Artificial Intelligence
Process documents containing handwritten tabular content using Amazon Textract and Amazon A2I
Even in this digital age where more and more companies are moving to the cloud and using machine learning (ML) or technology to improve business processes, we still see a vast number of companies reach out and ask about processing documents, especially documents with handwriting. We see employment forms, time cards, and financial applications with tables and forms that contain handwriting in addition to printed information. To complicate things, each document can be in various formats, and each institution within any given industry may have several different formats. Organizations are looking for a simple solution that can process complex documents with varying formats, including tables, forms, and tabular data.
Extracting data from these documents, especially when you have a combination of printed and handwritten text, is error-prone, time-consuming, expensive, and not scalable. Text embedded in tables and forms adds to the extraction and processing complexity. Amazon Textract is an AWS AI service that automatically extracts printed text, handwriting, and other data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables.
After the data is extracted, the postprocessing step in a document management workflow involves reviewing the entries and making changes as required by downstream processing applications. Amazon Augmented AI (Amazon A2I) makes it easy to configure a human review into your ML workflow. This allows you to automatically have a human step to review your ML pipeline if the results fall below a specified confidence threshold, set up review and auditing workflows, and modify the prediction results as needed.
In this post, we show how you can use the Amazon Textract Handwritten feature to extract tabular data from documents and have a human review loop using the Amazon A2I custom task type to make sure that the predictions are highly accurate. We store the results in Amazon DynamoDB, which is a key-value and document database that delivers single-digit millisecond performance at any scale, making the data available for downstream processing.
We walk you through the following steps using a Jupyter notebook:
- Use Amazon Textract to retrieve tabular data from the document and inspect the response.
- Set up an Amazon A2I human loop to review and modify the Amazon Textract response.
- Evaluating the Amazon A2I response and storing it in DynamoDB for downstream processing.
Prerequisites
Before getting started, let’s configure the walkthrough Jupyter notebook using an AWS CloudFormation template and then create an Amazon A2I private workforce, which is needed in the notebook to set up the custom Amazon A2I workflow.
Setting up the Jupyter notebook
We deploy a CloudFormation template that performs much of the initial setup work for you, such as creating an AWS Identity and Access Management (IAM) role for Amazon SageMaker, creating a SageMaker notebook instance, and cloning the GitHub repo into the notebook instance.
- Choose Launch Stack to configure the notebook in the US East (N. Virginia) Region:
![]()
- Don’t make any changes to stack name or parameters.
- In the Capabilities section, select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create stack.

The following screenshot of the stack details page shows the status of the stack as CREATE_IN_PROGRESS. It can take up to 20 minutes for the status to change to CREATE_COMPLETE.
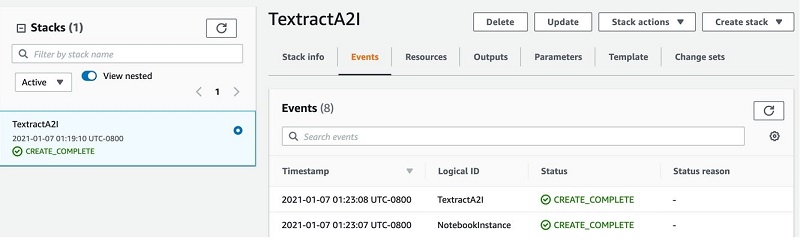
- On the SageMaker console, choose Notebook Instances.
- Choose Open Jupyter for the
TextractA2INotebooknotebook you created. - Open
textract-hand-written-a2i-forms.ipynband follow along there.
Setting up an Amazon A2I private workforce
For this post, you create a private work team and add only one user (you) to it. For instructions, see Create a Private Workforce (Amazon SageMaker Console). When the user (you) accepts the invitation, you have to add yourself to the workforce. For instructions, see the Add a Worker to a Work Team section in Manage a Workforce (Amazon SageMaker Console).
After you create a labeling workforce, copy the workforce ARN and enter it in the notebook cell to set up a private review workforce:
In the following sections, we walk you through the steps to use this notebook.
Retrieving tabular data from the document and inspecting the response
In this section, we go through the following steps using the walkthrough notebook:
- Review the sample data, which has both printed and handwritten content.
- Set up the helper functions to parse the Amazon Textract response.
- Inspect and analyze the Amazon Textract response.
Reviewing the sample data
Review the sample data by running the following notebook cell:
We use the following sample document, which has both printed and handwritten content in tables.

