AWS Database Blog
How to architect a hybrid Microsoft SQL Server solution using distributed availability groups
Migrating monolithic mission-critical Microsoft SQL Server databases from on-premises to AWS (that is, to SQL Server based on Amazon EC2) is often a challenging task. The challenge comes mostly from the following:
- A prolonged downtime window during cutovers that can have an adverse impact on the business
- Challenges involved in keeping the databases (both on-premises and AWS) in sync
- Lack of flexibility to plan and follow a phased approach for the migration
This post covers the details on how you can architect a hybrid solution to lift and shift (or lift and transform) your critical SQL Server databases to AWS. This solution uses distributed availability groups, a new feature that was introduced in SQL Server 2016. In this post, I also discuss a phased approach that you can follow to control the migration using distributed availability groups and thus achieve great flexibility.
An overview of distributed availability groups
A distributed availability group is a special type of availability group (AG) that spans two separate availability groups. You can think of it as an availability group of availability groups or AG of AGs. The underlying availability groups are configured on two different Windows Server Failover Clustering (WSFC) clusters.
Distributed availability group architecture is more efficient than extending an existing on-premises Windows Server Failover Cluster (WFSC) to AWS. Data is transferred only from the on-premises primary to one of the AWS replicas (the forwarder). The forwarder is responsible for sending data to other read replicas in AWS. This architecture reduces the traffic flow between on-premises and AWS and vice versa.
Architecture overview
The following diagram shows the overall architecture of the solution.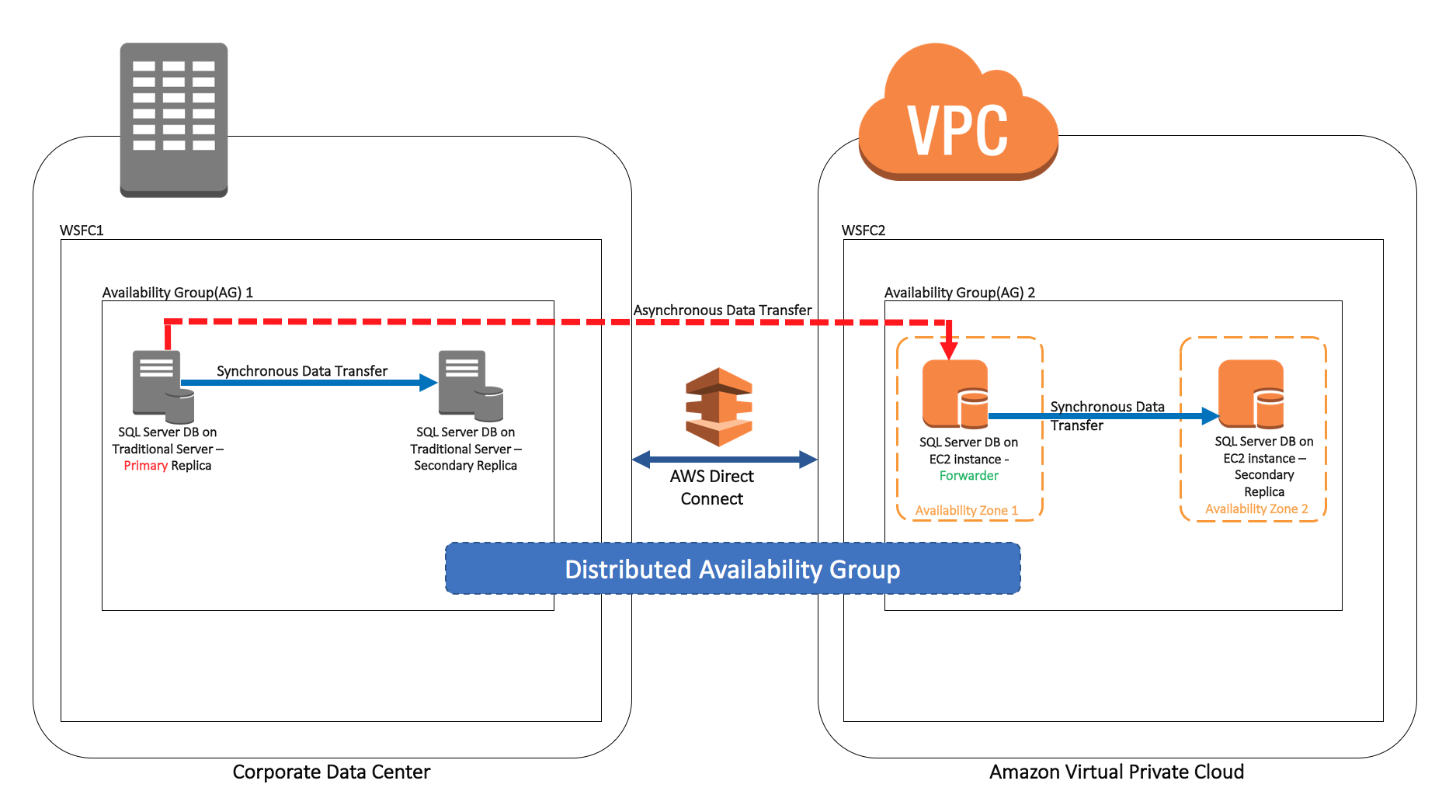 As shown, the first WSFC cluster (WSFC1) is hosted on-premises. It powers the on-premises availability group (AG1). The second WSFC cluster (WSFC2) is hosted in AWS. It powers the AWS availability group (AG2).
