AWS Database Blog
Powering recommendation models using Amazon ElastiCache for Redis at Coffee Meets Bagel
Coffee Meets Bagel (CMB) is a dating application that serves potential matches to over 1.5 million users daily. Our motto is “quality over quantity” because we focus on bringing a fun, safe, and quality dating experience that results in meaningful relationships. To deliver on these promises, every match we serve has to fulfill a strict set of criteria that our users request.
With our current traffic, generating high-quality matches presents a challenging problem. We are a team of 30 engineers (with only 3 engineers on our data team!) This means that every engineer has a huge impact on our product. Our app encourages users via push notification at noon local time to log in to the app. This feature is great for driving daily engagement, but unsurprisingly, it creates a huge traffic spike around those times.

Problem statement: How do we generate high-quality matches, while keeping the latency of our services and mobile clients as low as possible?
One solution is to generate ranked, suggested matches before users log into the app. If we want to keep a backlog of 1,000 matches per user, we would need to store 1 billion matches with the user base that we have today. This number grows quadratically as we acquire new users.
Another solution is to generate matches on-demand. By storing potential matches in a search database such as Elasticsearch, we can fetch a set of matches based on specified criteria and sort by relevance. In fact, we do source some of our matches via this mechanism. But unfortunately, searching solely by indexed criteria limits our ability to take advantage of some types of machine learning models. Additionally, this approach also comes with a non-trivial increase in cost and increased maintainability of a huge Elasticsearch index.
We ended up choosing a mixture of both approaches. We use Elasticsearch as a 0-day model, but we also precalculate a variety of machine learning recommendations for every user using an offline process, and we store them in an offline queue.
In this post, we talk about our chosen approach of using Elasticsearch and precalculating recommendations, and why we ended up choosing Redis to store and serve our recommendations (the queue component described earlier). We also discuss how Amazon ElastiCache for Redis has simplified management and infrastructure maintenance tasks for the CMB engineering team.
Using Redis to store recommendations in sorted sets
There are many reasons why we at CMB really love Redis, but let’s outline some of the reasons related to this specific use case:
- Low latency Because Redis is an in-memory database, writing and (especially) reading from Redis has a very low impact on overall latency. Because of the pairwise nature of our domain (for example, deleting one user from our system could mean removing them from thousands of other users’ queues), our access pattern is semi-random. This situation could create substantial overhead when working with a database that needs to read from disk. During the busiest times of the day, we serve hundreds of thousands of matches in minutes, so low latency reads are fundamental. As of today, our reads take, on average, 2–4 ms, and our write process (which writes all new recommendations in small batches) takes 3–4 seconds per user.
- Consistency At CMB, we take pride in providing high-quality matches for our users that fit the criteria they select. For this reason, when a user decides to take a break from dating, decides to delete their account (because they got married through CMB, obviously!), or decides to change some aspect of their profile, it’s crucial that all recommendations are updated as quickly as possible. Redis guarantees consistency that make these scenarios very simple to implement. It provides us with built-in commands that atomically dequeue and enqueue an item in a list. We use these lists and sorted sets to serve our recommendations.
- Simplicity The best thing about Redis is that it’s incredibly simple to interact with. That’s why some of the greatest companies in the world use it. The data structures, the documentation, the complexity of each operation is so well defined. We all know that with simplicity, there is less likelihood of increased code complexity and bugs.
Before using Redis, we had been using Cassandra because it promised high-throughput writes while still guaranteeing some level of low latency with the reads. We experienced a couple of pain points with Cassandra that immediately disappeared when we decided to go with Redis.
Consistency
Cassandra promises eventual consistency. Originally, we thought that our specific use case would not be drastically impacted by the issue, but we were wrong. We even tried increasing our read and write consistency, but unfortunately, our latency drastically spiked up in a way that made our app unreliable.
Maintenance madness!
Probably the main issue that we had with Cassandra was related to maintenance. Our DevOps team and backend engineers were constantly getting paged for nodes flapping (intermittently going on and off) or dying. Even worse, node crashes would produce massive heap dumps that would then fill up the disks. We could have learned a more optimal tuning for our cluster, but as it was, we had already devoted a ton of time to maintaining the cluster.
