe Db2 to Amazon RDS for Db2
In this post, you learn how to select the appropriate code page and collation sequence when migrating from Db2 mainframe (z/OS) to Amazon RDS for Db2 on Linux. You explore the differences between mainframe CCSIDs and Db2 LUW code pages, understand character compatibility requirements, and discover how to prevent data truncation and maintain consistent sorting behavior across platforms.
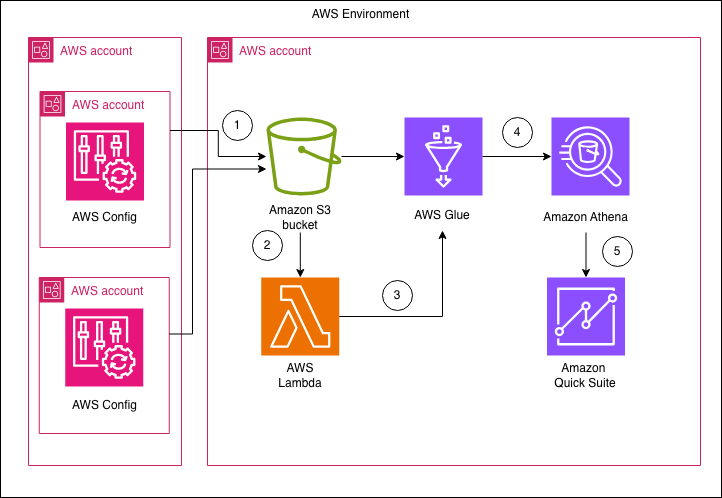
Enhance the visibility of Amazon RDS instances and configuration with AWS Config and Amazon Quick Suite
In this post, we show you how to build a centralized dashboard for monitoring Amazon RDS configurations across your organization by using AWS Config and Amazon Quick Suite. This solution delivers detailed insights across different areas, such as summary metrics, backup configurations, security posture, engine and support information, extended configurations, and resource tagging.

Analyze JSON data efficiently with Amazon Redshift SUPER
Amazon Redshift transforms how organizations analyze JSON data by combining the analytical power of a columnar data warehouse with robust JSON processing capabilities. By using Amazon Redshift SUPER datatype, you can efficiently store, query, and analyze complex hierarchical data alongside traditional structured data without sacrificing performance. This post focuses on JSON features of Amazon Redshift.

MaiCoin case study: Blue/green upgrade from Amazon ElastiCache Redis to Valkey
MaiCoin is a leading cryptocurrency exchange and brokerage platform in Taiwan. The MaiCoin platform previously ran on a set of Amazon ElastiCache deployment clusters on Redis OSS. This post explores MaiCoin’s practical approaches using RedisShake for migrating from Amazon ElastiCache for Redis OSS to Amazon ElastiCache for Valkey using blue/green deployment strategies.
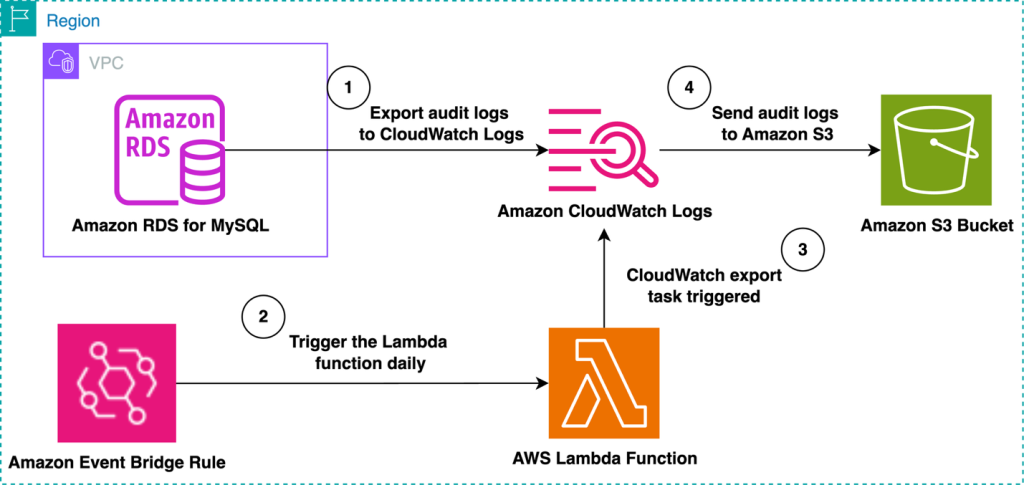
Automate the export of Amazon RDS for MySQL or Amazon Aurora MySQL audit logs to Amazon S3 with batching or near real-time processing
Amazon RDS for MySQL and Amazon Aurora MySQL provide built-in audit logging capabilities, but customers might need to export and store these logs for long-term retention and analysis. Amazon S3 offers an ideal destination, providing durability, cost-effectiveness, and integration with various analytics tools. In this post, we explore two approaches for exporting MySQL audit logs to Amazon S3: either using batching with a native export to Amazon S3 or processing logs in real time with Amazon Data Firehose.
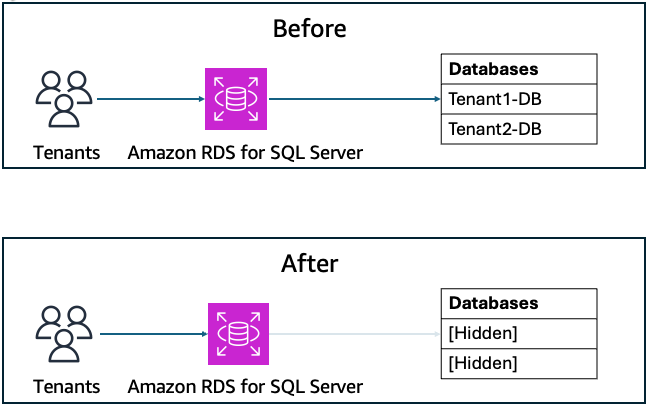
Control database name visibility in Amazon RDS for SQL Server instances
In Amazon Relational Database Service (Amazon RDS) for SQL Server, database visibility is configured using a dedicated stored procedure. In this post, we demonstrate tenant isolation at the visibility level, preventing tenants from seeing database names belonging to other customers while maintaining their access to their own resources. This solution addresses an important architectural consideration in multi-tenant SQL Server environments where database names might reveal tenant information. By using the Amazon RDS for SQL Server custom stored procedure msdb.dbo.rds_manage_view_db_permission, users can effectively control database visibility on a per-login basis while maintaining full application functionality.

