AWS Database Blog
Accelerate graph query performance with caching in Amazon Neptune, Part 3: Neptune cluster-wide caching architectures with Amazon ElastiCache
Graph databases are uniquely designed to address query patterns focused on relationships within a given dataset. From a relational database perspective, graph traversals can be represented as a series of table joins, or recursive common table expressions (CTEs). Not only are these types of SQL query patterns computationally expensive and complex to write (especially for highly connected datasets that involve multiple joins), but they can be difficult to tune for performance.
Amazon Neptune provides a means to address these gaps. Neptune is a fully managed graph database with a purpose-built, high-performance graph database engine that is optimized for storing billions of relationships and running transactional graph queries with millisecond latency.
However, there are situations where we can achieve even better performance through the use of various caching techniques. Caching, or the ability to temporarily store data in memory for fast retrieval when read more than once, is a technique as old as computing itself and used broadly across many database platforms.
In this three-part series, we discuss how to improve your graph query performance using a variety of caching techniques with Neptune. Part one sets the scene by discussing the Neptune query process and how the buffer pool cache works. In part two, we discuss the additional Neptune caches (query results cache and lookup cache) and how they can improve performance for use cases with repeat queries, pagination, and queries that materialize large quantities of literals. In this final post, we show how to implement Neptune cluster-wide caching architectures with Amazon ElastiCache, which benefits use cases where the results cache should be at the cluster level, use cases that require dynamic sorting of large result sets, or use cases that want to cache the query results of any graph query language.
The Neptune query results cache can have a significant impact in decreasing graph query latency for certain types of queries. However, it is deployed on a per-instance basis within a given cluster. For situations where users may want a global, or cluster-wide cache for all results, or perhaps want a means to scale the cache size beyond what Neptune allocates, such functionality can be achieved by using Neptune in conjunction with other database services.
Accelerate graph query performance with caching in Amazon Neptune:
|
Cluster-wide query results cache
Although the Neptune query results cache provides the benefit of direct integration within the service, it currently only supports the Gremlin query language. Additionally, it is a per-instance cache, which means cached results are specific to the cache that was used, and are not replicated to other query results caches on other instances within the cluster. Consequently, architectures that don’t enable the query results cache on all instances or use auto scaling mechanisms such as read replica auto scaling, will need to intentionally direct queries to the instance with the desired query results cache.
If there is a need for a query results cache that supports all query languages, or a need for a global, cluster-wide query results cache, you can use Amazon ElastiCache or Amazon MemoryDB for Redis alongside Neptune in a cache-aside architecture.
Amazon ElastiCache is a managed, in-memory data store that can be used for building caches or for any need requiring very fast access and low-latency responses. ElastiCache offers two different types of in-memory data stores: managed Amazon ElastiCache for Redis or Amazon ElastiCache for Memcached. You can also use Amazon MemoryDB for Redis, which is a durable Redis-compatible, in-memory managed database service.
In a cache-aside architecture, your application first checks the cluster-wide cache (ElastiCache in our example) to determine if the required query results are available, and if so, returns it to the client; and if not, queries Neptune, populates the cache with the query results, and returns the results to the client.

In our example, we use ElastiCache for Redis as a hash store to build a cluster-wide result cache. First, the text string representation of the query is hashed using an MD5 hash sum, which provides a key for storing and retrieving the query results within ElastiCache for Redis. The hash is used to check the cache for any stored results, and if they don’t exist, the application runs the query against Neptune and results are saved back into ElastiCache for Redis using the hash as a key. In our example, we choose to use Redis strings to represent our key-value pairs, so that we can add individual TTLs to each query result.
Note: We are using the hash simply as a way to store and retrieve query results. Since we are not using them for the purpose of encryption, the MD5 algorithm is suitable for our needs. If you have encryption requirements, we recommend following the latest guidelines set by the National Institute of Standards and Technology (NIST) for hash functions.
