AWS Database Blog
Scale Amazon OpenSearch Service for AWS Database Migration Service migrations
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
A common pattern for web application architecture includes a database for application data coupled with a search engine for searching that data. Many relational and even nonrelational databases offer rudimentary search capabilities. However, search engines add true, complex, natural-language search with relevance and Boolean expressions to other database offerings. As Werner Vogels pointed out recently, a one-size-fits-all database doesn’t fit anyone. You use a relational or NoSQL database for the source of truth for your data, and a search engine (database) for searching that data.
How do you get your data from your database to Amazon Elasticsearch Service (Amazon ES), and how do you keep the two systems in sync? Until recently, you had to write scripts or augment your pipeline to bootstrap and synchronize your database with Amazon ES. In November 2018, AWS Database Migration Service (AWS DMS) added support for Amazon ES as a target for database migration. With AWS DMS, you can bootstrap your data into Amazon ES, and keep the systems in sync with the change data capture (CDC) facility of DMS.
This post gives you scale recommendations so that your Amazon ES domain has sufficient resources to process your DMS tasks. As with all scale recommendations, these are generalizations. Your mileage will vary!
Task settings parameters for AWS DMS
Using the Elasticsearch target in AWS DMS, it’s simple for you to get data from any of its supported sources to Amazon ES. You can migrate the data that you need quickly and securely. You can replicate database tables or views into your Amazon ES domain. The full load phase takes care of replicating all existing data in your source database. Ongoing changes in the database are processed during the CDC phase. AWS DMS uses the Elasticsearch _bulk API during its full load phase, and it sends individual updates during CDC.
AWS DMS supports multiple configuration parameters for migration tasks depending on the source and target endpoint type.
For the AWS DMS Elasticsearch target, these include the following parameters:
- MaxFullLoadSubTasks (default is 8):
This parameter determines the number of tables that can be transferred in parallel during full load. - ParallelLoadThreads (2–32 threads per table during full load):
This parameter determines the number of threads that can be allocated for a given table for the parallel transfer of data. Note: If you don’t changeParallelLoadThreadsfrom its default (0), AWS DMS sends a single record at a time. This puts undue load on your cluster, so make sure that you set it to 1 or more.
The following figure shows the architectural components that AWS DMS uses to transfer your data from your database to Amazon ES. The source database has four tables. The DMS task has MaxFullLoadSubTasks as 2. Each subtask copies one table’s data at a time. During full load, DMS creates a thread pool, with ParallelLoadThreads threads for each of the subtasks. Each thread then sends a _bulk API call with documents to index in the target Elasticsearch cluster.
For MaxFullLoadSubTasks as 2, we configured two subtasks. With ParallelLoadThreads as 3, each subtask has three threads sending data to Amazon ES.
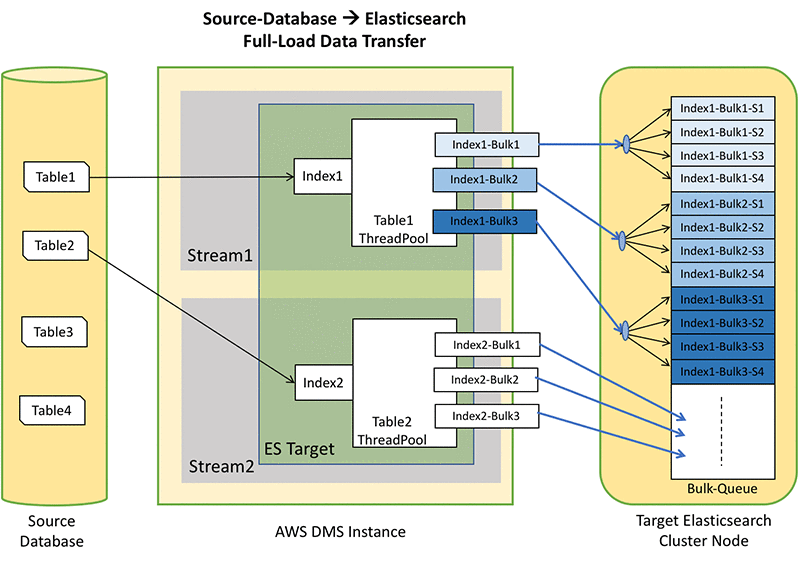
In the preceding figure, there are a total of 2 * 3 = 6 threads performing concurrent requests. In general:
# of concurrent _bulk requests = MaxFullLoadSubTasks * ParallelLoadThreads
Sizing for the Elasticsearch _bulk request queue
We’ve looked at the concurrency of calls created on the AWS DMS side. How does Elasticsearch deal with concurrent requests?
