AWS Database Blog
Unlocking cost-optimization: Open Raven’s journey with Amazon Aurora I/O-Optimized leads to 60% savings
Open Raven is a leader in automated multi-cloud data security. Open Raven is the data security posture management company that prevents leaks, breaches, and compliance incidents. The Open Raven Data Security Platform connects to your cloud environment within minutes and works over native APIs and serverless functions. The Open Raven Data Security Platform works at cloud scale, which is the ability to increase or decrease IT resources as needed to meet changing demand. It is fully customizable, and enables organizations to gain 360-degree visibility into their cloud data so they can prevent attacks, eliminate unnecessary costs and risks, and streamline compliance.
With the Open Raven Data Security Platform, security teams can quickly and automatically inventory data stores, classify data at petabyte-scale, pinpoint sensitive data, and identify risk. This provides immediate value, making it easy to spot shadow data and left-behind services, dangerous 3rd party network connections, unwanted data sharing relationships, and other risk factors. Open Raven uses a unique serverless architecture for data location, inventory, deep analysis, and accurate classification of cloud data where it lies without opening holes for potential attackers to exploit. The architecture ensures that no sensitive data is removed or copied into the Open Raven Data Security Platform at any time. The platform stores only metadata associated with discovered assets and scan findings, along with data snippets. Data snippets are small amounts of information related to findings that security analysts can safely use to quickly triage the discovery and determine a course of action without the risk of exposing sensitive information. Snippets are displayed in the Open Raven console as Data Previews, and the amount of data contained in a snippet is configurable by the customer. In the context of databases, this means that the Open Raven Data Security Platform is highly I/O intensive with reads and writes constantly occurring in the database through the span of a regular business day.
In this post, we share how Open Raven achieved cost-optimization using Amazon Aurora I/O-Optimized, a new storage configuration in Amazon Aurora that provides improved price-performance and predictable pricing for I/O-intensive applications.
Amazon Aurora I/O-Optimized
Amazon Aurora has been adopted and used by thousands of organizations to run critical transactional database workloads since its launch in 2014. With Aurora, you can now choose between two storage configurations: Aurora Standard or Aurora I/O-Optimized. For applications with low to moderate I/O, Aurora Standard is a cost-effective option. Aurora I/O-Optimized is a new configuration that provides predictable pricing for all applications and improved price-performance for I/O intensive applications. You pay a predictable price based on the consumption of your Aurora database instances and storage. This makes it easy for independent software vendors (ISVs) running multi-tenant software as a service (SaaS) applications to estimate their database spend up front.
Aurora I/O-Optimized also offers increased throughput and reduced latency to support your most demanding workloads. With I/O-Optimized, there are zero charges for read and write I/O operations in a particular Region — you only pay for your database instances and storage usage, making it easy to predict your database spend up front. If you’re using Reserved Instances, you will see even greater cost savings. To learn more, visit the Aurora Pricing page or Aurora storage and reliability in the Aurora User Guide.
Problem statement
Open Raven uses Amazon Elastic Kubernetes Service (Amazon EKS) with Amazon Aurora PostgreSQL-Compatible Edition as its database with 30 or so DB instances. Open Raven faced two challenges. First they wanted to optimize cost for their Aurora DB clusters and achieve predictable spend. Second, the team was contemplating an upgrade from Aurora PostgreSQL-Compatible major version 12 to 13 but the upgrade was very difficult to accomplish due to the effort and overall burden that was considered a strain on resources. Many new database features require version 13 or greater on Aurora, and Open Raven wanted to stay up to date. Aurora I/O optimized helped them accomplish both price and predictable spend without performance degradation as well as it created a justification for the upgrade to version 13.
Solution overview
The following diagram illustrates the solution architecture for Open Raven’s I/O-intensive workloads. Aurora PostgreSQL serves as the persistence layer for Open Raven’s data. Aurora PostgreSQL is the core data plane for their entire application. Open Raven has customer accounts where the customer logs in to the application and, using the EKS cluster, the workers are connected to Aurora PostgreSQL and the data is fetched from the Aurora PostgreSQL database.
