AWS Database Blog
How Amazon Finance Technologies built an event-driven and scalable remittance service using Amazon DynamoDB
The Amazon Finance Technologies (FinTech) payment transmission team manages products for the Accounts Payable (AP) team, from invoices to the pay process. Their suite of services handles the disbursement process, from invoice generation to payment creation, to make sure that payment beneficiaries receive their payments. Amazon Business makes payments to a very diverse range of payees, including digital authors, application developers, retail vendors, utility companies, and tax companies. In 2022, the FinTech payment transmission team supported over 42 million remittances in 150 countries and over 60 currencies through various payment options such as ACH and wire transfers.
In this post, we show you how we built an extensible, resilient, and event-driven remittance notification service using Amazon DynamoDB as a key-value and document database that delivers millisecond latency at any scale.
Requirements
The disbursement lifecycle for remittance in Amazon includes several steps. It starts with invoice generation, which contains details such as the payee name and amount, then identifying the banking partner to know where to send the payments, and finally choosing an optimal payment method depending upon amount, country, and business type. Once the necessary information is collected, remittance instructions are sent to the banking partner. After the banking partner confirms the payment’s success, Amazon notifies the customer about the remittance’s completion. Timely notifications to customers upon successful payments help them to be aware of the payment status and minimize customer service inquiries. The volume of payments vary from day to day and region to region, so to maintain the accuracy of remittance delivery notifications, it was crucial for the service to scale as needed.
We identified the following key requirements:
- Seamless scalability
- Guaranteed processing and remittance notification
- Efficient error handling
- Simple maintenance
Our solution to our scaling problem
To build a robust remittance service, we needed to use two AWS compute and database technologies. For our compute needs, we opted for AWS Lambda, which is a serverless, event-driven compute service that integrates natively with DynamoDB. In this post, we focus more on our criteria for selecting the database and how we used its capabilities to design our system.
To decide which database service to use, we identified two main criteria. First, the database should scale seamlessly to handle our high volume of remittances and maintain timely notifications to our customers. Second, it was important to have schema flexibility to account for the various factors that can impact remittance details, such as payee type, transaction type, and country. We didn’t want to build a system with rigid schema where we have to define all the data elements upfront. That would be difficult to maintain in a rapidly changing finance landscape. With those considerations, we selected DynamoDB.
DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at scale. DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools. These features help remove the undifferentiated heavy lifting needed for our team to manage and scale the database, so we could focus on building our remittance application for our customers. We took advantage of the on-demand capacity of DynamoDB, which responds to thousands of requests per second without capacity planning, because the volume of payments can vary according to different factors, such as events like Prime Day and holiday seasons. It also helps keep our cost low while still maintaining optimal performance with pay-for-what-you-use pricing.
To enable payments for our customers, the necessary information is sent to banking partners for processing. After the banking partner successfully processes the payment, a confirmation message is sent. These messages include additional details such as the invoice and payment description. These two actions work with different systems, which led us to separate them into two different services, allowing each to perform its own task while following the same reusable pattern (which we discuss shortly). The separation of duties helps FinTech keep the solution simple and enables each service to scale independently.
We used the following two services for our application:
- Enrichment service – This service is responsible for receiving notifications from banking partners upon successful payment and enriching them with additional details
- Notification service – This service receives the enriched messages and is responsible for sending notifications to the customer
Enrichment service
The following diagram shows the enrichment service flow.
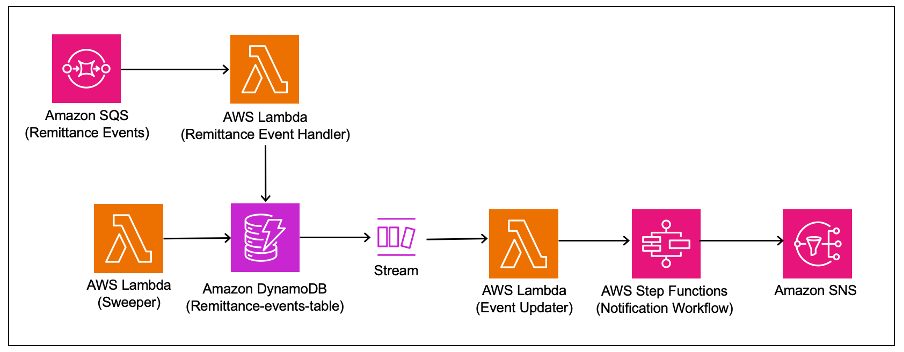
External partner notifications are received in the Remittance Events Queue of the Amazon Simple Queue Service (Amazon SQS) queue. These messages are consumed by a Lambda function and stored in a DynamoDB table. Insertions or update operations in DynamoDB trigger a change data capture (CDC) event through Amazon DynamoDB Streams (which is an ordered flow of information about changes to table items). We process specific CDC events using Lambda and trigger a workflow in AWS Step Functions. This workflow runs the necessary validations, enrichments, and transformations. The final enriched message is published to an Amazon Simple Notification Service (Amazon SNS) topic and is updated in the DynamoDB table. The SNS topic is used by the notification service to notify the customer.
The following diagram shows our table design.