Elasticsearch organizes data into indexes. You can think of an Elasticsearch index as being equivalent to a relational database’s table. Elasticsearch has fields that are like database columns and values that are like database cell values. Under the covers, DMS takes each row and converts it to a JSON document where the column/value pairs are field/value pairs. It sends that document to an Elasticsearch index with the same name as the table or view and the same field name and value as they are in the source table.
Your shard strategy and your concurrency control how you use the resources in your Amazon ES domain. When you create your index in Amazon ES, you can specify a primary and replica shard count (the default is five primary shards and one replica). For a discussion about the number of shards and instances that are necessary, see the posts How Many Shards Do I Need? and How Many Data Instances Do I Need?
Elasticsearch distributes shards equally (by count) to the instances that you configure in your Amazon ES domain. When you send requests to an index, the shards use resources (CPU, disk, and network) from the instance.
Each instance in your Amazon ES domain has several queues, one for each of the various REST operations that the cluster processes. Each instance has a queue that receives requests (the request queue) with a depth of 200 items. Similarly, each instance has a queue for indexing requests, also with a depth of 200.
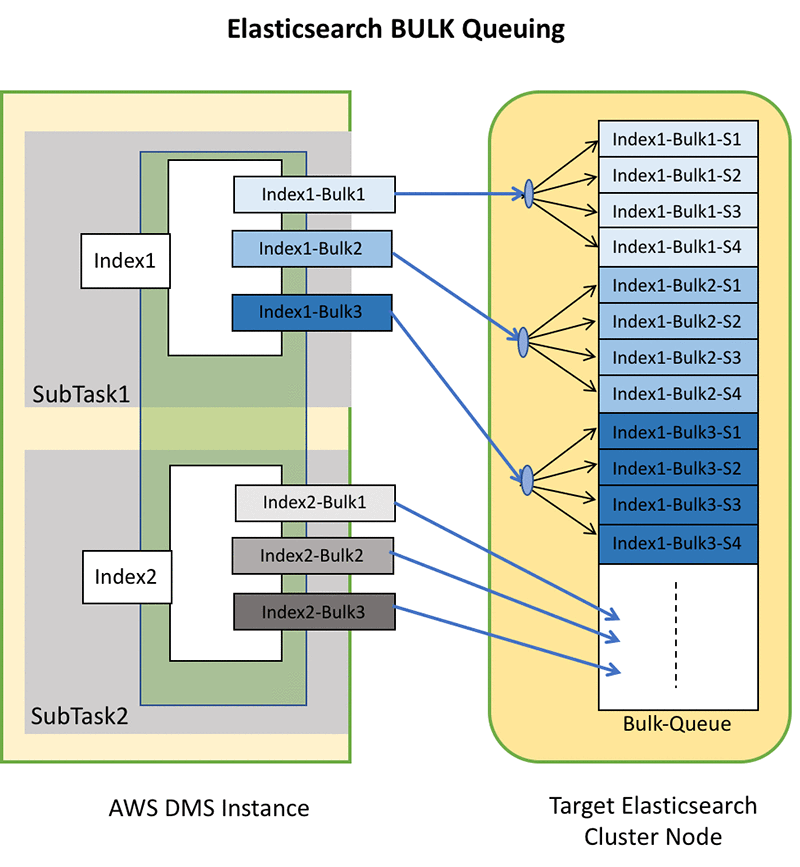
You must set MaxFullLoadSubTasks and ParallelLoadThreads carefully so that you don’t overflow the request and indexing queues. Each DMS _bulk request uses one slot in the Elasticsearch request queue, and N slots in the Elasticsearch indexing queue. N is the number of different indexes in the _bulk request times the number of shards in those indexes, times the number of replicas you configure for those indexes. (For more information about request processing in Elasticsearch and how it maps to your indexes and infrastructure, see this post on t-shirt sizing your domain.)
Continuing with the previous example, SubTask1 is transferring Index1, and SubTask2 is transferring Index2. We have already derived that the number of in-transit _bulk requests for each subtask is equal to ParallelLoadThreads.
Assume that Index1 has a shard count of 10 and replica 1.
The total number of queue slots required by a single _bulk request of Index1 is 10* 2 = 20.
With ParallelLoadThreads=3, indexing queue slots needed for Index1=20*3=60
Index2 has a shard count of 5 and replica 2.