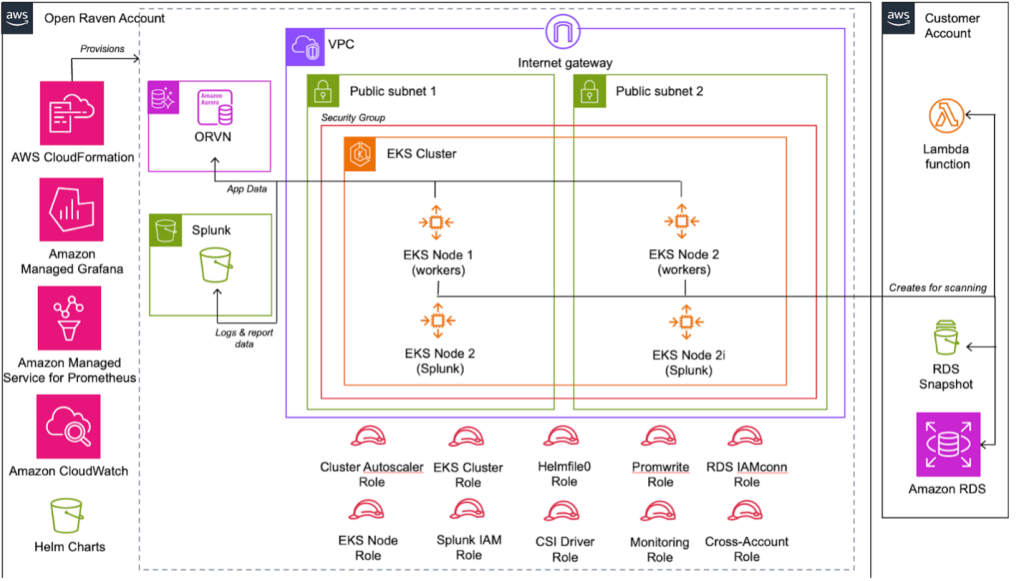
Open Raven’s environment consists of development, test, and production for their application. After learning about the Aurora I/O-Optimized feature, they switched their staging fleet which consisted of 8 development Aurora PostgreSQL clusters, to I/O-Optimized. They waited for 2–3 days for AWS Cost Explorer to give them the most up-to-date data. After seeing promising results (discussed below), they made the change to their test environment and moved an additional 19 clusters in their production fleet during their next release window (about a week later). They immediately saw cost savings with no performance degradation.
The choice for Aurora I/O-Optimized
Open Raven was looking to save costs on their Aurora PostgreSQL DB spend without impacting performance. Open Raven’s IT Operations team was able to quickly realize the cost savings that came along by switching to Aurora I/O-Optimized, assess that the switch was well worth the investment, and that also aligned with their goals of upgrading their Aurora PostgreSQL clusters. The results of this effort was a 60% cost reduction of their monthly Aurora spend.
The added benefit that came along with Aurora I/O-Optimized was no performance degradation. This was further tested and verified by the Open Raven team when they performed performance tests in their development and staging environments. Because switching to Aurora I/O-Optimized is an online operation, the ease of switching was another factor that was impactful in their decision to move to this new configuration. After a series of successful tests, Open Raven decided to switch all of their Aurora DB clusters to Aurora I/O-Optimized.
“Switching to Aurora I/O-Optimized is like black magic, you check off the box and done, no hiccups. No impact to performance, and I couldn’t believe the reduction in price was real!”
