AWS Database Blog
Unlocking JSON workloads with ElastiCache and MemoryDB
Application developers love Redis because it has a large and vibrant open source community, provides blazing-fast in-memory performance, and has a developer-friendly yet powerful API that provides native support for multiple data structures. These traits make Redis a great fit for building and running high-performance, scalable web applications.
At AWS, we offer two fully-managed, Redis-based services: Amazon ElastiCache for Redis for caching and ephemeral data storage, and Amazon MemoryDB for Redis, an in-memory primary database for applications that require a higher level of data durability. Our customers use these services to accelerate performance for a wide range of use cases, from mobile payments to gaming leaderboards, Internet of Things (IoT) analytics, ride sharing, and real-time ad serving. They’ve chosen us because of our track record of operational stability and the price-performance enhancements that we’ve made, such as Enhanced IO, multi-flow TCP, and data tiering.
Today, we’re excited to announce that we’re unlocking even more power for Redis application developers by providing native support for JavaScript Object Notation (JSON) within ElastiCache and MemoryDB. JSON is a near ubiquitous way to encode and exchange data, and it’s now even simpler to store and access JSON documents inside ElastiCache and MemoryDB. This launch simplifies ElastiCache caching for our purpose-built document database, Amazon DocumentDB (with MongoDB compatibility), as well as working with durable JSON inside MemoryDB. JSON support is available in all ElastiCache and MemoryDB regions at no additional cost. To get started, simply create a new cluster using Redis version 6.2 or greater and you’ll have the new JSON data type and associated commands available.
The rest of this post will cover how our JSON support works at a more technical level and provide examples of how you can write JSON documents, efficiently fetch or set portions of a JSON document in Redis, and search your JSON documents’ content using the Goessner-style JSONPath query language.
JSON in ElastiCache and MemoryDB
Although JSON is a standard serialization format for the interchange of structured data (RFC 8259, ECMA 404), JSON support in ElastiCache and MemoryDB provides much more than simple storage and retrieval of JSON-encoded data. It simplifies the development of applications that store complex data structures by providing powerful searching and filtering capabilities. As shown in the following section, many application operations on complex data structures that previously required substantial development time as well as multiple expensive network round-trips can be easily and naturally expressed in a single JSON command. This results in a dramatic improvement in developer productivity and system improvement, as well as reduction in operational costs.
The new Redis JSON datatype offers six types of values, four primitive (null, boolean, number, and string), and two composite (object and array). The composites map either a string or a dense integer key to a value. However, unlike other Redis composites, JSON composites can contain any of the six value types in any combination, including other JSON composites, i.e., recursion. The ability to freely intermix these value types provides a natural way to represent nearly any structured data.
Client applications use the serialized format to communicate with the service. However, internally the data is stored using a tree-like binary format for efficient traversal and manipulation. The tree-like format allows operations to be performed on sub-trees just as efficiently as when operating on an entire JSON key. In the following description, the term “element” will be used generically to indicate any JSON value, including when the value is just a primitive like a string or a number or when it’s a composite of other values.
The JSON datatype is fully integrated into the Redis access control lists (ACL) capability. All JSON commands correctly enforce any keyspace or command restrictions or permissions. Just like the existing per-datatype categories (@string, @hash, etc.) a new category @json is added to simplify managing access to JSON commands and data.
Most JSON commands accept not only a key, but also one or more paths. A path is an expression that identifies the element or elements of the JSON document within the key on which the command is to operate. The syntax and semantics of the path closely follow the original Goessner JSONPath proposal. See our documentation for more information about JSONPath.
Redis and JSON in action
To illustrate some of the power of JSON data and JSON paths, let’s take a data structure, such as a list of employees, and see how some simple operations can be coded.
We’ll represent the list of employees as an array of objects, one object for each employee. Our example data is as follows:
Fetching an employee object by an attribute like the “ID” field is simple:
There’s no reason that the selection attribute can’t have multiple responses. Here the query returns the employee records of all of the employees located in building F2:
But, you don’t have to fetch entire employee records, you can pick a field like ID to be returned. This query returns the ID of all of the female employees:
Even though JSON doesn’t have a dedicated primitive for timestamps, you can use strings to represent them. This query returns all of the employees hired since January 1, 2020:
Query filters aren’t limited to a single field, and you can combine multiple filters. This query finds all of the male employees hired since January 1, 2020:
These examples provide only a small glimpse into the possibilities for the JSON datatype.
Redis and JSON Performance
The dataset above was chosen to make it easy to understand examples of the capabilities of paths and filter expressions. We need a larger dataset to get a view into the performance of JSON paths and filters. One of the commonly used datasets to benchmark JSON performance is in the file update-center.json (see here). This file is 521KB in size.
Each of the following performance tests was generated by running redis-benchmark on ten (10) client systems (c5n.xlarge), where each client system utilized ten (10) parallel connections for a total of 100 parallel connections. Each test was run on a single-node r6g cluster of ElastiCache for Redis. The test is repeated once for each reported instance size. All of the systems were in the same availability zone. The reported results are the average of the sum of the requests-per-second (rps) for the 100 connections.
As a baseline, we tested the performance of fetching an entire JSON document.
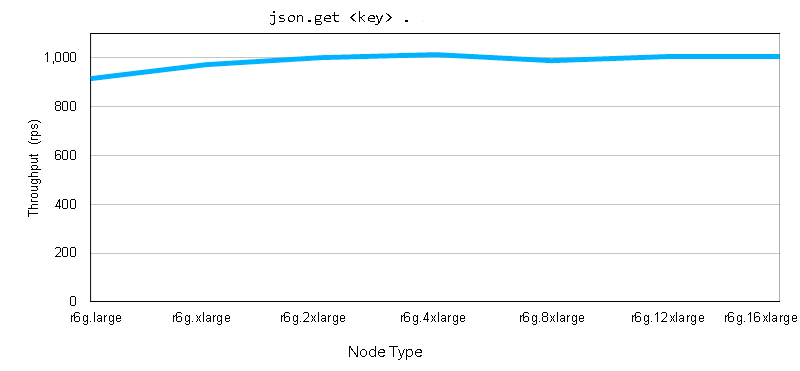
With the baseline established, we then ran a test that fetched a single string identified by a path. Generally, the components of a path that select a specific element execute in O(1) time. This means that the performance is directly related to the network cost of transferring the selected data, independent of the total amount of JSON data in the Redis key. Here the selected data string is small, thus yielding correspondingly high throughput.

