AWS Database Blog
Migrate IBM Db2 LUW to Amazon Aurora PostgreSQL or Amazon RDS for PostgreSQL
In this post, we provide an overview of database migration from IBM Db2 LUW to Amazon Aurora PostgreSQL-Compatible Edition or Amazon Relational Database Service (Amazon RDS) for PostgreSQL. We discuss the challenges you may encounter during schema conversions, and how to perform data migration using the native EXPORT and COPY commands. Additionally, we address how to automate data migration and conduct schema and data validation.
This post covers two major milestones of Db2 LUW migration:
- Converting the Db2 LUW source schema using the AWS Schema Conversion Tool (AWS SCT)
- Migrating data from Db2 LUW to Aurora PostgreSQL-Compatible using native, built-in tools
Prerequisites
Before you start your database migration journey, we recommend completing a pre-migration phase to get your database ready. For more information, refer to Database Migration—What Do You Need to Know Before You Start. On a high level, you should do the following:
- Drop or deprecate any objects that are no longer needed, like tables, stored procedure, functions, or triggers that were left redundant from application or business process enhancements.
- Drop temporary tables and backup copies of tables from the past maintenance.
- Purge or archive historical data not required to Amazon Simple Storage Service (Amazon S3).
Now, let’s get started!
Schema conversion
It’s highly recommended to identify the effort required and feasibility of your database migration before you start the migration journey. You can use AWS SCT to generate a database migration assessment report that provides the details of action items for your schema conversion. You can use this report to estimate the efforts of your schema conversion based on complexity. To download and install the AWS SCT, refer to Installing, verifying, and updating AWS SCT.
In the following sections, we cover some common scenarios faced during schema conversion from Db2 LUW to PostgreSQL migration.
Partitioned tables
Partitioned tables are a data organization scheme in which table data is divided across multiple storage objects, called data partitions, according to values in one or more table attributes, called partition keys. Both Db2 LUW and PostgreSQL support table partitioning, but there are few differences.
Firstly, a range-partitioned table in a Db2 LUW database has an INCLUSIVE and EXCLUSIVE clause to set boundary values. PostgreSQL as of v15 only supports INCLUSIVE for a starting boundary and EXCLUSIVE for an ending boundary.
In the following example, the table DIM_SPORTING_EVENT has multiple partitions to store monthly data. In Db2 LUW, the lower end of the partition is the start of the month (01), and the upper end is the end of the month (30/31). In PostgreSQL, the lower end is the start of month (1), and the upper end is the start of the next month, which keeps the month-end date in the same partition.
| Db2 LUW |
| PostgreSQL |
In PostgreSQL, the primary key needs to include the partition key, but in Db2 LUW, no such limitation is present. After you add a partition key to the primary key, your existing insert statements may cause duplicates in PostgreSQL.
The following table contains sample data entries in the table sample.dim_sporting_event.
| Existing Primary Key (Db2 LUW) (SPORTING_EVENT_ID) | Insert Operation | New Primary Key (PostgreSQL) (sporting_event_id, start_date_time) | Insert Operation |
| 1234 | Success | 1234, 2017-01-02 | Success |
| 1234 | Failure | 1234, 2017-01-03 | Success |
This can be addressed according to your business logic. For example, a solution might involve identifying an alternative primary or unique key, or removing partitioning from the table. Before you decide to remove partitioning from the table or add additional keys, you need to verify your functional and non-functional requirements.
Lastly, the Db2 LUW partition column can be defined on generated columns, but this isn’t possible in PostgreSQL as of v15. For more information, refer to Generated Columns.
Sequences
You may have used the CACHE option in the SEQUENCE statement for performance and tuning. When used, DB2 pre-allocates a specified number of sequential values in memory. This helps minimize lock contention. Cached values are visible to connections at the Db2 LUW server. In PostgreSQL, although the cache keyword is present, values are cached only for a connection or session that is accessing the sequence. If a new connection or session accesses the sequence, a new set of values is cached for that session. Compare the code blocks in the following tables:
| Db2 LUW |
| PostgreSQL |
| Db2 LUW |
| PostgreSQL |
Identity columns automatically generate a unique numeric value for each row added to the table. With the INCREMENT BY clause, you can set how much subsequent values increase for each new row. Note that the identity column doesn’t advance on the target after the migration. Therefore, you should reset the sequence to the next value to help prevent duplicates. The pg_get_serial_sequence function returns the name of the sequence associated with the identity column. The following anonymous block can help you generate a SQL statement to restart identity sequences.