Use the Amazon Textract Parser Library to process the response
We will now import the Amazon Textract Response Parser library to parse and extract what we need from Amazon Textract’s response. There are two main functions here. One, we will extract the form data (key-value pairs) part of the header section of the document. Two, we will parse the table and cells to create a csv file containing the tabular data. In this notebook, we will use Amazon Textract’s Sync API for document extraction, AnalyzeDocument. This accepts image files (png or jpeg) as an input.
You can use the Amazon Textract Response Parser library to easily parse JSON returned by Amazon Textract. The library parses JSON and provides programming language specific constructs to work with different parts of the document. For more details, please refer to the Amazon Textract Parser Library
Now that we have the contents we need from the document image, let’s create a csv file to store it and also use it for setting up the Amazon A2I human loop for review and modification as needed.
Alternatively, if you would like to modify this notebook to use a PDF file or for batch processing of documents, use the StartDocumentAnalysis API. StartDocumentAnalysis returns a job identifier (JobId) that you use to get the results of the operation. When text analysis is finished, Amazon Textract publishes a completion status to the Amazon Simple Notification Service (Amazon SNS) topic that you specify in NotificationChannel. To get the results of the text analysis operation, first check that the status value published to the Amazon SNS topic is SUCCEEDED. If so, call GetDocumentAnalysis, and pass the job identifier (JobId) from the initial call to StartDocumentAnalysis.
Inspecting and analyzing the Amazon Textract response
We now load the form line items into a Pandas DataFrame and clean it up to ensure we have the relevant columns and rows that downstream applications need. We then send it to Amazon A2I for human review.
Run the following notebook cell to inspect and analyze the key-value data from the Amazon Textract response:
The following screenshot shows our output.

Run the following notebook cell to inspect and analyze the tabular data from the Amazon Textract response:
The following screenshot shows our output.
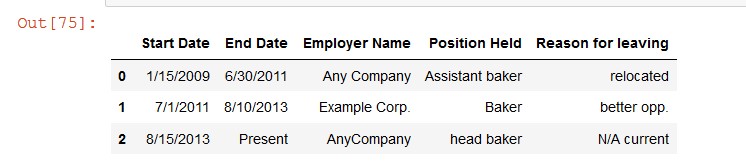
We can see that Amazon Textract detected both printed and handwritten content from the tabular data.
Setting up an Amazon A2I human loop
Amazon A2I supports two built-in task types: Amazon Textract key-value pair extraction and Amazon Rekognition image moderation, and a custom task type that you can use to integrate a human review loop into any ML workflow. You can use a custom task type to integrate Amazon A2I with other AWS services like Amazon Comprehend, Amazon Transcribe, and Amazon Translate, as well as your own custom ML workflows. To learn more, see Use Cases and Examples using Amazon A2I.
In this section, we show how to use the Amazon A2I custom task type to integrate with Amazon Textract tables and key-value pairs through the walkthrough notebook for low-confidence detection scores from Amazon Textract responses. It includes the following steps:
- Create a human task UI.
- Create a workflow definition.
- Send predictions to Amazon A2I human loops.
- Sign in to the worker portal and annotate or verify the Amazon Textract results.
Creating a human task UI
You can create a task UI for your workers by creating a worker task template. A worker task template is an HTML file that you use to display your input data and instructions to help workers complete your task. If you’re creating a human review workflow for a custom task type, you must create a custom worker task template using HTML code. For more information, see Create Custom Worker Task Template.
For this post, we created a custom UI HTML template to render Amazon Textract tables and key-value pairs in the notebook. You can find the template tables-keyvalue-sample.liquid.html in our GitHub repo and customize it for your specific document use case.
This template is used whenever a human loop is required. We have over 70 pre-built UIs available on GitHub. Optionally, you can create this workflow definition on the Amazon A2I console. For instructions, see Create a Human Review Workflow.
After you create this custom template using HTML, you must use this template to generate an Amazon A2I human task UI Amazon Resource Name (ARN). This ARN has the following format: arn:aws:sagemaker:<aws-region>:<aws-account-number>:human-task-ui/<template-name>. This ARN is associated with a worker task template resource that you can use in one or more human review workflows (flow definitions). Generate a human task UI ARN using a worker task template by using the CreateHumanTaskUi API operation by running the following notebook cell:
The preceding code gives you an ARN as output, which we use in setting up flow definitions in the next step:
Creating the workflow definition
In this section, we create a flow definition. Flow definitions allow us to specify the following:
- The workforce that your tasks are sent to
- The instructions that your workforce receives (worker task template)
- Where your output data is stored
For this post, we use the API in the following code:
Optionally, you can create this workflow definition on the Amazon A2I console. For instructions, see Create a Human Review Workflow.
Sending predictions to Amazon A2I human loops
We create an item list from the Pandas DataFrame where we have the Amazon Textract output saved. Run the following notebook cell to create a list of items to be sent for review:
You get an output of all the rows and columns received from Amazon Textract:
Run the following notebook cell to get a list of key-value pairs:
Run the following code to create a JSON response for the Amazon A2I loop by combining the key-value and table list from the preceding cells:
Start the human loop by running the following notebook cell:
Check the status of human loop with the following code:
You get the following output, which shows the status of the human loop and the output destination S3 bucket:
Annotating the results via the worker portal
Run the steps in the notebook to check the status of the human loop. You can use the accompanying SageMaker Jupyter notebook to follow the steps in this post.
- Run the following notebook cell to get a login link to navigate to the private workforce portal:
- Choose the login link to the private worker portal.
- Select the human review job.
- Choose Start working.
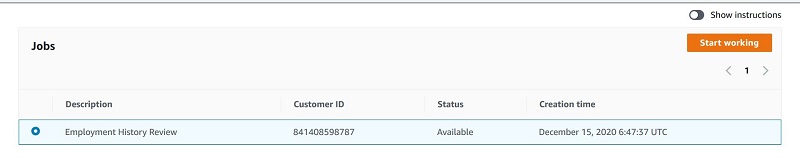
You’re redirected to the Amazon A2I console, where you find the original document displayed, your key-value pair, the text responses detected from Amazon Textract, and your table’s responses.

