AWS for Industries
ETL ingest architecture for asset management based on AWS Lambda
The finance industry is transforming with the creation of business platforms for the buy-side of wholesale finance (institutional managers), providing asset performance, risk, Solvency II compliance, and ESG scores. Such platforms can hold trillions of dollars of managed assets, and therefore mandate a high level of security and control for the exchange of asset information through the platform between asset owners and asset managers.
Ingesting data comprises most of the work for the initial phase of this project. The data is semi-structured through a common schema, but in terms of how the schema is interpreted, there is a wide scope for variation across the data set. The source data originates from hundreds or potentially thousands of unique sources (asset managers and asset owners), is ingested in a number of file formats (.csv, .xls, .xlsx etc), and may follow a number of acceptable industry standard schemas used to represent fund data across the industry. An ingestion process with so many disparate data sources and file formats presents both a challenge to traditional data pipeline architectures and a need for a new approach.
This blog post details a secured data ingestion flow in such a platform. The ingestion flow must validate many business rules—up to hundreds. This requirement calls for a very flexible and adaptive design, which is described later in this post. Also, the ingestion flow must allow for thousands of companies to exchange confidential data on the platform in a very controlled manner.
The desired output of the pipeline is to:
- Produce a dataset that has been checked against a set of business rules and functional data quality checks to ensure the file contains relevant fund data information
- Transform where necessary into a common schema format
- Perform functional checks against the data set to ascertain the quality of the data
Pipeline requirements
Ingested asset files are typically small in size, generally less than 10MB with a large majority of files being 0.5MB in size. These small files are uploaded on demand by each of the asset owners. Files are processed immediately after upload, and the output result arrives in seconds.
The pipeline should be capable of handling a large batch of files uploaded via API or SFTP, though this is not its primary role. For individual asset managers, the focus is on the “real-time processing experience.”
Security and provenance of the data are the most important requirements for the pipeline. Each asset owner or asset manager (referred to as institution) wants to have its own encryption key, so all assets must be encrypted at rest. No institution should be able to access the data of any other institution without an explicit grant, and access should be able to be revoked at any time. The proposed design must also scale in a cost-effective manner to adapt to the variability in uploaded data volume over the month, and in monthly and quarterly reporting periods for each institution.
Another requirement is a robust operational model. The ability to visualize the pipeline steps and develop the individual code blocks, as opposed to a “monolithic application” deployed as a container, for example, provides the required visibility into the ingestion process for the operation team.
Pipeline architecture
The AWS Professional Services (ProServe) team worked with the customer to progress two architectures through proof of concept (PoC) to compare and contrast the technologies and determine the best fit based on the criteria.
AWS Lambda
The ETL (extract, transform, and load) pipeline was created using AWS Lambda functions based on Python/Pandas. The pipeline was designed to execute using a series of Amazon S3 buckets and to return the results, logs, and errors to Amazon API Gateway.
Lambda cold starts in seconds. Billing is based on duration (per GB-seconds) and the number of requests provided in the solution, with a dedicated pipeline per file ingested. This serverless model proved to be an excellent fit for rapidly processing many small files in a performant and scalable way with predictable, low cost per file.
Then, AWS Step Functions provides a robust orchestration layer to the pipeline and provides the visualization that the customer requested.
Ingestion control and workflow orchestration with AWS Step Functions state machine
AWS Step Functions was chosen to orchestrate the pipeline execution and integrate the pipeline with Amazon Cognito, AWS Key Management Service (KMS), S3, and API Gateway.
AWS Step Functions provides the orchestration layer for the ETL pipeline Lambda functions. The state machine handles the interactions between component Lambda functions and their associated authentication tokens, encryption keys, and data stored in S3. It also handles the flow of the data through the chain of S3 buckets and the pipelines call-back functionality through API Gateway. The state machine is responsible for executing post-processing tasks such as cleaning up temporary assets (auth tokens and keys), initiating file copies to authorised institutions, and triggering SFTP upload of the processed files.
 ETL orchestration workflow diagram
ETL orchestration workflow diagram
Orchestration
AWS Step Functions provides this workflow with following capabilities:
- Visualize the workflow logic, easily edit the logic, and re-use application components
- Visually identify steps that have failed and locate the associated error log
- Provide task-based application logic with individual task performed based on the state (success/fail, pass, wait, or parallel execution), allowing for complex logic to be easily constructed and modified
- Integrate with Lambdas and other AWS services
The state machine
Shown in yellow in the accompanying diagram, the state machine controls the flow of the ingested data through the pipeline; the resultant state of each function determines how the data progresses. It includes audit and error logging, progression to the next step or termination of pipeline, and post-processing tasks such as:
- Triggering Lambda functions to perform clean-up tasks
- Triggering SFTP upload of the processed data
- Triggering call-back functions to return data via API Gateway endpoints to the backend application
- Triggering CleanUp to remove the ID token used for authentication in the workflow (more details on that in the security section below)
Asset ingestion based on lightweight and scalable Lambda ETL
The proceeding flow diagram illustrates the steps and decisions contained within the ETL pipeline. These steps are executed by a sequence of Lambda functions triggered by the upload of new data. For each file uploaded, a dedicated pipeline is triggered to process the data. On completion, the pipeline is destroyed. Where multiple files are uploaded, multiple pipelines are triggered, which execute in parallel.
