AWS DevOps Blog
Tag: New stuff
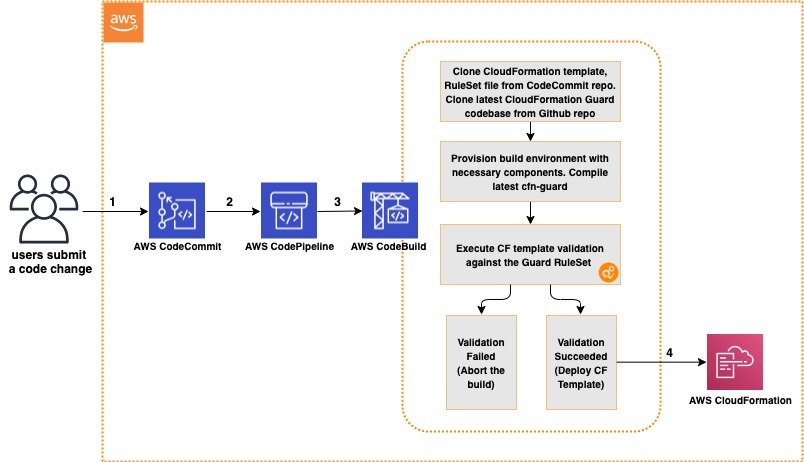
Integrating AWS CloudFormation Guard into CI/CD pipelines
In this post, we discuss and build a managed continuous integration and continuous deployment (CI/CD) pipeline that uses AWS CloudFormation Guard to automate and simplify pre-deployment compliance checks of your AWS CloudFormation templates. This enables your teams to define a single source of truth for what constitutes valid infrastructure definitions, to be compliant with your […]

New – How to better monitor your custom application metrics using Amazon CloudWatch Agent
This blog was contributed by Zhou Fang, Sr. Software Development Engineer for Amazon CloudWatch and Helen Lin, Sr. Product Manager for Amazon CloudWatch Amazon CloudWatch collects monitoring and operational data from both your AWS resources and on-premises servers, providing you with a unified view of your infrastructure and application health.

How to Enable Caching for AWS CodeBuild
AWS CodeBuild is a fully managed build service. There are no servers to provision and scale, or software to install, configure, and operate. You just specify the location of your source code, choose your build settings, and CodeBuild runs build scripts for compiling, testing, and packaging your code. A typical application build process includes phases […]

AWS Developer Tools Expands Integration to Include GitHub
AWS Developer Tools is a set of services that include AWS CodeCommit, AWS CodePipeline, AWS CodeBuild, and AWS CodeDeploy. Together, these services help you securely store and maintain version control of your application’s source code and automatically build, test, and deploy your application to AWS or your on-premises environment. These services are designed to enable […]
Introducing Amazon CloudWatch Logs Integration for AWS OpsWorks Stacks
AWS OpsWorks Stacks now supports Amazon CloudWatch Logs. This benefits all users who want to stream their log files from OpsWorks instances to CloudWatch. This enables you to take advantage of CloudWatch Logs features such as centralized log archival, real-time monitoring of log data, or generating CloudWatch alarms. Until now, OpsWorks customers had to manually […]
Introducing Git Credentials: A Simple Way to Connect to AWS CodeCommit Repositories Using a Static User Name and Password
Today, AWS is introducing a simplified way to authenticate to your AWS CodeCommit repositories over HTTPS. With Git credentials, you can generate a static user name and password in the Identity and Access Management (IAM) console that you can use to access AWS CodeCommit repositories from the command line, Git CLI, or any Git tool […]
DevOps and Continuous Delivery at re:Invent 2016 – Wrap-up
The AWS re:Invent 2016 conference was packed with some exciting announcements and sessions around DevOps and Continuous Delivery. We launched AWS CodeBuild, a fully managed build service that eliminates the need to provision, manage, and scale your own build servers. You now have the ability to run your continuous integration and continuous delivery process entirely […]
Building a Microsoft BackOffice Server Solution on AWS with AWS CloudFormation
Last month, AWS released the AWS Enterprise Accelerator: Microsoft Servers on the AWS Cloud along with a deployment guide and CloudFormation template. This blog post will explain how to deploy complex Windows workloads and how AWS CloudFormation solves the problems related to server dependencies. This AWS Enterprise Accelerator solution deploys the four most requested Microsoft […]
AWS CodeDeploy Deployments with HashiCorp Consul
Learn how to use AWS CodeDeploy and HashiCorp Consul together for your application deployments. AWS CodeDeploy automates code deployments to Amazon Elastic Compute Cloud (Amazon EC2) and on-premises servers. HashiCorp Consul is an open-source tool providing service discovery and orchestration for modern applications. Learn how to get started by visiting the guest post on the AWS Partner Network Blog. You […]
Using Custom JSON on AWS OpsWorks Layers
Custom JSON, which has always been available on AWS OpsWorks stacks and deployments, is now also available as a property on layers in stacks using Chef versions 11.10, 12, and 12.2. In this post I show how you can use custom JSON to adapt a single Chef cookbook to support different use cases on individual […]