AWS Database Blog
Cross-Engine Database Replication Using AWS Schema Conversion Tool and AWS Database Migration Service
Prahlad Rao is a solutions architect at Amazon Web Services.
Customers often replicate databases hosted on-premises to the AWS Cloud as a means to migrate database workloads to AWS, or to enable continuous replication for database backup and disaster recovery. You can both migrate and perform continuous replication on the AWS Cloud with AWS Database Migration Service (AWS DMS).
Although moving from on-premises to the cloud using the same database engine is a common pattern, increasingly customers also use different engines between source and target when replicating. This pattern especially occurs where the source is a commercial database engine and the target is open source. Such an approach can save on licensing costs. In other use cases, the target database might be used as read-only for a reporting application that is compatible with a certain database engine, or the application team is comfortable using an open source database for their needs. Or the customer might be migrating from a commercial database to an open source database on the AWS Cloud for cost and flexibility purposes. This blog post will walk you through the process of replicating a Microsoft SQL Server database to PostgreSQL using AWS Schema Conversion Tool (AWS SCT) and AWS DMS.
AWS DMS helps you migrate databases to AWS with relative ease and security. The source database remains fully operational during the migration, minimizing downtime to applications that rely on the database. The service supports homogenous migrations (like to like databases) and also heterogeneous migrations (between database platforms such as Oracle to Amazon Aurora or SQL Server to MySQL). AWS DMS can also be used for continuous data replication with high availability.
AWS SCT makes heterogeneous database migrations easier by automatically converting source database schema. AWS SCT also converts the majority of custom code, including views and functions, to a format compatible with the target database.
Heterogeneous database replication is a two-step process:
- Use AWS SCT to convert the source database schema (from SQL Server) to a format compatible with target database, in this case PostgreSQL.
- Replicate data between source and target using AWS DMS.
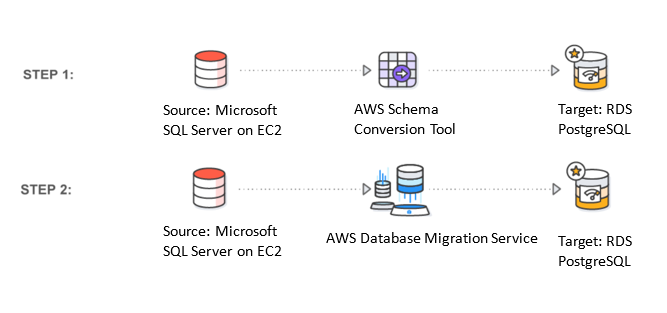
Step 1: Convert schema from source to target database
AWS Schema Conversion Tool is a stand-alone application that provides a project-based user interface and is available for Microsoft Windows, Mac OS X, and Linux versions. You can find detailed installation instructions in the AWS documentation, so I won’t go into all the details, but high-level steps are outlined following:
- Download and install the AWS SCT tool for your operating system.
- Install the required JDBC drivers for source and target database engines on the system that has AWS SCT installed.
- Once required JDBC drivers have been downloaded, provide the location of driver files to SCT as shown following, under Settings, Global Settings, Drivers.

- Create an SCT project and connect to source and target databases. SCT needs access to both source and target database engines. You can use an existing user on the database that already has the required permissions or create a new user for SCT to access the schema. The user should have necessary permissions to read the schema as required by SCT. The permissions should also provide read-only access to the views and system tables.
- Choose New Project from the File menu. Under source and target database engine, select Microsoft SQL Server and PostgreSQL respectively.

- Connect to the source and target database engines. Our source database SQL Server 2014 is on an Amazon EC2 instance, and the target database is Amazon RDS for PostgreSQL. Although we’ve used an EC2 instance as a source for Microsoft SQL database in this blog post to demonstrate functionality, you can use the same procedure to replicate a source database that is hosted in your own data center. Make sure the target database is created ahead of time. Choose Connect for Microsoft SQL Server, fill in the required details, and choose Test Connection.

- For the target database, choose Connect to PostgreSQL, fill in the required details, and choose Test Connection.

Now that the source and target databases are accessible from AWS SCT, we will begin converting schema that are compatible with the target database. Note that schema on the source database aren’t modified, but rather a new schema with a compatible structure is created on the target database. At the same time, users can continue to access the source database without any interruption.

Select the source database on the left and refresh the database by right-clicking on the database to ensure we are connected to the latest schema set. In our case, it’s AdventureWorks2014. You also notice schema listed in the database. With SCT, you can replicate specific schema or an entire database, giving you the flexibility to migrate or replicate part of the dataset from source to target. This flexibility is useful if you want to fan out into multiple target databases from one source database. We will replicate the HumanResources schema and the dataset associated with that schema here.
Select the HumanResources schema, right-click, and choose Convert Schema.

The schema will now be converted. Notice the new schema on the target PostgreSQL database on the right, following.

Expand source and target database schema, and notice SCT has used the appropriate format at the target database. Although the source SQL Server schema lists Tables, Views, and Procedures, the target PostgreSQL schema lists Tables, Views and Functions.

