AWS Executive in Residence Blog
Strategy Is a Winding Road. Mechanisms Keep You on Track.
 You don’t hike up a mountain in a straight line. Rather, gentle slopes and switchbacks allow you to make a gradual ascent. Even though you aren’t heading straight for your goal, you keep an eye on the top of the mountain and track your progress by the changing scenery or elevation. If you haven’t encountered a switchback turn in a while, you might look at a map to make sure you didn’t take a wrong turn. Small dips, while seemingly taking you away from your goal, are a given and something you need to account for: you’ll climb more than the total elevation gain. Occasionally, you need to take a detour—maybe you need to avoid a blockage or washed-out trail—but you make sure that you’ll merge back onto the main path.
You don’t hike up a mountain in a straight line. Rather, gentle slopes and switchbacks allow you to make a gradual ascent. Even though you aren’t heading straight for your goal, you keep an eye on the top of the mountain and track your progress by the changing scenery or elevation. If you haven’t encountered a switchback turn in a while, you might look at a map to make sure you didn’t take a wrong turn. Small dips, while seemingly taking you away from your goal, are a given and something you need to account for: you’ll climb more than the total elevation gain. Occasionally, you need to take a detour—maybe you need to avoid a blockage or washed-out trail—but you make sure that you’ll merge back onto the main path.
Executing a strategy is a quite similar exercise. As shared in my previous post, choosing a goal is comparatively easy. However, walking the path there might lead you through many twists and turns, and the occasional detour. So, you’ll want something to help you stay on track.
Strategic Paths Aren’t Straight Lines
A strategy isn’t a point on a map (that’d be your goal) but a path from where you are to where you want to be. That path is shaped by the meaningful decisions you make, those where turning left would have been a viable option but you chose to turn right. That’s why a strategy is rarely a straight shot, just like walking up a mountain. You might be taking a series of switchbacks but they’re going to lead you to your goal because you keep an eye on the target and adjust as needed.
Cloud Strategies Neither
Cloud transformations follow similar routes. The shortest path might be to modernize all your applications so that they are cloud native, scale via serverless runtimes, store data in fully managed NoSQL data stores, and auto-optimize with machine learning tools. That’s what things look like when you’re standing on top of the cloud hill!
Alas, that’s also the steepest path up the mountain and one that’s rather difficult for a complex enterprise to take across a vast IT estate. So, you have to make smaller, incremental steps. You might move some applications to the cloud “as is” for an initial gain in availability and transparency. Next, perhaps you migrate some components, like data stores, to managed services to reduce cost and operational toil. Factoring out components that must respond to sudden load spikes to a serverless runtime like AWS Lambda could be a meaningful step on your next switchback.
You might even want to run multiple instances of an existing system to ease migration. An outside observer might be surprised by that decision because multiple instances can increase operational complexity and costs. But just like walking up a hill via a serpentine road may look like you’re moving sideways, the temporary duplication might be the fastest path to value when you’re operating in a global environment and when lining up regulatory approvals for all markets could take a long time. Intermediate stages that seem suboptimal are virtually a given on your transformation path. You can’t expect to just climb straight up.
Staying on Track
In a recent customer conversation, the customer’s CIO and I were discussing their major transformation program when he commented on one team’s effort to rewrite mainframe legacy code in Java. To his dismay, they ended up with a 4000-line Java class, perhaps not the pinnacle of object-oriented decomposition or design for testability. So, it looked like the team didn’t gain a ton of elevation on their hike up the cloud-native peak that’s home to fine-grained, stateless functions that are ideal for deployment in a serverless environment.
Might they be on the right path, though? Only the next switchback can tell. Perhaps creating one large Java class was just an intermediate step that simplified validating that the existing logic is correctly replicated. Once in Java-land, the team has many more tools at their disposal: automated refactorings, unit tests, and code coverage tools can assist the team to better structure the code for understandability and maintainability. So, just as you might think that a hiker isn’t going the right way (up) when you see them traversing, this team might actually be on a good path.