Scroll down to find the correction form for key-value pairs and text, where you can verify the results and compare the Amazon Textract response to the original document. You will also find the UI to modify the tabular handwritten and printed content.

You can modify each cell based on the original image response and reenter correct values and submit your response. The labeling workflow is complete when you submit your responses.
Evaluating the results
When the labeling work is complete, your results should be available in the S3 output path specified in the human review workflow definition. The human answers are returned and saved in the JSON file. Run the notebook cell to get the results from Amazon S3:
The following code shows a snippet of the Amazon A2I annotation output JSON file:
Storing the Amazon A2I annotated results in DynamoDB
We now store the form with the updated contents in a DynamoDB table so downstream applications can use it. To automate the process, simply set up an AWS Lambda trigger with DynamoDB to automatically extract and send information to your API endpoints or applications. For more information, see DynamoDB Streams and AWS Lambda Triggers.
To store your results, complete the following steps:
- Get the human answers for the key-values and text into a DataFrame by running the following notebook cell:
- Get the human-reviewed answers for tabular data into a DataFrame by running the following cell:
- Combine the DataFrames into one DataFrame to save in the DynamoDB table:
Creating the DynamoDB table
Create your DynamoDB table with the following code:
You get the following output:
Uploading the contents of the DataFrame to a DynamoDB table
Upload the contents of your DataFrame to your DynamoDB table with the following code:
Note: When adding contents from multiple documents in your DynamoDB table, please ensure you add a document number as an attribute to differentiate between documents. In the example below we just use the index as the line_nr because we are working with a single document.
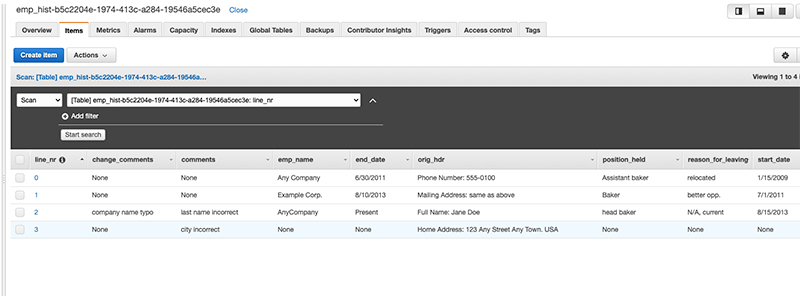
To check if the items were updated, run the following code to retrieve the DynamoDB table value:
Alternatively, you can check the table on the DynamoDB console, as in the following screenshot.
Conclusion
This post demonstrated how easy it is to use services in the AI layer of the AWS AI/ML stack, such as Amazon Textract and Amazon A2I, to read and process tabular data from handwritten forms, and store them in a DynamoDB table for downstream applications to use. You can also send the augmented form data from Amazon A2I to an S3 bucket to be consumed by your AWS analytics applications.
For video presentations, sample Jupyter notebooks, or more information about use cases like document processing, content moderation, sentiment analysis, text translation, and more, see Amazon Augmented AI Resources. If this post helps you or inspires you to solve a problem, we would love to hear about it! The code for this solution is available on the GitHub repo for you to use and extend. Contributions are always welcome!
About the Authors
 Prem Ranga is an Enterprise Solutions Architect based out of Atlanta, GA. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an autonomous vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Atlanta, GA. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an autonomous vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
 Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with the World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML explainability areas in AI/ML.
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with the World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML explainability areas in AI/ML.
 Sriharsha M S is an AI/ML specialist solution architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, big data, analytics, and machine learning.
Sriharsha M S is an AI/ML specialist solution architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, big data, analytics, and machine learning.