For schema that were not converted automatically using SCT, you can manually create appropriate schema on the target. This approach avoids the need to manually create the entire schema structure on the target database.
The database migration assessment report provides important information about schema conversion. It summarizes all conversion tasks and details the action items for the schema that can’t be converted to the target DB engine. The report can also help you analyze requirements for migrating to the cloud and for changing license type. You can find more details on creating this assessment report in the AWS documentation, and also in this nice blog post.
At this point, the schema is only reflected on the target database and has not been applied yet. Let us go ahead and apply it to the target database. To do this, select the schema on the target database, right-click, and choose Apply to database.

Let’s confirm that the schema has been applied on the target by logging into the target RDS PostgreSQL database. I’m using a psql client on my Mac to access the target database:
Psql –h <database host name RDS endpoint> -p 5432 –U <username> <database name>

Notice the adventureworks2014_humanresources schema, created by SCT. Let’s also verify the tables as part of the schema and look at the structure of a table:

Now that we’ve migrated schema from source to target, it’s time to use DMS to actually replicate data from the source to the target database.
Step 2: Replicate data from source to target database
To replicate databases using AWS Database Migration Service, we’ll need to provision a replication instance to perform the tasks and replicate data from source to target database. The required size of the instance varies depending on the amount of data needed to replicate or migrate. You can find additional information about choosing replication instance in the AWS documentation. We’ll use a dms.t2.medium instance for our replication.
On the DMS console, choose Replication Instances and Create replication instance as follows. The replication instance should be able to connect to both source and target databases.

When the replication instance has been created, create source and target endpoints to connect to the source and target database respectively. The source is SQL Server on an EC2 instance:

Similarly, set target endpoint details to our RDS PostgreSQL database:

Make sure to test the connection for both the endpoints. The replication instance should be able to connect successfully to both source and target database endpoints for the replication to be successful.
Finally, we can create a replication task to replicate data from the source to target database, and also to replicate changes as they happen on the source database.
With AWS services, you can not only use our console for provisioning services, but also the AWS Command Line Interface (AWS CLI) to automate and script the migration process. Let me show you how easy it is to use the CLI to create the task and script the migration process.
Because we’ve already migrated schema to the target database, we need to make sure to specify the same schema that was created on the PostgreSQL database. Before we run the create-replication-task AWS CLI command, we need to specify important task settings and table mappings files using JSON as shown following. The task_settings.json file specifies target schema to be used when replicating data and other parameters to determine how large objects are managed. Because we’re replicating data here and not migrating, we need to ensure ApplyChangesEnabled is set to true, which ensures the task will keep target tables up-to-date by applying changes using change data capture (CDC). The other parameter will be DO_NOTHING on the table prep mode, which means data and metadata of the existing target table are not affected. The task_settings.json file for our replication task follows:
{
"TargetMetadata": {
"TargetSchema": "adventureworks2014_humanresources",
"SupportLobs": true,
"FullLobMode": false,
"LobChunkSize": 64,
"LimitedSizeLobMode": true,
"LobMaxSize": 32
},
"FullLoadSettings": {
"FullLoadEnabled": false,
"ApplyChangesEnabled": true,
"TargetTablePrepMode": "DO_NOTHING",
"CreatePkAfterFullLoad": false,
"StopTaskCachedChangesApplied": false,
"StopTaskCachedChangesNotApplied": false,
"ResumeEnabled": false,
"ResumeMinTableSize": 100000,
"ResumeOnlyClusteredPKTables": true,
"MaxFullLoadSubTasks": 8,
"TransactionConsistencyTimeout": 600,
"CommitRate": 10000
},
"Logging": {
"EnableLogging": false
},
"ControlTablesSettings": {
"ControlSchema":"",
"HistoryTimeslotInMinutes":5,
"HistoryTableEnabled": false,
"SuspendedTablesTableEnabled": false,
"StatusTableEnabled": false
},
"StreamBufferSettings": {
"StreamBufferCount": 3,
"StreamBufferSizeInMB": 8
},
"ChangeProcessingDdlHandlingPolicy": {
"HandleSourceTableDropped": true,
"HandleSourceTableTruncated": true,
"HandleSourceTableAltered": true
}
}You can find additional details on the task_settings.json file in the AWS documentation.
The table_mappings.json file specifies tables from a particular source schema that you want to replicate to the target endpoint. Table mappings offer a lot of flexibility to migrate specific tables and datasets to a target. Migration can also be rule-based on datasets that you want to filter when replicating data. These approaches provide powerful capabilities to granularly replicate datasets across database engines. For additional details, see the AWS documentation.
In our case, because we’re only replicating HumanResources data, we will specify that in our table_mappings.json file. The table-name value % tells DMS to replicate all tables for that particular schema.
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "HumanResources",
"table-name": "%"
},
"rule-action": "include"
}
]
}Now that we have the required settings to begin replication, we’ll use create-replication-task to replicate data. Because we’re replicating data as changes happen to source database, full-load-and-cdc should be selected as migration type in our command. Doing this will ensure both initial load and ongoing changes are replicated.
aws dms create-replication-task --replication-task-identifier sql-replicate --source-endpoint-arn arn:aws:dms:us-west-2:904672585901:endpoint:JT6WECWJJ4YSO7AKSISBJEJD6A --target-endpoint-arn arn:aws:dms:us-west-2:904672585901:endpoint:CA2UW3DRV5KI3FG45JW45ZEZBE --replication-instance-arn arn:aws:dms:us-west-2:904672585901:rep:LNQ6KQIT52DIAWLFQU5TCNXY4E --migration-type full-load-and-cdc --replication-task-settings 'file://task_settings.json' --table-mappings 'file://table_mappings.json'
Let’s verify task creation on the AWS Management Console:

