AWS Developer Tools Blog

.NET 6 on AWS
Congratulations to all the development teams and community involved in the .NET 6 GA release. .NET developers here at AWS are excited about the performance improvements in JIT compilation, Garbage Collection, JSON processing, and many other areas of the new release. We’re also excited about the new features including the Minimal API Framework, new data […]
Testing CDK Applications in Any Language
The AWS Cloud Development Kit (AWS CDK) is an open source software development framework to define your cloud application resources using familiar programming languages. Because the AWS CDK enables you to define your infrastructure in regular programming languages, you can also write automated unit tests for your infrastructure code, just like you do for your […]

Experimental construct libraries are now available in AWS CDK v2
The AWS CDK v2 experimental APIs are now available as separate packages, in addition to the existing stable APIs. The AWS Cloud Development Kit (AWS CDK) is an open-source software development framework to model and provision your cloud application resources using familiar programming languages. With the AWS CDK, you can define your infrastructure as code […]
Deployment Projects with the new AWS .NET Deployment Experience
In the last post about our new AWS .NET Deployment tooling I talked about some of the recent updates we have made. I did skip a very important feature called deployment projects because I thought it deserved it’s own post. A major goal with the new deployment tooling is not to have unseen magic happening […]
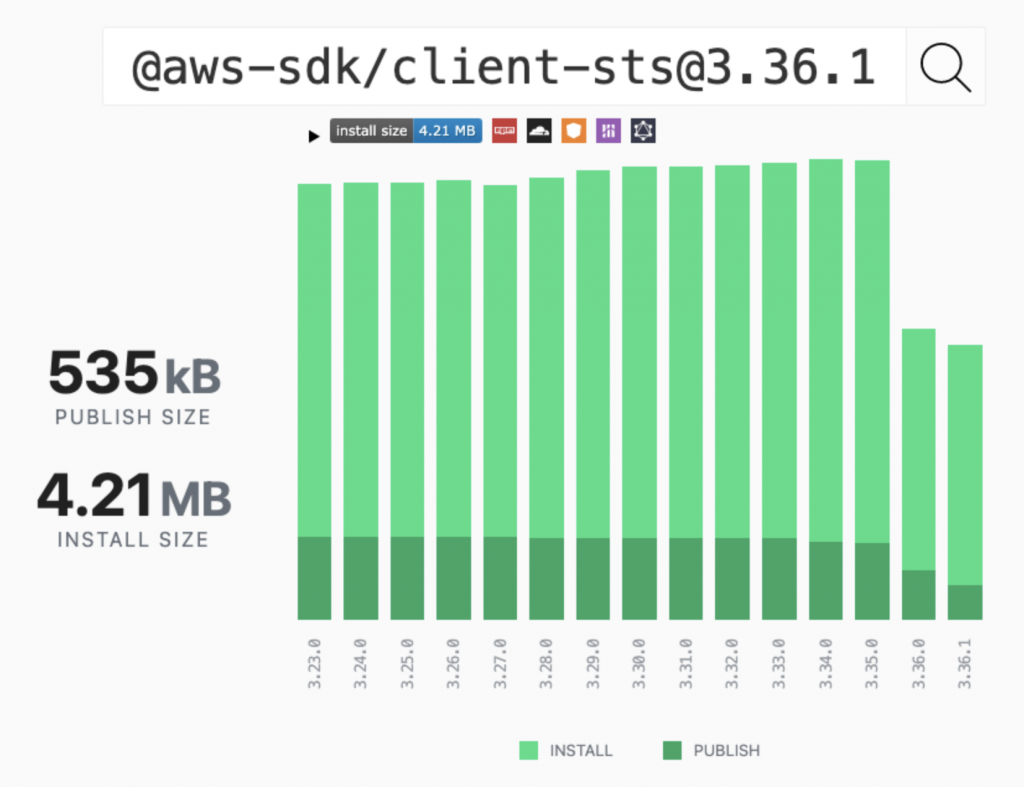
How we halved the publish size of modular AWS SDK for JavaScript clients
On December 15th, 2020, we announced the general availability of the AWS SDK for JavaScript, version 3 (v3). In v3, the modular packages reduce the bundle size of your application by ~75% as compared to that in AWS SDK for JavaScript, version 2 (v2). However, v3 had a large publish/install size for each modular package. In […]

Update on our new AWS .NET Deployment Experience
Last spring we announced the preview of our new AWS deployment tooling for .NET. We have been very busy adding new features since then, with new releases about every two weeks. Let’s take a look at some of the features we have shipped since the initial release. Getting Started As a reminder, the new AWS […]

AWS Batch Application Orchestration using AWS Fargate
Many customers prefer to use Docker images with AWS Batch and AWS Cloudformation for cost-effective and faster processing of complex jobs. To run batch workloads in the cloud, customers have to consider various orchestration needs, such as queueing workloads, submitting to a compute resource, prioritizing jobs, handling dependencies and retries, scaling compute, and tracking utilization […]

Announcing new AWS SDK for Swift alpha release
We’re excited to announce the alpha release of the new AWS SDK for Swift. Since 2010, AWS Mobile has provided customers with an iOS SDK, written in Objective C. While this SDK has served the iOS community for over a decade, the Swift community has grown in size and expanded to other platforms such as […]

Announcing new AWS SDK for Kotlin alpha release
We’re excited to announce the alpha release of the new AWS SDK for Kotlin! Kotlin is one of the most-loved languages amongst developers and now the AWS SDK for Kotlin makes it easy to call AWS services using idiomatic Kotlin APIs. You can use the native Kotlin language constructs you are used to, have mobile support […]

Virus scan S3 buckets with a serverless ClamAV based CDK construct
Edit: March 10th 2022 – Updated post to use AWS Cloud Development Kit (CDK) v2. Protecting systems from malware is an essential part of a systems protection strategy. It is important to both scan binaries and other files before introducing them into your system boundary and appropriately respond to potential threats in accordance to your […]