As shown, the first WSFC cluster (WSFC1) is hosted on-premises. It powers the on-premises availability group (AG1). The second WSFC cluster (WSFC2) is hosted in AWS. It powers the AWS availability group (AG2).
In this use case, the SQL Server instances and database on-premises are powered by traditional physical servers or virtual machines (VMs). The SQL Server instances in AWS are hosted on Amazon EC2, and the SQL Server databases are configured on Amazon EBS volumes. AWS Direct Connect establishes a dedicated network connection from on-premises to AWS.
As represented in the architecture diagram preceding, the on-premises availability group (AG1) has two replicas (nodes). The data transfer between them is synchronous, with automatic failover. If one of the on-premises replicas fails, then AG fails over to the second replica and the DB are available for the application and users. You can always add more replicas—each availability group supports one primary replica and up to eight secondary replicas. You can decide if the additional replicas need to be synchronous or asynchronous based on your high availability requirements and scaling needs with read replicas.
The AWS availability group (AG2) also has two replicas, and the data transfer between them is synchronous with automatic failover. If an EC2 instance or an Availability Zone fails, the AG fails over to the second EC2 instance in a different Availability Zone.
As part of this solution, you configure a distributed availability group. This group contains both the on-premises availability group (AG1) and the AWS availability group (AG2). The distributed availability group keeps the databases in sync in an asynchronous fashion, as shown in the architecture diagram preceding by the dotted red line.
The forwarder (represented in green in the diagram preceding) is responsible for sending data to other read replicas in AWS. This data forwarding reduces the traffic flow between on-premises and AWS. Data is only sent once from the primary replica, and the forwarder takes care of the rest of the seeding.
At any given point of time, there is only one database that is available for writes. You can use the rest of databases in the secondary replicas for reads. In the sample architecture diagram preceding, we consider that the on-premises primary database is available for read/write and the AWS secondary database is available for reads.
The ability to add read replicas in AWS is a key benefit. Given this ability, you can move your read-only apps to AWS first when it comes to AWS migration. The database is also closer to your application and users.
To scale out your read workloads, you can add more read replicas in AWS and in multiple Availability Zones. This approach is represented in the following architecture diagram, which shows three read replicas in three different Availability Zones.
Phased approach for migration
By using the distributed availability architecture, you can use a phased approach for your migration and thus achieve great flexibility.
Phase 1
In this phase, you can move most of your read-only apps to AWS, where they access the read-only secondary databases. Read/write applications continue to access the primary database on-premises.
In this phase of cloud migration, stress testing, functionality testing, and regression testing the database workload are a key element. Sizing the EC2 instances correctly to support the read workload is also a significant step in this phase.
Another key aspect to consider is that the read-only apps on the AWS side read data that is asynchronously replicated. Thus, there is a data replication lag that affects freshness of data. Even though the lag is minimal because this solution uses a Direct Connect connection, you should consider this point for applications that cannot tolerate latencies or any data staleness.
Following is a diagram that shows this architecture.
Phase 2
In the second phase, you can fail over the distributed availability group to AWS and the AWS database becomes the primary. Read/write applications now access the primary database in AWS.
Certain read-only apps continue to access the secondary database on-premises. These read-only apps are ones that you plan to never move to AWS. These might be applications that you plan to sunset after a specific point of time but that still need a database closer to them to avoid latencies.
Failover is a manual process, and you set the state of synchronization of the distributed availability group to be synchronous. When the state is synchronized, you can initiate a failover. Failover is relatively quick and thus reduces the downtime.
An architecture diagram is shown following. Setup and configuration
Setup and configuration
The high-level steps to create a distributed availability group are listed following:
- Create the on-premises availability group and join the secondary replica (or replicas) to the on-premises availability group.
- Create an AG listener for the on-premises availability group.
- Create the AWS availability group and join the secondary replica (or replicas) to the AWS availability group.
- Create an AG listener for the AWS availability group.
- Create a distributed availability group with an availability mode set to
Asynchronous_Commiton the on-premises side. - Join the distributed availability group on the AWS side.
- Join the database on the AWS availability group.
You can refer to the Microsoft documentation on distributed availability groups to learn more about the configuration scripts and steps.
Conclusion
Distributed availability group architecture gives you flexibility when it comes to lifting and shifting a mission-critical SQL Server instance or database to AWS. The phased approach makes sure that you have better control over the migration steps and can conduct sufficient stress, regression, and functionality tests as part of the journey.
In an upcoming post, I plan to discuss how you can architect distributed availability groups for two or more AWS Regions. I also plan to discuss some of the best practices and standards that you can incorporate when architecting a distributed availability group.
Thanks for reading, and keep watching this space for more.
#BuildOn
About the Author
 Anup Sivadas is a solutions architect at Amazon Web Services. He works with our customers to provide architectural guidance and technical assistance on AWS services, helping them improving the value of their solutions when using AWS.
Anup Sivadas is a solutions architect at Amazon Web Services. He works with our customers to provide architectural guidance and technical assistance on AWS services, helping them improving the value of their solutions when using AWS.