For example, let’s say we want to cache the following query to get all the airports in the US:
We can do so with the following Python code:
Online sorting
We can use ElastiCache for Redis for much more than just caching data. It supports a wide array of data structures that make it a very flexible in-memory store. Outside of just storing hashed data, ElastiCache for Redis also supports a data structure called a sorted set. A sorted set is a collection of members that are stored in a sorted order, according to a score value that each member is associated with. Sorted sets are often used for leaderboards, bestseller lists, and many other use cases where a user wants to maintain a list of items based off of alphanumeric sorting. Sorted sets can also be used for storing query results in a sorted order.
For example, if we want to retrieve all possible paths from the Los Angeles International Airport with three connecting flights outwards, then pick the paths that have the shortest total distances covered, we can use the following Gremlin query:
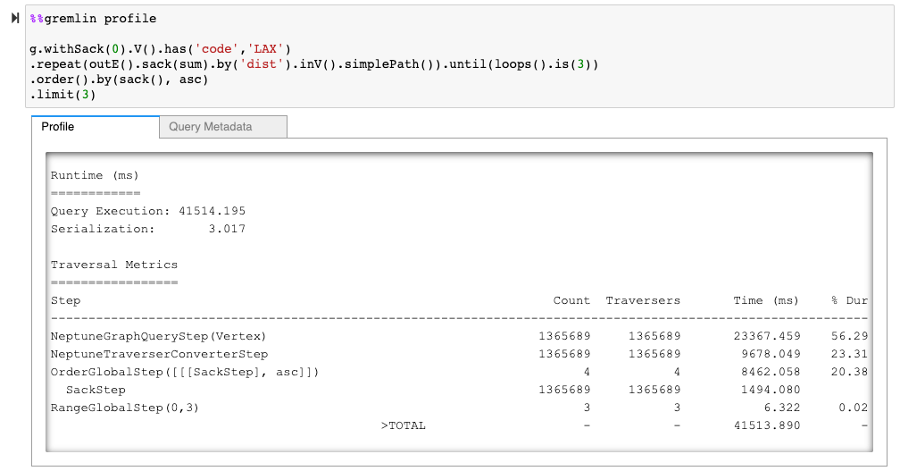
But even with a warm buffer pool cache, the query still takes almost 4 minutes to run, because it’s gathering all possible paths (which is just under 1.4 million possibilities) and ordering them before collecting the three shortest paths:
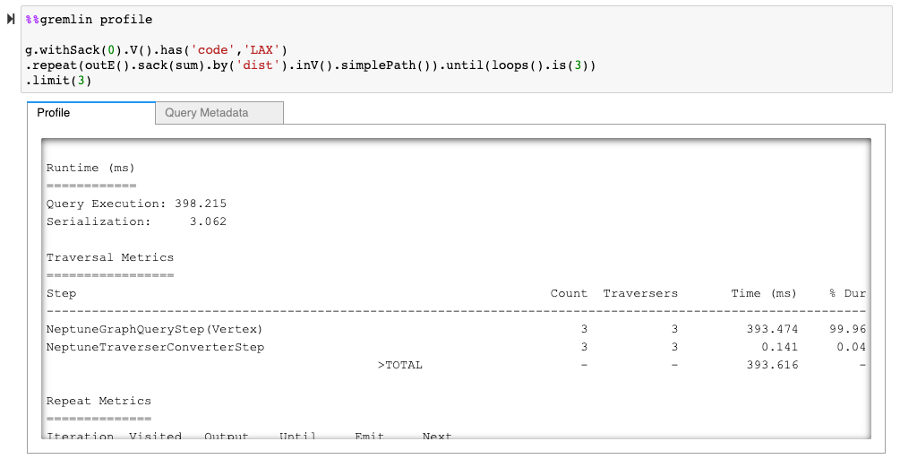
Removing the ordering operation results in a query runtime of about 12 milliseconds, showing that the query is not I/O bound, but rather compute bound:
Even if we remove the projection, comparing the profile outputs shows that the bulk of the time is spent ordering, because the engine needs the results of all possible paths before sorting in ascending order.