The replication task is ready; let’s start it.
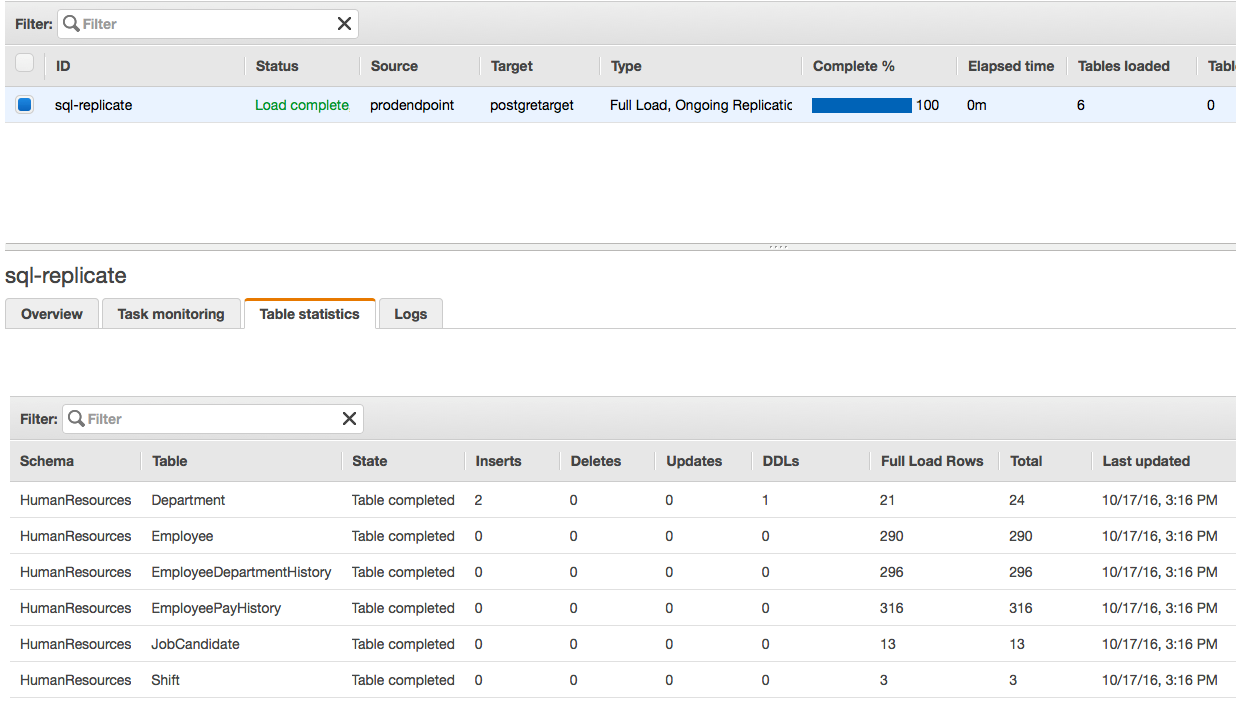
Once the task is run, the initial load will be completed, followed by any changes as they happen on the source database. On the task tab, choose Table statistics to verify tables and rows that were replicated to the target database with additional details, in our case HumanResources data.

Let’s verify data on the target PostgreSQL database:


Now that the source and target databases are being replicated, we’ll go ahead and insert a record into our source SQL Server database. Let’s insert Operations as Department and Group Name. Then we’ll verify changes are propagated to the target PostgreSQL database:

On the DMS console under Tasks, Table Statistics, we immediately notice an entry in the Inserts column into the Department table as follows:

We verify if the data is in fact on the target database. The new row is replicated to the target database. Notice Operations in the last row.

Now let’s modify the table to add a new column to Department table on the source SQL Server database to verify data definition language (DDL) updates are also being replicated. We’ll add a new column, GroupNumber:

Let’s confirm the DDL update that we just made on the DMS console. Notice the DDL column has incremented to 1:
Finally, let’s confirm on the target PostgreSQL database:

The target database has a new column, GroupNumber, added to the Department table.
Summary
By using the AWS Schema Conversion Tool (AWS SCT) and AWS Database Migration Service (AWS DMS), you can not only migrate databases across heterogeneous engines more easily but also perform continuous data replication. You can work with different database engines across source and target databases, giving you flexibility and lowering your cost to run your favorite database engines on the AWS Cloud, without complex migration tools or manual schema conversion methods.