 Process ETL Flow
Process ETL Flow
In addition to Lambda and AWS Step Functions, the solution leverages additional AWS services in the following ways:
Amazon S3 buckets provide durable storage of assets at each stage of the pipeline. With the requirement for all ingested and processed data to be retained, including data in the interim buckets representing the stages of the ETL, Amazon S3 provides a cost effective, secure, and durable storage solution. Amazon S3 lifecycle policies enable the platform to transition processed data to more cost effective storage tiers automatically, further reducing costs of maintaining the entire dataset over long timescales required for compliance with data retention policies of the financial services industry.
AWS Key Management Service CMK (Customer Managed Keys) provides encryption per institution for objects stored in Amazon S3.
Amazon API Gateway endpoints enable the pipeline to feedback status, error, audit, and extracted data to the collection application and front-end UI.
Amazon Cognito and AWS Identity and Access Management (IAM) enable user authentication to the web UI, execute Lambda functions in the context of the authenticated users, and assume the IAM Roles needed to interact with the encrypted data.
AWS Systems Manager Parameter Store provides the ability to securely pass sensitive data between the state machine and Lambda functions without exposing sensitive information through log files or the console.
These technologies were combined in the architecture to meet the key requirement that once data is stored in Amazon S3, it cannot be decrypted unless the institution that uploaded the data is logged in, and encryption keys cannot be retrieved by the parent application (no super users). This requirement exists to give users of the platform (fund asset managers and asset owners) confidence that the confidential data they upload to the platform cannot be accessed by anyone without their explicit permission.
Authentication and authorization
To achieve the security requirements described earlier, Amazon Cognito user pools are used to authenticate the end users, and IAM is leveraged to authorize AWS actions, such as access to S3 and using encryption keys. The linkage between authentication and authorization is achieved by using Amazon Cognito identity pools.
For each institution, a dedicated AWS KMS customer master key (CMK) is created to encrypt the institution’s data in S3. Additionally, a dedicated IAM role is created for each institution, which is the only entity in the environment allowed to use the institution’s CMK for decryption. This IAM role is allowed to access the institution’s S3 bucket to save and retrieve the institution’s data. This leads to strong isolation of institution’s data, which only the institution’s IAM role has access to.
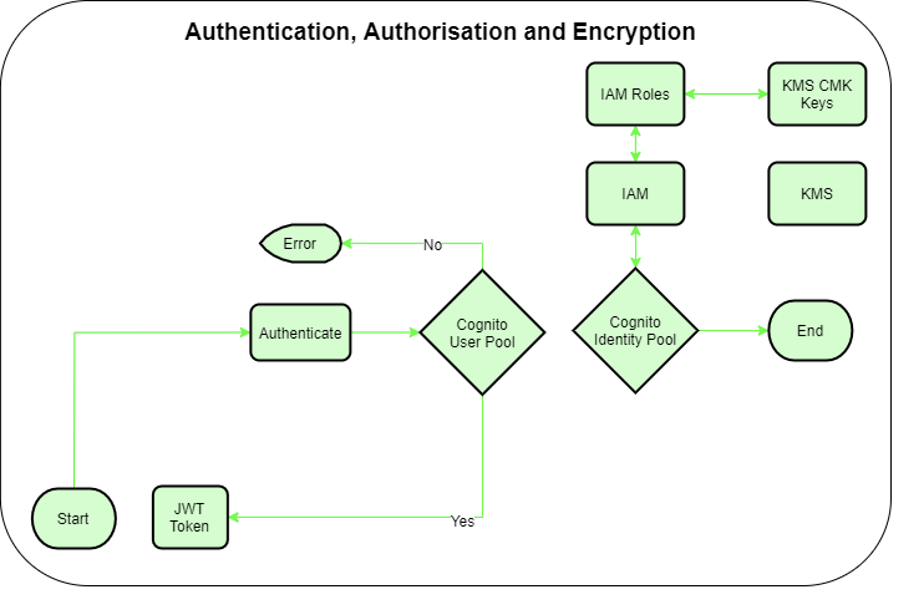 Authentication and authorisation flow
Authentication and authorisation flow
To connect the institution’s Amazon Cognito user with the dedicated IAM role created for the institution, Amazon Cognito identity pools are used. By authenticating against Amazon Cognito’s user pool, the user who is a member of the institution receives a JSON web token (JWT) containing an ID token. The Amazon Cognito identity pool allows the end user to use the ID token to assume the institution’s IAM role and access the institution’s CMK, along with the institution’s data in S3. For more information about the ID token issued by Amazon Cognito, see Using Tokens with User Pools.