— Chris Webber, Engineering Director, IT and Operations, Open Raven
Benefits of switching to Aurora I/O-Optimized
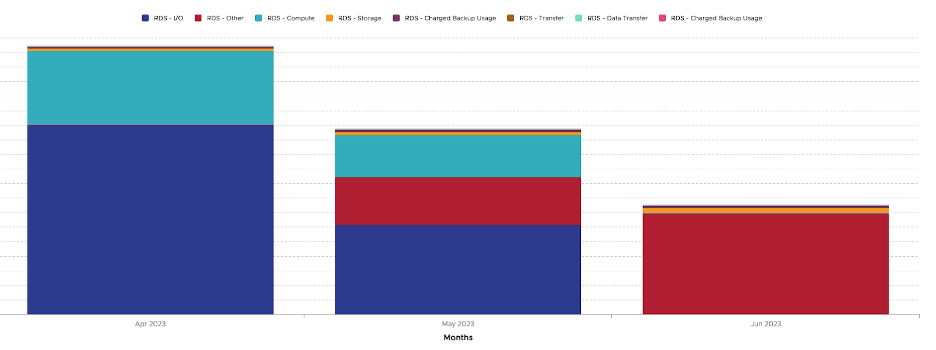
The graphs below are indicative of the realized benefits in terms of the cost savings that Open Raven noted in their RDS/Aurora telemetry graphs: The first and second graphs show the overall Aurora Spend in the Months from April to June. Both graphs show that there were IOPs spend in April and May with in dark blue and light blue respectively. Open Raven made the move to Aurora I/O optimized in the middle of May and the graphs depict that the I/O spend had decreased from the previous month. For the month of June, there is no longer any spend on I/O and the overall cost decreased month over month. The third graph is their overall AWS spend over a one year period with a decrease in overall spend once I/O optimized was implemented.


Conclusion
In this post, we discussed how Open Raven was able to take advantage of cost savings without performance degradation using Aurora I/O-Optimized. Based on their use case and I/O-intensive workloads, Open Raven was a perfect fit to migrate their workloads to Aurora I/O-Optimized while saving about 60% of their total Aurora spend. Lastly, Open Raven was able create price predictability, enabling them to plan for future workloads to be moved to Aurora I/O-Optimized.
If you have any questions or comments, leave them in the comments section.
About the authors
 Pete Mikhail is a Database Sales Specialist that works with Startup Companies in the US. We work with customers to help them achieve their database goals and strategies while aiding in the internal and external processes.
Pete Mikhail is a Database Sales Specialist that works with Startup Companies in the US. We work with customers to help them achieve their database goals and strategies while aiding in the internal and external processes.
 Sarabjeet Singh is a Database Specialist Solutions Architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Sarabjeet Singh is a Database Specialist Solutions Architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
 Shayon Sanyal is a Principal Data Specialist Solutions Architect and a Subject Matter Expert for Amazon’s flagship relational database, Amazon Aurora. Shayon’s relentless dedication to customer success allows him to help customers design scalable, secure and robust cloud native architectures. Shayon also helps service teams with design and delivery of pioneering features.
Shayon Sanyal is a Principal Data Specialist Solutions Architect and a Subject Matter Expert for Amazon’s flagship relational database, Amazon Aurora. Shayon’s relentless dedication to customer success allows him to help customers design scalable, secure and robust cloud native architectures. Shayon also helps service teams with design and delivery of pioneering features.
 Atul Shah is a Senior Worldwide Go-To-Market Specialist for Amazon RDS and Aurora PostgreSQL. Atul helps customer’s migration and transformation journey by evangelizing RDS and Aurora PostgreSQL services by working backwards from customer’s requirements. By listening to customer feedback, Atul also helps prioritize new features into the future roadmap of these services.
Atul Shah is a Senior Worldwide Go-To-Market Specialist for Amazon RDS and Aurora PostgreSQL. Atul helps customer’s migration and transformation journey by evangelizing RDS and Aurora PostgreSQL services by working backwards from customer’s requirements. By listening to customer feedback, Atul also helps prioritize new features into the future roadmap of these services.