Artificial Intelligence
Category: Amazon Textract

Augment search with metadata by chaining Amazon Textract, Amazon Comprehend, and Amazon Kendra
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines enterprise search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization. With Amazon Kendra, you can stop searching […]

Intelligently split multi-form document packages with Amazon Textract and Amazon Comprehend
Many organizations spanning different sizes and industry verticals still rely on large volumes of documents to run their day-to-day operations. To solve this business challenge, customers are using intelligent document processing services from AWS such as Amazon Textract and Amazon Comprehend to help with extraction and process automation. Before you can extract text, key-value pairs, […]
Bring structure to diverse documents with Amazon Textract and transformer-based models on Amazon SageMaker
From application forms, to identity documents, recent utility bills, and bank statements, many business processes today still rely on exchanging and analyzing human-readable documents—particularly in industries like financial services and law. In this post, we show how you can use Amazon SageMaker, an end-to-end platform for machine learning (ML), to automate especially challenging document analysis […]
AWS is redefining how companies process documents in a digital world
Think about the last time you opened a bank account, applied for insurance, or refinanced your home. It was probably done on paper. The number of documents in a mortgage packet alone is over 100 pages long. What do you do with all that paper? For many companies across a variety of industries, including financial […]

Announcing specialized support for extracting data from invoices and receipts using Amazon Textract
Receipts and invoices are documents that are critical to small and medium businesses (SMBs), startups, and enterprises for managing their accounts payable processes. These types of documents are difficult to process at scale because they follow no set design rules, yet any individual customer encounters thousands of distinct types of these documents. In this post, […]
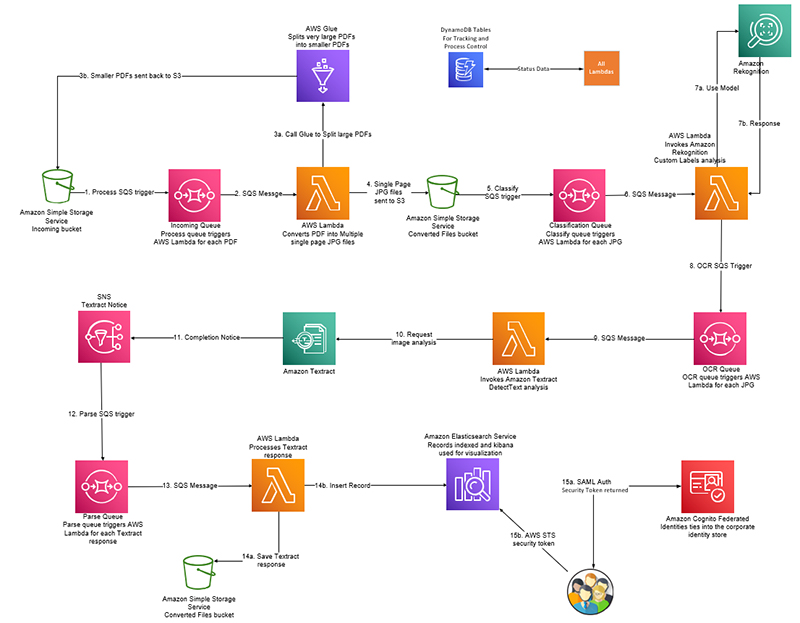
TC Energy builds an intelligent document processing workflow to process over 20 million images with Amazon AI
This is a guest post authored by Paul Ngo, US Gas Technical and Operational Services Data Team Lead at TC Energy. TC Energy operates a network of pipelines, including 57,900 miles of natural gas and 3,000 miles of oil and liquid pipelines, throughout North America. TC Energy enables a stable network of natural gas and […]

Improve newspaper digitalization efficacy with a generic document segmentation tool using Amazon Textract
We are living in a digital age. Information that used to be spread by printouts is disseminated at unforeseen speeds through digital formats. In parallel to the inventions of new types of media, an increasing number of archives and libraries are trying to create digital repositories with new technologies. Digitization allows for preservation by creating […]

Segment paragraphs and detect insights with Amazon Textract and Amazon Comprehend
Many companies extract data from scanned documents containing tables and forms, such as PDFs. Some examples are audit documents, tax documents, whitepapers, or customer review documents. For customer reviews, you might be extracting text such as product reviews, movie reviews, or feedback. Further understanding of the individual and overall sentiment of the user base from […]
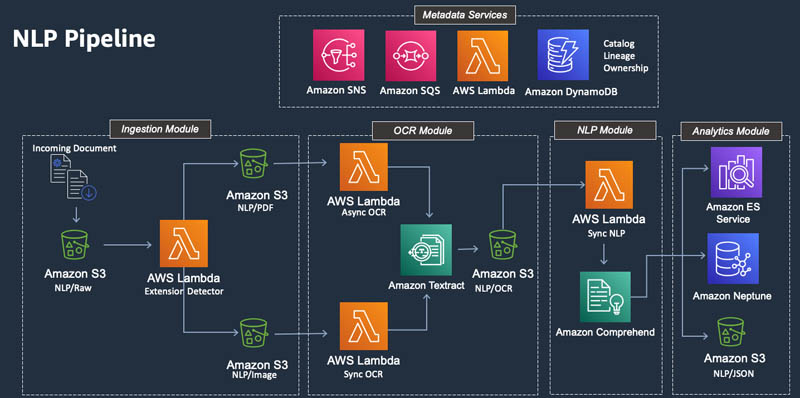
Intelligent governance of document processing pipelines for regulated industries
Processing large documents like PDFs and static images is a cornerstone of today’s highly regulated industries. From healthcare information like doctor-patient visits and bills of health, to financial documents like loan applications, tax filings, research reports, and regulatory filings, these documents are integral to how these industries conduct business. The mechanisms by which these documents […]

PDF document pre-processing with Amazon Textract: Visuals detection and removal
Amazon Textract is a fully managed machine learning (ML) service that automatically extracts printed text, handwriting, and other data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Amazon Textract can detect text in a variety of documents, including financial reports, medical records, […]