Instead of using Neptune for this type of access pattern, we could keep an updated version of this aggregation in a sorted set in ElastiCache for Redis. The following code shows how to use the previous query to fetch the total distances for each path, store those into a Redis sorted set, and subsequently fetch the three shortest paths sorted by total path length.
First, we save the full output of our query into a JSON file:
Next, we load our JSON file of results into a Redis sorted set using the Redis function zadd:
Then we can retrieve the top three shortest paths with the Redis function zrange:
Fetching the top three shortest paths from ElastiCache for Redis with the preceding query only takes about 4 milliseconds:
Other considerations
Neptune’s query results cache and lookup cache are both fully managed caches, which offloads some cache management tasks from you. If you’re building your own cluster-wide cache, the following are other considerations to make:
- How to handle cache invalidation – Data freshness can be managed with a time to live (TTL).
- How to handle the cache pre-warming process, if needed – If pre-warming your cache, you should generally perform this from a Neptune reader instance instead of the writer, to save CPU cycles for your write queries. Depending on the types of queries you’re running, you may even consider dedicating a reader instance to pre-warming your cache to avoid buffer pool cache pollution on other instances. Also consider pre-warming your cache as a separate process from your live application, so that live queries are performant from the start.
- How to manage query timeouts – If using a cluster-wide cache to cache the results of long-running queries, make sure you set query timeouts appropriately. Queries use the most restrictive timeout possible, meaning that you can’t use
with(‘evaluationTimeout’, <time>)or the queryTimeout SPARQL query hint to increase the length of timeouts on a per-query basis, beyond the timeouts set at the database parameter level.
For additional details on caching best practices when using Redis, refer to Database Caching Strategies Using Redis.
Summary
Caching techniques have long been used in computing to optimize access to data storage. As shown throughout this three-post series, caching can be applied in a number of different areas within Neptune. You can use these features within your graph application to accelerate your queries further, and greatly reduce the time it takes to fetch query results. Within our series, we discussed the following topics:
- How to use the Neptune query results cache for fast retrieval of results from previously run queries
- How to use the query results cache for pagination
- When and how to use the Neptune lookup cache for optimizing access to property values and RDF literals
- When and how to implement other caching architectures where Neptune can be paired with ElastiCache for Redis to implement a cluster-wide cache
These features are now available. Check them out and feel free to leave any feedback in the comments section.
About the Authors
 Taylor Riggan is a Sr. Graph Architect focused on Amazon Neptune. He works with customers of all sizes to help them learn and use purpose-built, NoSQL databases. You can reach out to Taylor via various social media outlets such as Twitter and LinkedIn.
Taylor Riggan is a Sr. Graph Architect focused on Amazon Neptune. He works with customers of all sizes to help them learn and use purpose-built, NoSQL databases. You can reach out to Taylor via various social media outlets such as Twitter and LinkedIn.
 Abhishek Mishra is a Sr. Neptune Specialist Solutions Architect at AWS. He helps AWS customers build innovative solutions using graph databases. In his spare time, he loves making the earth a greener place.
Abhishek Mishra is a Sr. Neptune Specialist Solutions Architect at AWS. He helps AWS customers build innovative solutions using graph databases. In his spare time, he loves making the earth a greener place.
 Kelvin Lawrence is a Sr. Principal Graph Architect focused on Amazon Neptune and many other related services. He has been working with graph databases for many years, is the author of the book Practical Gremlin, and is a committer on the Apache TinkerPop project.
Kelvin Lawrence is a Sr. Principal Graph Architect focused on Amazon Neptune and many other related services. He has been working with graph databases for many years, is the author of the book Practical Gremlin, and is a committer on the Apache TinkerPop project.
 Melissa Kwok is a Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions with graph databases according to best practices. When she’s not at her desk, you can find her in the kitchen experimenting with new recipes or reading a cookbook.
Melissa Kwok is a Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions with graph databases according to best practices. When she’s not at her desk, you can find her in the kitchen experimenting with new recipes or reading a cookbook.