Integration & Automation
A tale from the trenches: The CloudBees Core on AWS Quick Start
This post is by David B. Schott, Senior Business Development Engineer at CloudBees, Inc.
It’s December 2018, and holiday time off is only days away. My new boss, the VP of Business Development, calls to discuss upcoming projects for 2019. Among these is an Amazon Web Services (AWS) Quick Start that integrates with Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances. Amazon created an economy around spare compute capacity that allows customers to save tons of money, making it a perfect integration candidate for CloudBees’ flagship CI/CD product: CloudBees CI (Core).
At the time, I had zero experience with AWS CloudFormation, but I knew that it’s the common language for AWS Quick Starts. My deadline was February 25, meaning I had 8 weeks to publicly launch materials in tandem with AWS Summit London, which CloudBees was sponsoring. I felt comfortable with my ability to learn AWS CloudFormation and get CloudBees Core deployed one way or another, but EC2 Spot integration was a mystery. What are the different ways in which CloudBees Core and EC2 Spot Instances fit together?
YouTube to the rescue! I watched a webinar that covered the Amazon EC2 Spot Fleet Plugin. Architecturally, the plugin works very differently from what I had in mind: It launches Spot Instances and runs builds on them, but those instances are ordinary virtual machines—not Kubernetes worker nodes and not members of the Kubernetes cluster that CloudBees Core runs on. CloudBees Core uses containers (pods) to run builds, and although the plugin would “work” and check the box for an integration with Spot Instances, I continued searching for a Kubernetes-native solution.
Then, in a blog post by Jeff Barr on EC2 Auto Scaling Groups with Multiple Instance Types & Purchase Options, I found the key to an integration between CloudBees Core and EC2 Spot Instances! The new feature described in the blog post integrates EC2 Spot Instances with Auto Scaling. Auto Scaling is commonly used to create “pools” of EC2 instances that can scale up or down, and can automatically recover when an instance within the pool is terminated or becomes unhealthy (even if the pool contains only one instance). The new feature provides the capability to diversify the pool with multiple instance types, and to allocate a percentage of On-Demand Instances and Spot Instances. This integration is hugely beneficial for EC2 Spot Instances, because if a certain Spot Instance type is unavailable, other instance types are automatically requested to maintain the desired capacity—all from a single Auto Scaling group.
Quick Start architecture considerations
CloudBees Core has three main components: Operations Center, Managed Masters, and Agents. When CloudBees Core is installed on Kubernetes, the only component that runs by default is Operations Center. The other two are created dynamically. Administrators use Operations Center to provision Managed Masters (i.e., Jenkins master servers) for each development team, and Agents are created on the fly by the Kubernetes plugin and pod templates. Refer to the following feature overview diagram for more details.

Figure 1: CloudBees Core logical architecture
Operations Center and Managed Masters are meant to run 24 hours a day, 7 days a week, so it’s not ideal to run them on Spot Instances. Agents, on the other hand are transient, short-lived, and easily restarted after a failure (e.g., when a Spot Instance is reclaimed). A separate partition is necessary in the Kubernetes cluster to isolate agents to a separate pool of Spot-only worker nodes, via the Multi-Instance Auto Scaling group feature mentioned previously. I had the following architecture in mind, which hadn’t been built yet.
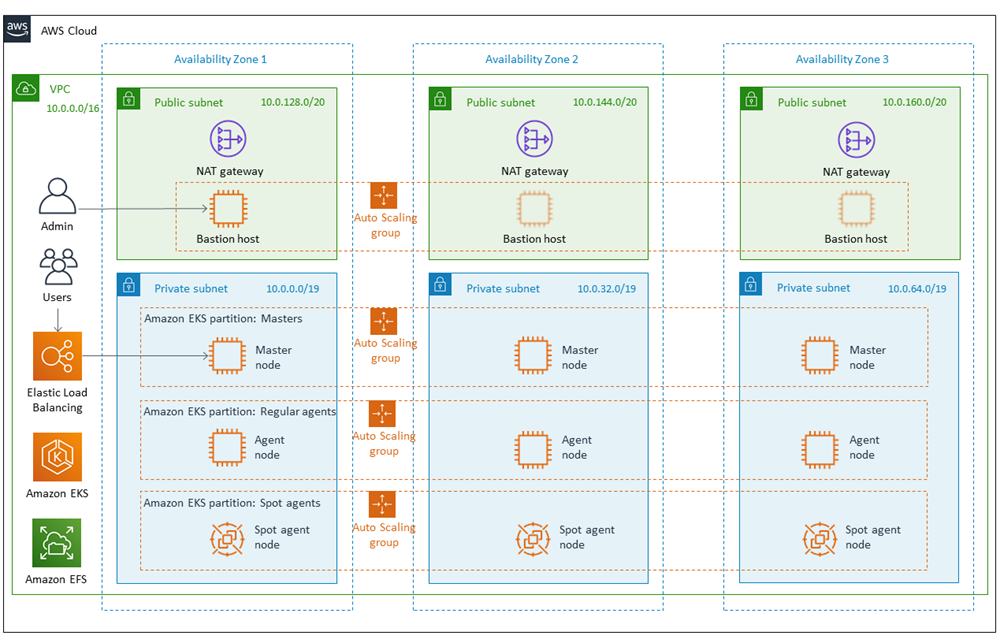
Figure 2: CloudBees Core on AWS Quick Start architecture
AWS Quick Starts are, according to the website, “automated, gold-standard deployments in the AWS cloud.” The “gold-standard” part made me nervous, because I still had no idea how to architect a Quick Start for an app that runs on Kubernetes, much less one that is production-ready, resilient, upgradeable, etc. I did know that I would use Amazon Elastic Kubernetes Service (Amazon EKS) as the plug-and-play service for running Kubernetes, but there were no examples of this in the aws-quickstart organization on GitHub.