All of this went away when we decided to move to Redis, and our small team was able to focus on more important issues than managing a finicky cluster.
Why we chose Amazon ElastiCache for Redis
Choosing Amazon ElastiCache for Redis has been a great move for our engineering team. For startup companies, time is really important. Not needing to perform management tasks, provision hardware, check software patches, and maintain infrastructure gives us a lot more time to work on our ideas and our algorithms. One of the greatest features of ElastiCache is that it is very quickly up to date with the latest stable versions of Redis. It enables us to scale out easily, while still having that magic layer of redundancy in case things go wrong. It’s empowering when we, as engineers, can spin up a new Redis instance in minutes without having to think about maintenance, and we can rely on a hardened version of Redis.
Although it’s true with most databases, I think it’s especially beneficial to have managed Redis. This is because Redis is an in-memory data store, and you want to be extremely cautious of memory management, fragmentation, and backups. ElastiCache for Redis does all this for you.
CMB recommendation architecture
CMB’s recommendation architecture is composed of two main components: real time (online) and batch (offline), as shown in the following diagram.
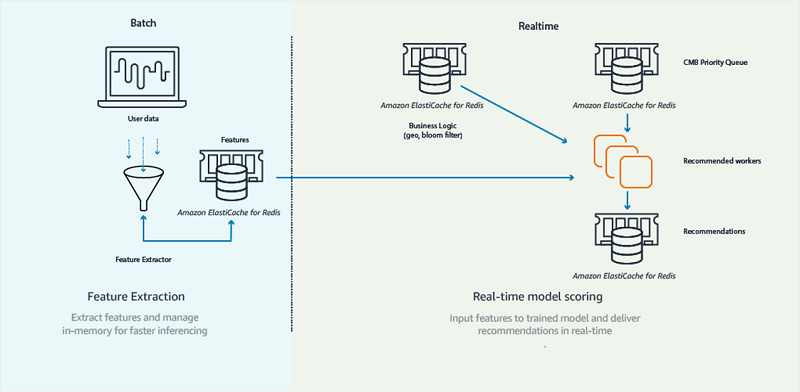
The batch component is a set of scheduled tasks that run at 7 AM every day. These tasks are responsible for reading large chunks of match history, and they train recommendation models and extract features (attributes describing users) for later use. Recommendation models are a predictive component of our app that allow us to “score” a potential match, effectively quantifying the affinity between two users. Recommendation models are one of the core components of CMB that allow us to generate high-quality matches for our users.
The real-time components are used by our core infrastructure, such as web server and web workers, and interact with CMB’s main data stores. Whereas the batch component of our application trains recommendation models and extracts features, the online component does the work of scoring matches between eligible pairs of users. This component is responsible for populating/maintaining multiple queues of recommendations per user. Our Redis ”recommendations” data store contains these queues in the form of sorted sets. Our web application reads from this data store to serve recommendations in real time to our clients.
Using ElastiCache to efficiently compute similarities between users
At CMB, we use latent (or hidden) features to calculate similarity between users.
A brief overview of latent features
Most people are familiar with the concept of “features” in machine learning: These features are the metadata that we, as humans, attribute to our users. We assume that the features that we define have a positive impact in the learning process of our algorithms (in our context, we assume that our algorithms learn how to predict higher-quality matches).
In CMB’s context, the following are example features:
- Age
- Gender
- Location
Most of the time, the features we select as humans are not the most powerful indicators for predicting high-quality matches because they are directly observable. There is a set of features (hidden or latent) that are created via a specific subset of ML algorithms by looking at past match data. These features are highly predictive. They are not directly observable, but they are very powerful predictors of high-quality matches.
How CMB uses latent features
CMB uses latent features to predict similarity between groups of users (item-based collaborative filtering). Two of our batch tasks are responsible for computing the latent features for all of our active users. Our tasks compute 100 latent features per user, represented as floats.
These features are learned by analyzing hundreds of days of match history for every user. After the (latent) features for our users are trained (this usually takes 6–7 hours per day), we store them in ElastiCache in JSON format.