Using the shared plan cache for Amazon Aurora PostgreSQL
In this post, we discuss how the Shared Plan Cache feature of the Amazon Aurora PostgreSQL-Compatible Edition can significantly reduce memory consumption of generic SQL plans in high-concurrency environments.

AWS Organizations now supports upgrade rollout policy for Amazon Aurora and Amazon RDS automatic minor version upgrades
AWS Organizations now supports an upgrade rollout policy, a new capability that provides a streamlined solution for managing automatic minor version upgrades across your database fleet. This feature supports Amazon Aurora MySQL-Compatible Edition and Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS database engines MySQL, PostgreSQL, MariaDB, SQL Server, Oracle, and Db2. It eliminates the operational overhead of coordinating upgrades across hundreds of resources and accounts while validating changes in less critical environments before reaching production. In this post, we explore how upgrade rollout policy works, its key benefits, and how you can use it to implement a systematic approach to database maintenance across your organization.
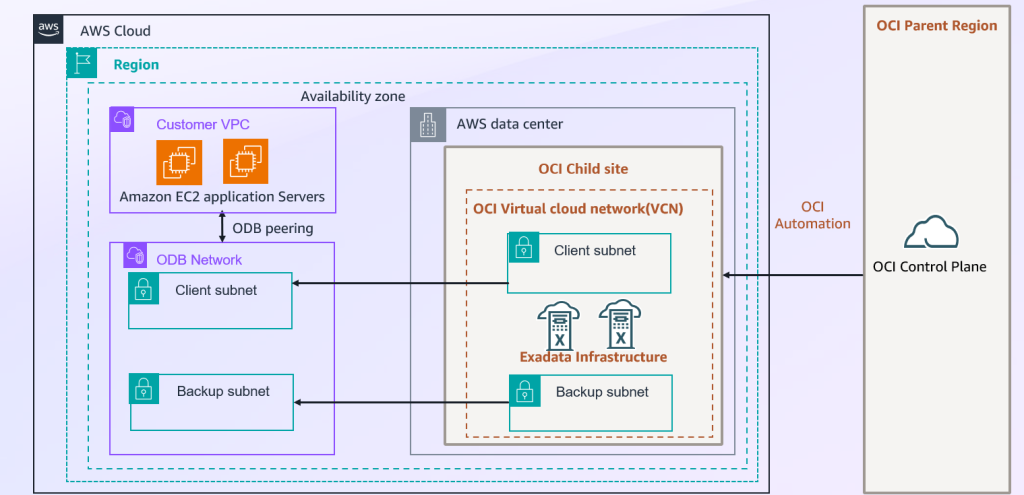
Provision Oracle Database@AWS stack using AWS CloudFormation
In this post, we explain how to set up key components of Oracle Database@AWS offering including ODB network, Oracle Exadata infrastructure, Exadata VM clusters and Autonomous VM clusters using AWS CloudFormation template.