 Use ID token to decrypt with institution’s CMK
Use ID token to decrypt with institution’s CMK
To allow the Lambda functions in the state machine to use the institution’s IAM role to access the CMK so it can actually decrypt the data and perform its computation on it, the ID token needs to be passed to the state machine. However, each parameter passed directly to the state machine during invocation is saved and shown in cleartext in the execution details of AWS Step Functions. This is not acceptable because the ID token is equivalent to the credentials of the institution’s IAM role. Thus, a secure mechanism to pass the ID token to the state machine is necessary. Using the Systems Manager Parameter Store to temporarily save the ID token as a SecureString allows a safe way to share the ID token with the state machine.
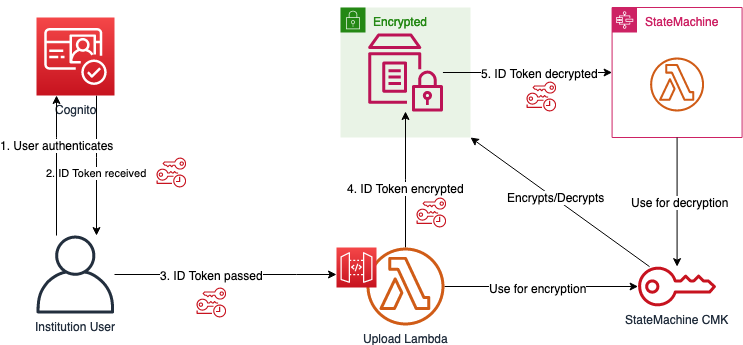 ID token flow
ID token flow
The Parameter Store is encrypted with a dedicated state machine CMK, which can only be used by the Lambdas of the state machine for decryption. This state machine CMK is different from the institution’s CMK; its only purpose is to provide an encrypted channel between the Upload Lambda, which handles the ingest request of the institution and the state machine.
After the state machine finishes its operation, the ID token is erased from the Parameter Store. This makes the ID token only available to the state machine during the minutes in which the state machine needs to perform its task.
The following Python function is used by the Lambda functions to obtain the temporary credentials by providing the ID token created by Amazon Cognito. The ID token is provided by the user during file ingestion. The code depends on the following library (found at PyJWT 2.0.1):
Exchanging data
CMK key policies are defined to ensure that only necessary actors have access to the key. To allow an institution B to share its data with another institution A, institution B can use institution A’s CMK to encrypt the file to be shared. The following key policy is defined for institution A’s CMK to allow other institutions to share files and at the same time allows only institution A to use the key for decryption:
Security pattern embodied into DevOps pipeline
Taking into account the security aspect at the earliest stage into the development phase, DevSecOps best practices are followed. Specifically, three new pillars dedicated to evaluate the security practice into the DevOps assessment have been implemented:
- Security “IN” the pipeline
- Security “OF” the pipeline
- “ENFORCEMENT” of the pipeline
The Data Ingestion Pipeline uses S3, Lambda, Step Functions and KMS as main services. The release process uses git branch staging, including feature branch management for the developers to test and validate their own work, and for the DevOps team to perform private demos and functional tests.
All components are deployed by an Infrastructure as Code process using AWS CloudFormation. The Lambda functions code are isolated in a separate code-based file. This practice helps to improve unit and static code analysis testing. The deployment pipeline packages the stack on the fly to be deployed straight away.
Testing, with security specific controls, is part of the pipeline and stage transition. The development stage includes automated testing covering unit and static code analysis test. The private demo stage, which incorporates integration testing, includes automated functional integration and OWASP testing.
 Stage environment flow
Stage environment flow
Following DevOps best practices of AWS Professional Services, the builders team executed a plan to increase the maturity of the DevSecOps process by introducing automated security testing, protection, and controls of the pipelines. The overall rating of the five domains of DevOps increased. All domains covered by the improvement plan reached the level 3 of maturity (L3).
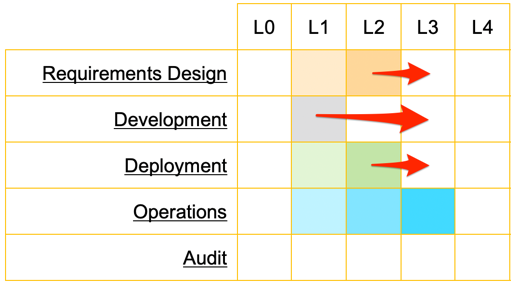 Project maturity evolution
Project maturity evolution
The “Operation” domaine did not required improvement because that it was under the control of the client’s operation team , which was out of the scope of the project and already reaching the level 3 of maturity (L3).
Improvements are still being made mainly over KPIs and introduction of the constant audit of the solution, but this is not part of the initial scope of the assessment and improvement plan.
Conclusion
The proposed architecture is now in operation for one project, and several more are considering adoption.
This post showed you how to build a secured ETL pipeline adhering to many business requirements and ingesting small files in real-time. This pattern is a complement to the more traditional batch pipeline and tools of data lakes on AWS in the Financial Services industry.
To learn more about the security of this project, see How financial institutions can approve AWS services for highly confidential data on the AWS Security Blog.
If you have questions or feedback, leave a message in the comments or, contact sales directly.