The following example shows what it would look like to fetch the latent features for user ID 905755.
With just one command, we can load latent features for a user. We don’t know what these values represent explicitly, but we know that they’re consistent across multiple users (for example, the first value in the array represents the same attribute for all users).
Generating recommendations through collaborative filtering
One of the ways we generate recommendations for a user is by finding users who are similar to the last matches that the user liked.
Example: A male named Daniel is looking for a female in San Francisco. Daniel happens to like hiking and playing tennis, and his “like” history clearly reflects this preference. In fact, three of the last five matches that Daniel liked were outdoorsy and played a sport. The next time we generate recommendations for Daniel, we search in our database of potential candidates for females who are as similar as possible to the last five females that Daniel liked. The result of this operation is a curated list of recommendations sorted by relevance. At the top of the list, we might find some females who are outdoorsy or enjoy sports.
We can compute the similarity between two users by simply measuring the similarity between the user’s vectors:
Assuming that latent features are present for all users in our code base, with only three lines of Python code, we can efficiently find the similarity between any combination of two users. We can then rank order eligible matches by their similarity to previously liked users, and persist these in our “Recommendations” Redis data store.
What are the benefits of using Redis for storing latent features?
We use Redis to store latent features because it offers us several advantages.
Simplicity of implementation
As a software engineer, it is empowering to be able to perform non-trivial operations with just a few lines of code. Redis commands are explicit and simple to understand, and this results in simpler code and (hopefully) fewer bugs down the road. Because Redis is so simple, and it works with very primitive data structures, there are fewer hidden traps and simpler code. Effectively, there is no need to think about schemas, joins, indices, and queries.
The reason that we emphasize simplicity here is because by working with very simple and well known data-structures, our code becomes very minimal.
Efficient handling of CMB’s random reads/writes
At any time, in any given day, our infrastructure is continually refreshing recommendations for our users. We do this to keep our recommendations fresh (taking into account the most recent information learned) and relevant (inside a user’s stated criteria). The order in which we read and write to keys is non-deterministic.
In this scenario, someone who is using a disk-based data store would find themselves accessing random non-contiguous portions of disk at any given time, or constantly evicting cache from memory and therefore degrading performance. Contrarily, Redis is in-memory and does not suffer from this issue.
Separation of concerns
One of the greatest characteristics of latent features is that after they have been computed, they are just a list of numbers. Latent features carry no dependencies and require no dependencies to be used! Redis, in this case, is the “middleman” between the offline algorithm component (Apache Spark, NumPy, Pandas, Amazon S3, or Apache Parquet), and the online web component (Django).
Filtering out already seen recommendations using Redis
At CMB, we never want to show our customers matches that they have already seen because… if they passed on someone before, they will likely pass on them again! This is effectively a set membership problem.
Using Redis sets to filter already seen recommendations
One way to avoid showing CMB users someone that they’ve already seen is to update a set every time they see a new match.
In the following case, we added user 522168 to the exclusion list of 905655.
If we want to check whether 905755 has already seen 52216 and 212123, we can do the following:
As this example shows, 522168 was a hit, while 212123 was not. So now we can be sure to remove 522168 from future recommendations for user 905755.
The biggest issue arising from this approach is that we end up having to store quadratic space. Effectively, as the number of exclusion lists increases due to organic user growth, so will the number of items present in any set.
Total space needed for set implementation = n_users * n_users
Using bloom filters to filter already seen recommendations
Bloom filters are probabilistic data structures that can efficiently check set membership. Compared to sets, they have some risk of false positives. False positive in this scenario means that the bloom filter might tell you something is inside the set when it actually isn’t. This is an affordable compromise for our scenario. We’re willing to risk never showing someone a user they haven’t seen (with some low probability) if we can guarantee we’ll never show the same user twice.
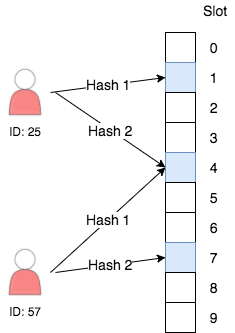
Under the hood, every bloom filter is backed by a bit vector. For each item that we add to the bloom filter, we calculate some number of hashes. Every hash function points to a bit in the bloom filter that we set to 1.
