AWS HPC Blog
Reader Question: What is the difference between canceling and terminating a job in AWS Batch?
Reader Question is a recurring blog post series where we answer questions from the HPC community.
This post is written by Angel Pizarro, Principal Developer Advocate for HPC
AWS Batch is a fully managed service for batch computing workloads on the AWS Cloud. It allows defining units of work (a job) and submitting work requests to be completed. AWS Batch automatically provisions compute resources and optimizes the workload distribution based on the quantity and scale of the workloads. At any given point in time some of your requests will be actively running, and some will be scheduled to run when the compute resources become available. Invariably, there will come a time when you will need to cancel some or all of the requests you made after submitting them.
It sometimes surprises our users that there are two different API calls in AWS Batch to cancel a job request, CancelJob and TerminateJob. To understand why there are two possible operations, you first need to understand the lifecycle of an AWS Batch job request. The following diagram is a representation of the possible states and transitions between each that a job can have, beginning when you submit the request.

The AWS Batch Job States documentation has all of the specifics for each state and transition, but I’ve highlighted the important bit in the image above, the RUNNABLE state. A job with a state of RUNNABLE certifies that the job resides in the queue, and has no outstanding dependencies. This means the job is ready to be scheduled to run on top of a compute resource, either an Amazon Elastic Compute Cloud (Amazon EC2) or AWS Fargate. Jobs in this state are started as soon as sufficient resources are available in one of the compute environments that are mapped to the job’s queue. Matching a job to an Amazon EC2 instance compute resource is depicted below.
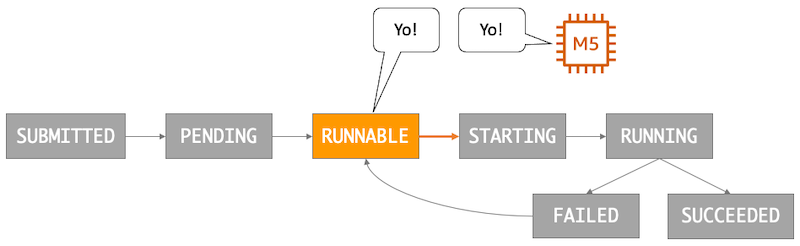
The AWS Batch job scheduler will automatically find a match for the job and swipes right, err, I mean transitions the job to the STARTING state while it is staged onto the compute resource. It will then change to the RUNNING state when the task starts running.
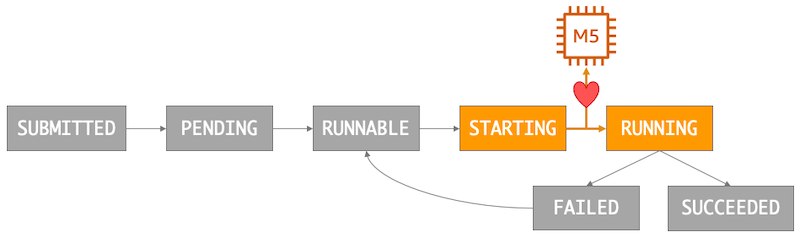
Eventually the job successfully completes its assignment and transitions to SUCCEEDED, or fails and transitions to the FAILED state.
Jobs interrupted
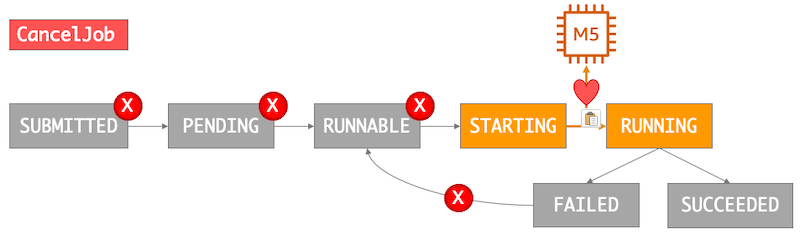
Now suppose you have just got an alert from an Amazon CloudWatch billing alarm that you have spent your monthly threshold, but there are still quite a lot of job requests in the job queue. When you created the alarm, you set a billing threshold that was lower than your actual budget, so you would be able to finish off some analysis that had already started. In this case, you want to let processes currently running complete, and prevent any new processes from starting. The CancelJob API call cancels any job requests that are not yet in the STARTING or RUNNING states. Jobs in those two states are left to finish their work.
Can I get a do-over?
One more thing to consider is the case where you have configured a job with a retry strategy using Automated Job Retries. Jobs that define a retry strategy can transition back to RUNNABLE after they enter the FAILED state, making them eligible to be placed back on some compute resource. Retry strategies are especially useful when using EC2 Spot Instance capacity that can be interrupted before a job completes, and you want that job to try again once capacity becomes available.
When you cancel a job request, most likely you do not want that job to try to run again! As you can see from the previous diagram, CancelJob does the right thing and overrides the retry strategy so that the job is not restarted.
Jobs REALLY interrupted
Now imagine if you did not have the foresight to set a threshold that was lower than your budget and there is no wiggle room to run some final jobs. In this case you must stop all processes, even those that are running, immediately. TerminateJob will cancel all jobs that are waiting on resources, and force shut down all processes that are in the STARTING and RUNNING states, transitioning those jobs to the FAILED state. TerminateJob will also override the retry strategy of the job request so that it does not get re-queued for execution.

Under the hood, the Amazon ECS StopTask API call is used, which sends a SIGTERMvalue to the running container task. If after 30 seconds the container is still running, a SIGKILL signal is sent to forcibly stop the container. If the container handles the SIGTERM value gracefully and exits within 30 seconds from receiving it, no SIGKILL value is sent.
Conclusion
We covered the lifecycle of an AWS Batch job, and how and when you want to cut that lifespan short. CancelJob is used when you want to clear the queue of any waiting jobs or stop a job from restarting if failed. TerminateJob is used when you want to stop all current and future job requests from running.
You can read more about the specifics of job states, retry strategies, and canceling or terminating job requests in the AWS Batch documentation.