The total number of queue slots required for a single _bulk request for Index2 is 5 * 3 = 15.
With ParallelLoadThreads=3, indexing queue slots needed for Index2=15*3=45
In sum: 60 + 45 = 105 indexing queue slots are needed while SubTask1 and SubTask2 are transferring Index1 and Index2 in parallel.
Elasticsearch returns code 429 when the queue overflows
When the indexing queue is full, Elasticsearch returns with the response code 429, “Too many requests,” and throws an es_rejected_execution_exception for the given _bulk request, as shown following.

If you start a full load DMS migration task that results in queuing more than the indexing queue capacity (200) entries per instance in your Amazon ES domain, the domain returns the response code 429. The load task then terminates.
You can find and monitor for these errors in the Amazon CloudWatch Logs log group that you designate for your DMS task.

In this example, the _bulk request had 4,950 documents corresponding to database records, but 1,943 records failed with Status 429 because the request exceeded the queue capacity. AWS DMS also provides information about the PrimaryKey of the corresponding failed database record.
Monitoring your Amazon ES domain’s usage
You can also monitor your indexing (and search) queues via metrics that Amazon ES exposes through CloudWatch. These metrics are available in your domain’s dashboard in the Cluster Health tab. Scroll to the Elasticsearch JVM thread pool section of the page to see the following graphs.
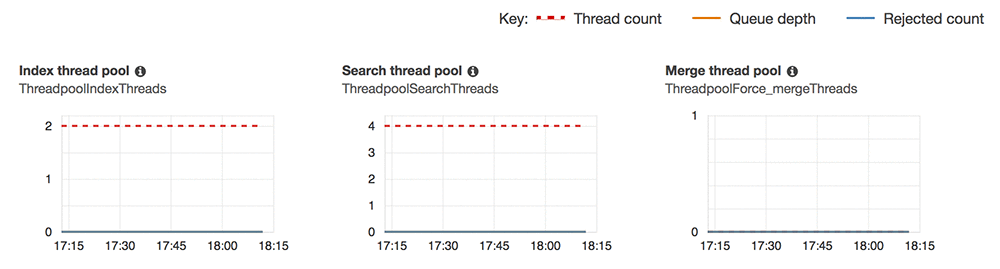
Amazon ES publishes a Thread count, Queue depth, and Rejected count for three of the Elasticsearch thread pools. You should monitor the Queue depth as a leading indicator that your ParallelLoadThreads and MaxFullLoadSubTasks are too high. In normal operation, Queue depth for your indexing queue should be at or near 0. If it is rising continuously or is above 100, you should add more data instances to your Amazon ES domain or reduce your ParallelLoadThreads and MaxFullLoadSubTasks. If you start to see a non-zero Rejected count, your domain has overflowed the indexing queue and has started rejecting requests. You need to reduce the load or scale up the domain’s data instances.
Conclusion
AWS Database Migration Service makes it simple to migrate and replicate data to Amazon Elasticsearch Service from any supported OLTP and OLAP database. With AWS DMS, you can bootstrap your tables into Amazon ES and stream changes from your tables to Amazon ES. To prepare for success, we dove deep into the details of Amazon ES request processing and how the parameters you set for your migration task use the resources in the cluster.
We recommend initially scaling by estimating the number of queue slots needed for your task based on the MaxFullLoadSubTasks and ParallelLoadThreads. We further recommend monitoring and setting CloudWatch alarms on your indexing Queue depth and Rejected count. With these guard rails in place, you’ll be searching your data in no time!
Learn more
We recently crossed 115,000 migrations and are celebrating it by writing a blog post that summarizes our latest release.
See the AWS website for more information about AWS Database Migration Service and the AWS Schema Conversion Tool.
About the Authors
 Riyaz Shiraguppi is a senior engineer with the Database Migration Service (DMS) at Amazon Web Services. He leads design and development of database migration projects as per our customer requirements, helping them improve the value of their solutions when using AWS. He was member of the core team which launched Amazon Elasticsearch Service in 2015.
Riyaz Shiraguppi is a senior engineer with the Database Migration Service (DMS) at Amazon Web Services. He leads design and development of database migration projects as per our customer requirements, helping them improve the value of their solutions when using AWS. He was member of the core team which launched Amazon Elasticsearch Service in 2015.
 Jon Handler is an AWS solutions architect specializing in search technologies. You can reach him @_searchgeek.
Jon Handler is an AWS solutions architect specializing in search technologies. You can reach him @_searchgeek.