When checking membership, we calculate the same hash functions and check if all the bits are equal to 1. If this is the case, we can say that the item is inside the set, with some probability (tunable via the size of the bit vector and the number of hashes) of being incorrect.
Implementing bloom filters in Redis
Although Redis does not support bloom filters out of the box, it does provide commands to set specific bits of a key. The following are the three main scenarios that involve bloom filters at CMB, and how we implement them using Redis. We use Python code for better readability.
Creating a new bloom filter
This operation happens whenever a new user is created in our app.
NOTE: We chose 2 ** 17 as a bloom filter using the Bloom Filter Calculator. Every use case will have different requirements of space and false-positive rate.
Adding an item to an already existing bloom filter
This operation happens whenever we need to add a user exclude_id to the exclusion list of profile_id. This operation happens every time the user opens CMB and scrolls through the list of matches.
NOTE: The make_hash_positions() function returns a list of integers representing the bit indices that map to the profile exclude_id.
As this example shows, we make use of Redis pipelining because batching the operations minimizes the number of round trips between our web servers and the Redis server. For a great article that explains the benefits of pipelining, see Using pipelining to speed up Redis queries on the Redis website.
Checking membership in a Redis bloom filter for a set of candidate matches
This operation happens whenever we have a list of candidate matches for a given profile, and we want to filter out all the candidates that have already been seen. We assume that every candidate that was seen was correctly inserted in the bloom filter.
This last operation is a little more complex that the others, so let’s take a step-by-step look at what’s happening.
In Redis, bloom filters are simply bit vectors. With this operation, we fetch the entire bloom filter in memory once, and perform all the filter bulk operation within Python.
The preceding check is done to validate if the bit at hash_position is set to 1. If any of the bits is not set to 1, then we know for sure that the item is not present in the bloom filter.
Total space needed for bloom filter implementation = n_users * bloom_filter_size
What are the benefits of using Redis for storing bloom filters?
Using Redis to store bloom filters offers us the following advantages.
Performance
Through the use of pipes and SETBIT operations, adding items to a bloom filter is very efficient and simple. Also, performing bulk filtering is also very efficient because there is only one read operation. With our current infrastructure, we can efficiently filter tens of thousands of candidates in ~170 ms.
Future proof
As our user base grows, we don’t have to worry about quadratic growth because our bloom filters are fixed in size. In fact, with Redis Cluster, you can shard your data and still keep your bloom filters in memory.
What are the downsides of using Redis for storing bloom filters?
The main downside is code complexity. Although the Redis portion of the bloom filters is very simple, the actual implementation of a bloom filter can be complicated. Bloom filters are also fairly hard to debug, so be sure to get a well-known library if you can.
Redis now has a module that can provide bloom filter support. See Bloom Filter Datatype for Redis in the Redis documentation.
Conclusion
Redis is often thought of as a cache, but with all the capabilities it offers, we at CMB consider it to be a first class database. All of our recommendations, exclusion lists, and mission-critical queues are implemented using a combination of Redis and small Python scripts. We hope this post sheds a bit of light on how we at CMB have thought of creative and innovative ways of using Redis. We hope this will empower new businesses and developers to experiment and innovate more!
About the authors
 Daniel Pyrathon is a Senior Machine Learning Engineer at Coffee Meets Bagel. In his spare time, Daniel is also one of the organizers of SF Python and PyBay, where he tries to connect Python industry leaders with the vibrating Bay Area community.
Daniel Pyrathon is a Senior Machine Learning Engineer at Coffee Meets Bagel. In his spare time, Daniel is also one of the organizers of SF Python and PyBay, where he tries to connect Python industry leaders with the vibrating Bay Area community.
 David O’Steen is the Data Team lead for Coffee Meets Bagel. He is responsible for driving the organization towards creating meaningful connections between our users.
David O’Steen is the Data Team lead for Coffee Meets Bagel. He is responsible for driving the organization towards creating meaningful connections between our users.