This next test builds on the last example. A single string of a JSON document is identified by a path and is updated to a new value. As with the read case, the cost of the path is O(1) and yields high throughput when combined with the small string size.

This next example tests query performance when using a filter. Because the data is primarily organized as an object, the recursive search operator (..) must be used. This operator is O(N) for the amount of data being searched. Here, the plugin object contains 654 members, and each of those members has between 15 and 20 members, resulting in the filter operation being applied more than 10K times with a corresponding effect on performance.
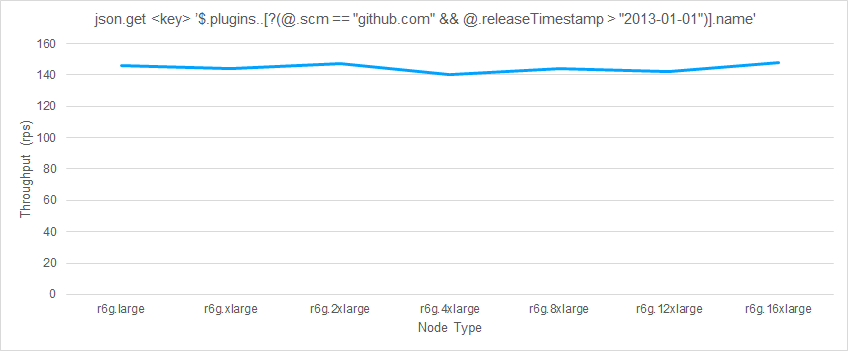
Here’s the write/set performance of the previous example.

You can optimize query performance when using filters by modifying the composition of your JSON documents. Specifically, when converting the plugin object into an array and using array search, the filter will be applied to only the 654 members and not recursively to the 15-20 members within each element (i.e., 10K times). This short Python program was used to convert the plugin object of the update-center.json file into an array. The output of this program was used for the following tests:
Repeating the same queries as above (modified to use the array search instead of the recursive search) yields approximately a 25x improvement to throughput.


This particular series of example tests was chosen to illustrate not only the power of JSON paths and filters, but also the sensitivity to the contents and structure of the data being used. Since your overall performance is a function both of the shape of your JSON data and the nature of the queries being performed, we recommend testing using a dataset with structure and content that mimics your production environment as closely as possible.
Wrapping up
The addition of JSON support inside ElastiCache and MemoryDB simplifies the development of applications as well as improves performance and reliability. Using the new JSON datatype simplifies or eliminates complicated and error-prone conversions required to use the other built-in Redis data types. Simplifying or eliminating these conversions can not only accelerate application development, but also improve application reliability. You can achieve higher performance by using the server-side processing capabilities to eliminate situations where multiple database requests would otherwise be required.
To get started, create a new cluster in the ElastiCache console or the MemoryDB console, and take a look at additional examples and the command reference in our documentation (ElastiCache, MemoryDB).
About the Authors
 Allen Samuels is a Principal Engineer at Amazon Web Services. He is passionate about
Allen Samuels is a Principal Engineer at Amazon Web Services. He is passionate about
distributed, performant systems. When not travelling the world for pleasure or playing duplicate bridge, Allen can be found in San Jose, California.
 Joe Travaglini leads Product Management for Amazon ElastiCache and Amazon MemoryDB and has spent the past 6 years in product roles at AWS. Prior to joining Amazon, he was Director of Products at Sqrrl, a cybersecurity analytics startup acquired by AWS. Other than helping customers get the most out of the cloud, Joe enjoys spending time with family, rooting for Boston sports teams, and practicing as an amateur/home chef.
Joe Travaglini leads Product Management for Amazon ElastiCache and Amazon MemoryDB and has spent the past 6 years in product roles at AWS. Prior to joining Amazon, he was Director of Products at Sqrrl, a cybersecurity analytics startup acquired by AWS. Other than helping customers get the most out of the cloud, Joe enjoys spending time with family, rooting for Boston sports teams, and practicing as an amateur/home chef.
 Joe Hu is a Software Development Engineer in AWS In-Memory Databases team, based in Boston. He is passionate about building large scale distributed cloud services. He has spent the majority of his career in the areas of database internals, column store, replication, backup & restore, and distributed query processing. In his leisure time, Joe actively plays table tennis at local clubs and occasionally competes in regional tournaments.
Joe Hu is a Software Development Engineer in AWS In-Memory Databases team, based in Boston. He is passionate about building large scale distributed cloud services. He has spent the majority of his career in the areas of database internals, column store, replication, backup & restore, and distributed query processing. In his leisure time, Joe actively plays table tennis at local clubs and occasionally competes in regional tournaments.