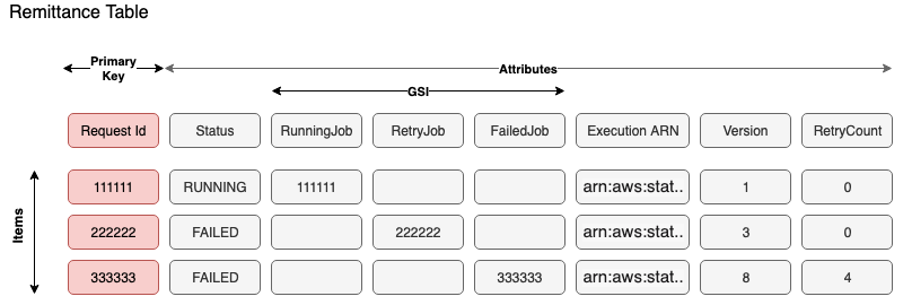
New records are inserted into DynamoDB using the request ID as the primary key and without a sort key due to the atomic nature and high cardinality of events. We also generate and store a Step Functions unique run ARN name for each message. Generating the ARN beforehand has two primary advantages: first, we use the ARN as a lookup to identify the correct record in DynamoDB to update the status when listening to Step Functions event updates. Second, we minimize accidental reruns and duplicate processing because Step Functions doesn’t allow runs with the same ARN. It follows the format "arn:aws:states:<region>:<account>:execution:<state machine name>:<Execution Name>". To generate this unique run name for each message, we use the request ID and other values that are mostly static. Multiple processes like the sweeper and notification workflow might access the same record to update the status. To enable optimistic locking, the versionId attribute is used, and we use the AWS SDK for DynamoDB for Java, which provides a convenient solution with the DynamoDBVersionAttribute annotation to effectively manage the version number.
Because one of FinTech’s requirements was to have improved error handling capabilities, we aimed to handle Step Functions workflow failures caused by several reasons such as dependent service (triggered by the workflow) outages. To achieve this, we introduced the internal design pattern in FinTech referred to as the sweeper pattern, which relies on global secondary indexes (GSIs) on the table.
For the remittance table, we created three GSI keys to identify jobs that were in their corresponding status: the Retry Job GSI, Failed Job GSI, and Running Job GSI. Whenever a workflow fails, the enrichment service updates the corresponding table item and modifies the Retry Job attribute with the same value as the request ID. To rerun the failed messages, a Lambda function called the sweeper is invoked and scans the GSI key attribute Retry Job to find failed items that haven’t reached the retry threshold. Because GSIs are sparse, they only contain items with values in those attributes. Only failed items have the request ID value in the GSI key Retry Job attribute, and records that have been processed successfully are not shown. After identifying the items, the Lambda function generates the Step Functions run ARN and triggers the job again. This approach minimizes failures, and because this function is scheduled to run every few hours to identify failed workflows, scanning the GSIs is feasible in this case.
Notification service
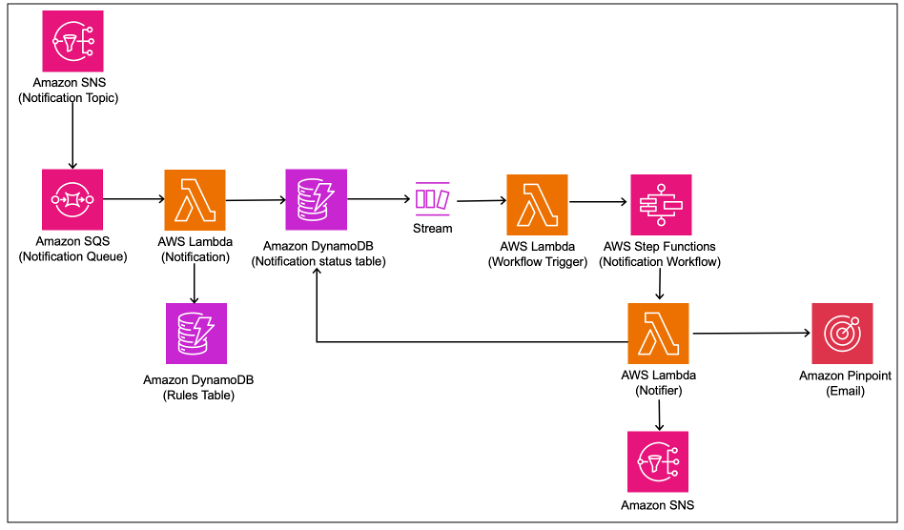
The notification service uses a design and table schema similar to the enrichment service, where the output messages are consumed and processed following a similar pattern to send remittance notifications to customers. This service has additional rules to verify that the correct notification template is used based on user characteristics, purpose, or region.
The following diagram shows the notification service flow.
Summary
The Amazon FinTech team utilized DynamoDB databases to build a scalable, reliable, and event-driven remittance service. They simplified the solution with DynamoDB Streams and sparse GSIs to implement a sweeper pattern design. Furthermore, with DynamoDB out-of-the-box features and capabilities such as DynamoDB Streams, GSIs, and schema flexibility, the FinTech team was able to launch the remittance and notification services sooner by reducing development effort by 40% compared to other options that were considered.
For more information on getting started with DynamoDB, refer to our documentation. To dive deeper into event-driven patterns with DynamoDB, visit Serverless Land.
About the Authors
 Balajikumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff!
Balajikumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff!
 Pradeep Misra is a Specialist Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also loves doing science experiments with his daughters.
Pradeep Misra is a Specialist Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also loves doing science experiments with his daughters.