The landscape of existing tools
Have you ever been in a “tool debate” with engineers or even non-engineers? This type of discussion can get pretty heated, which is exactly what happened. My research indicated that it’s impossible to create a full-fledged Amazon EKS cluster with AWS CloudFormation alone, so hearing things like “just use CloudFormation” further fueled my frustration. Creating a functioning Kubernetes cluster is more than just laying down the infrastructure, which AWS CloudFormation does extremely well. We also need to interact with the Kubernetes API—for example, to apply the aws-auth ConfigMap, which (among other things) allows worker nodes to join the cluster. After all, no Kubernetes cluster is complete without worker nodes.
Because Quick Starts are fully automated via AWS CloudFormation, which doesn’t have a native construct for interacting with the Kubernetes API, I was at a loss. The deadline was only weeks away, and creating an Amazon EKS cluster with AWS CloudFormation seemed like an insurmountable challenge. Like any developer, I threw my arms up and looked at other options. I experimented with AWS Cloud Development Kit (CDK) and eksctl from Weaveworks. The former allows you to create AWS infrastructure in the programming language you’re most comfortable with (Java, in my case). The latter is specific to Amazon EKS, and it reduces the process of creating an EKS cluster to just one line of code.
One line of code. No harm in trying, right? I installed eksctl, and minutes later, like magic, I had a fully operational EKS cluster, complete with aws-auth ConfigMap and a single pool of worker nodes. I was impressed, and with my new power to create and destroy EKS clusters quickly and easily, I carried on. I created an additional node group and tested a Jenkins Pipeline to ensure that the agent pod could be configured to run in the newly created node group. I learned, or proved to myself, that a Kubernetes cluster can be split into partitions using labels and taints, and that CloudBees Core natively integrates with that kind of architecture.
The clock was still ticking and I hadn’t started coding the Quick Start, but I knew exactly what I wanted to build. I could have focused on CloudFormation, but I opted instead to continue experimenting with eksctl. I was able to create additional node groups, but the instances were associated with a launch configuration and not a launch template, which is required for Auto Scaling groups with multiple instance types and purchase options (refer to Jeff Barr’s blog post). I found an issue on GitHub that tracks this as a feature request and gave it a thumbs up. Then I discovered a feature from Amazon to convert a launch configuration to a launch template, resulting in a Spot-only, multiple-instance partition in my EKS cluster. Everything worked as expected, and the target architecture was directly in front of me!
Now, the hard part. How was I going to translate everything that eksctl did (as well as a few steps performed manually) into an AWS CloudFormation-based Quick Start?
I had already read the Quick Start Contributor’s Guide and Builder’s Guide, so I knew that there are three main items to deliver: code (CloudFormation templates), an architecture diagram, and a deployment guide. The latter two would fall into place as the code came together, but the CloudFormation code remained stalled in the aforementioned tool debate. The Builder’s Guide documentation on submodules and modularity was eye-opening. AWS has pre-built templates based on well-known best practices for a virtual private cloud (VPC) and a bastion host that are easily incorporated as Git submodules into a Quick Start.
What about AWS CloudFormation and Amazon EKS? There’s a construct that creates an EKS control plane, but it isn’t enough to create “the whole enchilada.” Remember that we have to hit the Kubernetes API at certain points while creating the cluster. My code base was starting to come together, in that the VPC and bastion host submodules were up and running. I knew that I could run a bootstrap script on the bastion host to create an EKS cluster (via aws eks or eksctl and other tools), but I also knew that doing so is an architectural anti-pattern: Everything that happens in that bootstrap script is done “out of band” with AWS CloudFormation. Even more challenging, Quick Starts require new VPC and existing VPC deployment options, and I’m fairly certain that it’s impossible to meet that requirement with the bastion host and bootstrap script pattern.