The following code snippet generates an SELECT SETVAL statement to restart identity sequences with max +1 value:
Materialized query tables
Materialized query tables (MQT) are defined by a query, and they help improve the performance of complex queries in Db2 LUW. PostgreSQL has materialized views (MV) to achieve similar functional requirements. The following table compares these features.
| Db2 LUW | PostgreSQL |
| Called materialized query tables | Called materialized views |
| Two types: system-managed and user-managed identified by MAINTAINED BY clause | Only user-managed |
| Automatic refresh is possible for system-managed materialized query tables using REFRESH IMMEDIATE option | Natively only supports manual refresh, automatic refresh is available via a trigger |
| Both full and incremental refresh are possible | Only full refresh is supported |
| Exclusive table lock during refresh | Supports refresh without locking out select statements using CONCURRENTLY keyword |
| Optimizer automatically considers MQT during query rewrite phase | Optimizer doesn’t consider MV during query rewrite phase |
| DML statements are permitted on user-managed MQT | No DML statements are allowed |
You can convert user-managed MQT from DB2 LUW to materialized views in PostgreSQL. System-managed MQT from Db2 LUW can be converted to PostgreSQL by converting MQT into a regular table along with triggers to refresh data based on Data Manipulation Language (DML) operations on source tables.
Unique indexes
In Db2 LUW, a UNIQUE index treats NULL values as equal. This means that if a UNIQUE index has a column that allows null, it can only occur once. However, PostgreSQL treats NULL as a distinct value. As a result, you can have multiple NULL values for a column in a UNIQUE index. Compare the code in the following table.
| Db2 LUW |
| PostgreSQL |
| Db2 LUW |
| PostgreSQL |
You can emulate the unique index behavior of Db2 LUW in PostgreSQL (up to version 14) using a partial index:
## Insert fails similar to Db2 LUW after creating partial unique index in postgresql
In v15 or above, you can achieve this by adding NULLS NOT DISTINCT in the create index statement.
After you have successfully converted the schema, the next milestone is validation. You can perform schema validation by verifying the number and properties of object matches between Db2 LUW and PostgreSQL, using the SQL samples provided in the post Validate database objects after migrating from IBM Db2 LUW to Amazon Aurora PostgreSQL or Amazon RDS for PostgreSQL. You can run this code as part of a script or batch to automate this milestone.
Migrate data using native EXPORT and COPY commands
This scenario is a heterogeneous migration which requires only a full load (one-time migration) without the change data capture (CDC) capability. We are not able to use replication tools like AWS Database Migration Service (AWS DMS) due to customer policies and other restrictions. The migration solution includes native Db2 EXPORT and PostgreSQL COPY commands with CSV (comma-separated values), also called DEL (delimited) format in Db2 LUW, for data transfer.
We sorted tables on the Db2 LUW side into hot (actively updated) and cold (used only for read purposes). Tables tagged with cold data were migrated to PostgreSQL ahead of the cutover date to reduce cutover time during production migration.
The following diagram shows the workflow of migrating data from Db2 LUW to Aurora PostgreSQL-Compatible.
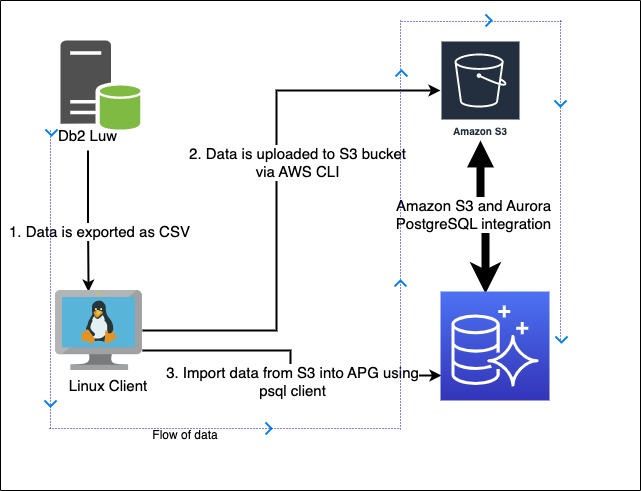
The workflow steps are as follows:
- Data is exported from the Db2 LUW system using the export command in DEL or CSV files.
- The files are uploaded to an S3 bucket using the AWS Command Line Interface (AWS CLI) to take advantage of the multi-part upload functionality and improve file transfer speed.