Traversing the mountain by decomposing classes might seem like lack of progress to some: there’s no new functionality to show. However, it might prepare the team for a much shorter next step to real elevation gain. This can be difficult for teams to explain to stakeholders when they’re on the arduous ascent from a deep legacy valley. To judge a team’s progress, you must have a view of the terrain. At the same time, the team has to be committed to taking the next turn and to keep on climbing—otherwise they’re really just out for a stroll.
Connecting the overall strategy to short-term tactics that might appear to lead a team sideways is an important ingredient in successful transformations.
Good Intentions Don’t Work—Mechanisms Do
Executing strategies is an endeavor that’s full of switchbacks and detours. How do you assure, though, that a detour doesn’t end up being the wrong path? How do you know if a team needs to take the next switchback? How long before you have to declare yourself lost?
There are no magic answers, but at Amazon Web Services (AWS), we’ve walked many winding roads and discovered a few good practices that keep you on track. The most useful one is implementing mechanisms. At Amazon we have a common saying: “Good intentions don’t work—mechanisms do.” Perhaps that’s how we stay off the road to hell (or your favorite unfavorite place) that’s apparently lined with such intentions. We find that good intentions don’t solve problems because people generally had good intentions when the problem occurred in the first place.
Mechanisms are complete processes that consist of tools, adoption (actual usage of the tool), and inspection (to verify that the mechanism works). They are also a great way to make sure your inevitable detour merges back to the main strategic path. A friend of mine instituted a very effective mechanism to keep their large-scale cloud migration on track. The team would allocate their on-premises data center cost across the remaining applications. In other words, remaining on premises would become increasingly expensive for application teams as there’s fewer applications left to split the cost. You certainly don’t want to run the last application that’s left and bear the whole cost of a legacy data center. This mechanism worked much better than good intentions, reminders, and deadline extensions. Teams had the freedom to take a temporary detour or a traverse if needed, but the mechanism assured that no one would be keen to stray off the intended path for a long time.
The aforementioned mainframe legacy migration could benefit from a similar mechanism. The tools could be based on metrics for how many code modules are rewritten and a code quality metric, such as test coverage or modularity, for those new modules. This’ll reward people for rewriting old code but also for subsequent refactoring—it’s difficult to achieve good coverage on a giant Java class with humongous methods. So a team that just rewrote existing poorly structured code would have a clear incentive to take a switchback and invest time into refactoring code.
Adopting a tool is something that you can rarely mandate (at least if you expect it to work), so the best path to adoption is to give teams the right tools to make following the desired path as easy as possible. As you’ve surely seen on hiking trails, people will take shortcuts if they’re easier than staying on the designated path. For legacy code migration, teams will appreciate powerful development environments, efficient test frameworks, and fast support in case they get stuck on an obstacle like ambiguous or defective legacy code. The risk with any metric, especially those that lead to rewards, is that teams will work to achieve the metric over achieving the original purpose of the metric. That’s why you’d want to inspect whether the mechanism works to make sure that the tools remain meaningful and recognize whether teams are gaming the system.
Mechanisms Aren’t Guardrails
When enterprises discuss steering teams to a desired behavior, there’s often talk about guardrails, defined boundaries within which teams should operate. These guardrails can be standard products or programming languages that should be used, or the runtime environments in which they can be deployed. However, guardrails in real life, and in enterprises, are a last-resort safety mechanism.
No driver would be happy to have their path corrected by a guardrail. A guardrail is a safety device that might save a driver from a serious accident in an extreme situation. However, it’s not very effective at steering a driver: scraping along the guardrail to follow the road would not only damage the car but also cause enormous friction, an effect that’s seen in enterprises also. Instead, drivers use road markings and their car’s lane keeping assist system to drive safely.
