AWS DevOps & Developer Productivity Blog
Category: How-To

Diving Deeper into Projen: Exploring Advanced Features
We will be highlighting Projen’s powerful features that cater to various aspects of project management and development. We’ll examine how Projen enhances polyglot programming within Amazon Web Services (AWS) Cloud Development Kit constructs. We’ll also touch on its built-in support for common development tools and practices. In our previous blog, we introduced you to the […]

Exploring Telemetry Events in Amazon Q Developer
As organizations increasingly adopt Amazon Q Developer, understanding how developers use it is essential. Diving into specific telemetry events and user-level data clarifies how users interact with Amazon Q Developer, offering insights into feature usage and developer behaviors. This granular view, accessible through logs, is vital for identifying trends, optimizing performance, and enhancing the overall […]

Implementing long running deployments with AWS CloudFormation Custom Resources using AWS Step Functions
AWS CloudFormation custom resource provides mechanisms to provision AWS resources that don’t have built-in support from CloudFormation. It lets us write custom provisioning logic for resources that aren’t supported as resource types under CloudFormation. This post focusses on the use cases where CloudFormation custom resource is used to implement a long running task/job. With custom […]

Create CIS hardened Windows images using EC2 Image Builder
Many organizations today require their systems to be compliant with the CIS (Center for Internet Security) Benchmarks. Enterprises have adopted the guidelines or benchmarks drawn by CIS to maintain secure systems. Creating secure Linux or Windows Server images on the cloud and on-premises can involve manual update processes or require teams to build automation scripts […]

CICD on Serverless Applications using AWS CodeArtifact
Developing and deploying applications rapidly to users requires a working pipeline that accepts the user code (usually via a Git repository). AWS CodeArtifact was announced in 2020. It’s a secure and scalable artifact management product that easily integrates with other AWS products and services. CodeArtifact allows you to publish, store, and view packages, list package […]
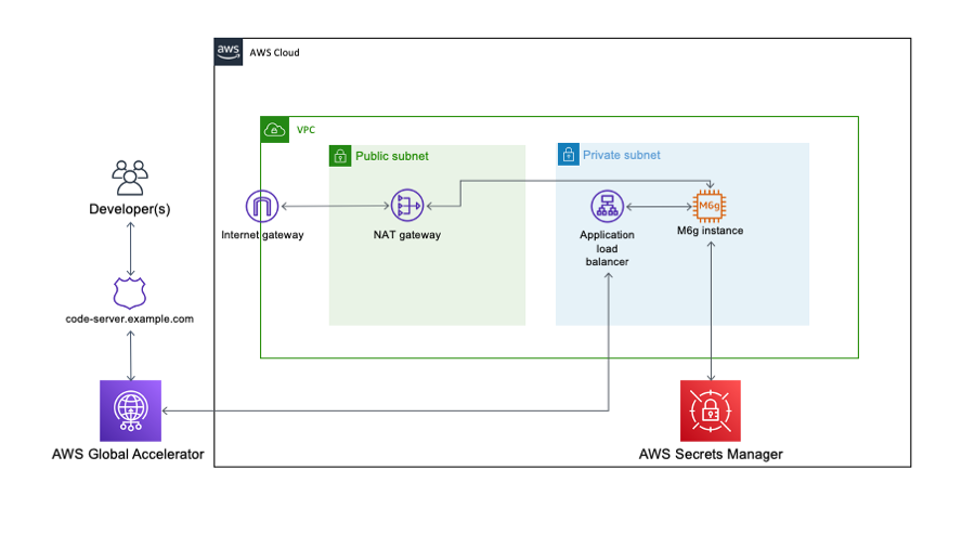
Building an ARM64 Rust development environment using AWS Graviton2 and AWS CDK
2020 was the year that ARM chips made the headlines by moving from largely mobile form factors into the cloud thanks to AWS Graviton2, allowing you to have up to 40% better price performance over comparable current generation x86 Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Relational Database Service (Amazon RDS) instances. We speak […]

Building, bundling, and deploying applications with the AWS CDK
Learn how to perform application build commands as part of your AWS CDK build process by using the native AWS CDK bundling functionality.

Improving customer experience and reducing cost with CodeGuru Profiler
Amazon CodeGuru is a set of developer tools powered by machine learning that provides intelligent recommendations for improving code quality and identifying an application’s most expensive lines of code. Amazon CodeGuru Profiler allows you to profile your applications in a low impact, always on manner. It helps you improve your application’s performance, reduce cost and […]
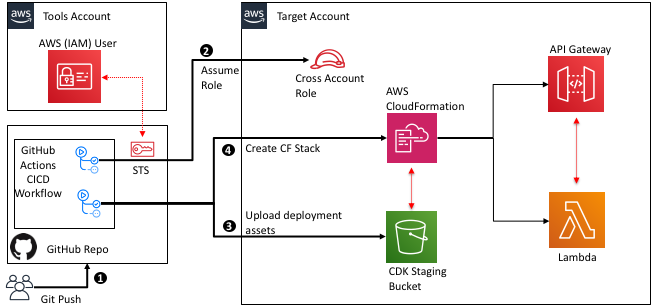
Cross-account and cross-region deployment using GitHub actions and AWS CDK
GitHub Actions is a feature on GitHub’s popular development platform that helps you automate your software development workflows in the same place you store code and collaborate on pull requests and issues. You can write individual tasks called actions, and combine them to create a custom workflow. Workflows are custom automated processes that you can […]

Improve Build Performance and Save Time Using Local Caching in AWS CodeBuild
AWS CodeBuild now supports local caching, which makes it possible for you to persist intermediate build artifacts locally on the build host so that they are available for reuse in subsequent build runs. Your build project can use one of two types of caching: Amazon S3 or local. In this blog post, we will discuss […]