- Data from the files is imported into Aurora PostgreSQL-Compatible using its integration with Amazon S3.
You can build an automated solution for data migration tasks with the following steps and sample code to reduce errors from manual activities and provide more efficient monitoring.
Export Db2 LUW data
You can automate the data export from the Db2 LUW system using a loop that runs through the tables to be exported. To reduce runtime, consider the following optimizations:
- Depending on your Db2 LUW server and client capacity, you can trigger the EXPORT command in parallel by triggering multiple scripts or a single script that triggers multiple exports in the background
- You can group and sort tables to be exported in such a way that one big table export doesn’t delay job completion while all other small and medium tables are completed
Use the following sample code snippet to automate the Db2 LUW export:
Sample Ctlfile
The preceding script uses a control file (ctlfile) to loop through tables and put the export command in the background. A control file has schema names, tables names, and a SELECT statement with required columns in the table.
Upload exported data to Amazon S3
Data exported in CSV format from Db2 LUW is uploaded to Amazon S3 using the AWS CLI from a Linux client. You can schedule upload jobs in away that large tables are triggered in parallel to other small and medium tables.
Use the following sample code snippet to upload files recursively to Amazon S3:
You can use the include and exclude clause of the aws s3 cp CLI command to segregate large and small tables in upload scripts.
Import data from Amazon S3 into Aurora PostgreSQL-Compatible
After the data transfer to an S3 bucket is complete, we use the aws_s3 extension to load the data into Aurora PostgreSQL-Compatible.
Use the following sample import SQL to load data from Amazon S3:
Use the following sample code to generate the preceding import SQL statements to load data from Amazon S3:
Use the following sample code to create a shell script to run import SQL in a file to load data from Amazon S3:
Learnings from data migration
Keep in mind the following considerations:
- Data exported from Db2 LUW in CSV files has double quotes around fields except integer type, but the PostgreSQL COPY command doesn’t identify double quotes by default unless explicitly specified using QUOTE keywork.
- The default timestamp format exported from Db2 LUW can result in a garbage timestamp value when imported into PostgreSQL. Therefore, it’s recommended to use
to_char(<timestamp_field>,'YYYY-MM-DD HH:MM:SS.FF6')for timestamp fields in the SELECT statement used to export data from Db2 LUW into the default PostgreSQL format. - Generated columns should not be part of CSV files because the copy command will fail in PostgreSQL. They can be removed from the Db2 export by specifying explicit columns to be exported in the SELECT statement used in the Db2 export command.
Data validation
There are multiple ways to perform data validation after full data loads. These include comparing the minimum and maximum of integer values, lengths of varchar fields, and row counts, or using generated hash comparisons. We recommend conducting a row-by-row comparison to minimize the possibility of data corruption. A Python program using the pandas library, which can connect to both the source and target, can effectively carry out this task
Use the following sample Python code using the pandas library to implement a row-by-row comparison:
The open-source data compare tool from AWS is an option to model the row-by-row data comparison. This tool supports Oracle, but you can make changes to support Db2 LUW as the source as well.
Conclusion
In this post, you learned about various challenges you may experience when migrating from IBM Db2 LUW to Aurora PostgreSQL-Compatible, and how to overcome them. You also learned how to perform data migration using native tools of Db2 and Aurora PostgreSQL-Compatible, how to automate this process, and how to perform schema and data validation.
A heterogenous database migration project using native tools necessitates custom scripting and tooling, which can impact on your migration timeline and efforts. But native tools provide customization flexibility and can save license and infrastructure cost involved with third-party software.
If you’re considering using AWS DMS for data migration from Db2 LUW to Aurora PostgreSQL-Compatible, refer to the following resources:
- Using IBM Db2 for Linux, Unix, and Windows database (Db2 LUW) as a source for AWS DMS
- Using a PostgreSQL database as a target for AWS Database Migration Service
- Best practices for AWS Database Migration Service
If you have questions or feedback, leave a comment in the comments section.
About the Author
 Rakesh Raghav is a Database Specialist with the AWS Professional Services in India, helping customers have a successful cloud adoption and migration journey. He is passionate about building innovative solutions to accelerate their database journey to cloud.
Rakesh Raghav is a Database Specialist with the AWS Professional Services in India, helping customers have a successful cloud adoption and migration journey. He is passionate about building innovative solutions to accelerate their database journey to cloud.