Enter the AWS PSAs
Help was quickly needed if I was going to finish on time. At this point, I was in regular meetings with the EC2 Spot team discussing the integration plans, though I still didn’t know where to go for help with the Quick Start. A colleague had previously forwarded an email with technical resources from Amazon, so I reached out. Partner Solutions Architect (PSA) Jay Yeras invited me to a meeting, and over the next 2 weeks, we discussed ways to architect the Quick Start, including crazy ideas like invoking a CDK app from AWS Lambda. The consensus was that in order to keep all installation steps in band with AWS CloudFormation, Lambda was the tool of choice. AWS CloudFormation can invoke a Lambda function, and a well-written Lambda function can accomplish just about anything while also reporting back to AWS CloudFormation. For example, if a CloudFormation stack invokes a Lambda function that creates a resource, then deleting the CloudFormation stack should also delete the resource. That’s partly what it means to be “in band” with AWS CloudFormation.
I was doomed. AWS CloudFormation was insufficient; I’d have to learn Lambda too? Jay Yeras to the rescue. He caught wind that his colleague, Jay McConnell, was working on a private (now public) framework for building Amazon EKS-based Quick Starts. I was added as a collaborator to the GitHub repository, and I studied the code for a while. Jay McConnell’s framework removed all ambiguity from the mental equation and solved my problems (it uses Lambda under the hood).
Roughly 4 weeks left until the deadline, I’m heads down writing code as quickly as I can. Jay Yeras and Jay McConnell (a.k.a. “the Jays”) invited me to a private chat room on Amazon Chime and did their best to answer my questions—even the inquiries that may have appeared bothersome, like “why is taskcat hanging while uploading to S3?” Turned out that the Lambda .zip files in the EKS framework are ~400 MB. The Jays shared an undocumented option in taskcat to use the same S3 bucket every time the Quick Start is deployed, shipping only the deltas. It saved me a great deal of time, and I’m grateful for their help.
I worked hard and submitted all launch materials 2 weeks ahead of the deadline to give Amazon enough time to review—which they did, in great detail. Meanwhile, I met with the Jays remotely to help them learn more about CloudBees Core. They quizzed me on data storage, backup and recovery, and the resiliency of the product I had built in general. CloudBees Core Operations Center and Managed Masters run as a StatefulSet in Kubernetes, meaning they require persistent storage. I had implemented only Amazon Elastic Block Store (Amazon EBS), and the Jays accurately pointed out that in the event of an Availability Zone outage, a CloudBees Core Quick Start user would be in serious trouble unless they have backups for all their Amazon EBS volumes.
The solution then became to either add Amazon Elastic File System (Amazon EFS) as an option to the Quick Start, or continue with Amazon EBS but provide a solution for built-in backups. CloudBees Core offers a Backup Plugin, but it’s non-trivial to pre-configure it into the Quick Start. Other options like AWS Backup and AWS Ops Automator were explored, but not integrated. Despite the higher cost of Amazon EFS compared to Amazon EBS, it solves our problem: EFS volumes are accessible from every Availability Zone, whereas EBS volumes are single zone only. If there’s a zone outage while using EFS, Operations Center and Managed Master pods will move to a new zone (via Kubernetes health checking and scheduling) and continue to access their file system in the new zone after a brief period of downtime. The same scenario, with EBS, requires a manual backup and restore procedure.
We weren’t able to launch the Quick Start on the originally planned launch date. Major design decisions like this one warrant a review by the much larger Product and Engineering teams, and this is one of several factors that postponed the launch. Jay Yeras’s decision not to accept the Quick Start led to a sequence of events that likely wouldn’t have happened otherwise. Subject matter experts from Product and Engineering agreed that the simplest and most effective solution was to implement EFS with the new Provisioned Throughput option to guarantee EBS-like performance, and I made it so.
It took more time to work through internal processes than it did to build the first iteration of the Quick Start, but the relationships that were made continue to be fruitful to this day. We had ample time to raise awareness, improve documentation, create demo videos, and present at one of our internal company-wide webinars. CloudBees became aware of what the CloudBees Core on AWS Quick Start is—its features and its importance. Bugs were fixed, and AWS upgraded Amazon EKS from version 1.11 to 1.12 along the way, which resolves a known issue with EBS volumes on small clusters. We created a much better product thanks to Jay Yeras’s technical scrutiny.
Conclusion
If you’ve read this far, I hope you learned something along the way. This was a time of my life that I’ll never forget. I still don’t claim to be an expert on AWS CloudFormation, but with guidance from Amazon, I learned the ropes through documentation and experts who could answer my questions. This experience reinforces the nature of a true partnership—creating a joint solution that’s mutually beneficial, and helping each other out along the way. It’s been a pleasure working with you, Amazon.