Enterprise guardrails tend to be all-or-nothing prescriptions: teams can’t use database X or programming language Y and all submitted code must include some tests. Just like guardrails on the road, they might prevent mayhem such as storing sensitive data in public data stores and pushing code that’s full of security exploits, but they do little to gently steer teams toward a good outcome. In comparison, mechanisms provide a gentle pull for teams to stay on the right path and not hit the guardrail.
A nice example of helping teams stay in their lane is the core theme of a blog post by our Enterprise Strategy head, Phil Potloff. Phil described that keeping cycle time down—in other words, reducing the time required to build, test, and deploy a new piece of code—remained a challenge for many teams. The resulting mechanism was to make cycle time a finite resource like budget, headcount, or timelines. Teams are free to balance against these metrics to stay in the given lane without incurring scrapes or dents.
The cloud migration example above achieves the same effect. Rather than imposing a single hard deadline (which invariably gets extended to allow for exceptions), the cost allocation mechanism gradually builds up the cost of not migrating so that each team can find their break-even point without hitting the guardrail.
The Other Day at the Railroad Museum
As an engineer, I have a weakness for metaphors pulled from moving machines. I’ve talked about not bursting the boiler in your IT transformation and about grinding the organizational clutch during a gear shift. So, it comes as little surprise that my favorite metaphor for mechanisms comes from a visit to a train museum in Omiya near Tokyo in Japan.
Train wheels, which run on steel tracks, have a large flange on the inside. However, this guardrail is only used for extreme cases and rarely touches the rails. When it does, it makes a sharp screeching and grinding sound.
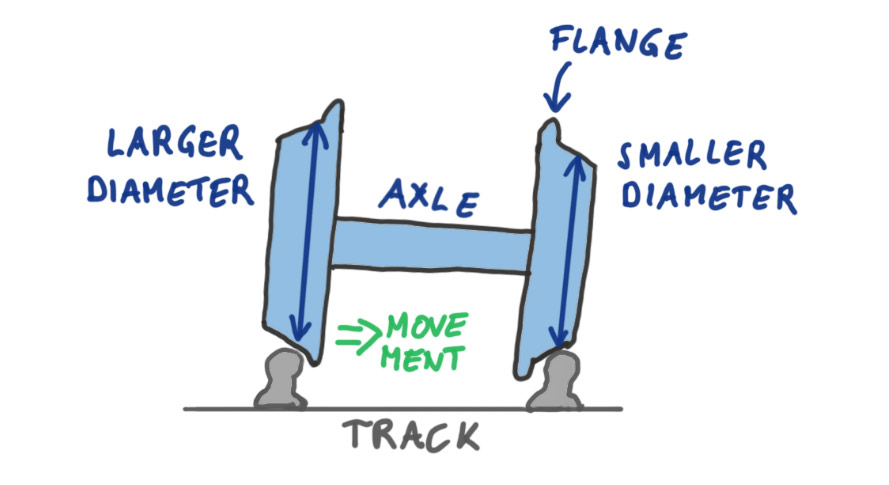
A mechanism keeps train wheels on track
Instead, the train wheels are kept on the center of the track through a mechanism. Each wheel’s running surface is sloped, making the wheel smaller on the outside and larger on the inside of the track. When a train axle veers off to one side (as shown in the sketch), the wheel shape causes the effective wheel diameter on that side to increase. This in turn means that the wheel covers more distance than the opposing wheel, since both are connected by a rigid axle. This mechanism pushes the axle back to the center of the track.
This simple mechanism has kept rail cars on the tracks for over 200 years without hitting the guardrails. So, think about guiding your transformation journey with mechanisms as opposed to just guardrails. You’ll spend less energy and will hear less grinding.
Transforming with Less Grinding
The next time you devise the execution plan for your cloud strategy, consider a day at the railroad museum or hiking up a mountain. The choice of metaphor might depend on your inclination or the weather, but in either case, you’ll remember the mechanisms that gently keep you on track without hitting the rails.