AWS Cloud Operations Blog
Chaos engineering leveraging AWS Fault Injection Simulator in a multi-account AWS environment
Large-scale distributed software systems in the cloud are composed of several individual sub-systems—such as CDNs, load balancers, web servers, application servers and databases—as well as their interactions. The interactions sometimes have unpredictable outcomes caused by unforeseen events (for example, a network failure, instance failure, etc.). These events can lead to system-wide failures of your critical workloads. As such, creating the real-world conditions is needed to uncover the hidden bugs, monitoring blind spots, and performance bottlenecks. This becomes complex especially in distributed systems.
In this post, we demonstrate how application development teams can build confidence in their applications leveraging AWS Fault Injection Simulator (FIS). The FIS service is configured to run complex scenarios with common system failures. Having such controlled fault injections help teams to easily identify performance bottlenecks, monitoring blind spots and stress test applications at scale, hence enabling our customers to better validate their application behavior.
We will then show you how to integrate chaos engineering as AWS Service Catalog products and portfolios and share them across your organization using CfCT. Furthermore, we will provide example experiments that you can execute on web servers and Amazon RDS instances to test for high availability. The solution is deployable with a few clicks, and it can be extended as a standard pattern for injecting failures across different applications.
Phases to conduct Chaos Engineering Experiments
Chaos engineering is the discipline of experimenting on a distributed system to build confidence in a system’s capability to make sure that the impacts of failures are mitigated. This is a modern approach to testing and validating your application architectures. The key to chaos engineering is intentionally injecting failures into your application in a controlled manner. Injecting these failures helps you identify architectural defects and evaluate the efficiency of incident management systems that are critical to the recovery and its dependencies.
Before diving into the weeds of our solution, let’s understand the basic principles of Chaos Engineering that help define experiments suitable for your applications. Always start with a well-defined formalized process to conduct your experiments. This includes understanding the steady state of your application, articulating a hypothesis, as well as verifying and learning from experiments. This helps improve the resiliency of your overall system. Figure 1 demonstrates this:

Figure1 : An example of different phases of how to conduct Chaos Engineering experiment
- Define Steady State: After injecting a failure, you must return to a well-known steady state and the experiment conducted should not interfere with the system’s normal behavior.
- Continuously Monitor: Analyzing key metrics for your applications is essential. If you can’t measure your system, then you can’t monitor drifts in steady state or even evaluate one. We recommend measuring key metrics for your applications – host level, network level, and application level, including any human processes that are involved.
- Define hypothesis: Once you have your steady state defined and monitoring enabled for key metrics, start writing a hypothesis. Examples could include “What if front end load balancer is down”, “What if my primary database is down”, “What if Direct Connect is down”, or “what if Route 53 DNS is down”. Start with one hypothesis, and start simple. It’s a best practice to make the hypothesis on parts of the system that you believe are resilient.
- Define, design, and run the experiment: Next, scope out your experiment that will be conducted. This includes selecting a hypothesis, defining an experiment, identifying relevant metrics to measure, and notifying the organization stakeholders.
- Learn and Verify: To learn and verify, monitoring is critical. Invest in monitoring, as this helps to quantify your findings while conducting experiments. Consider the time to detect failures, time for notification and escalation, time for graceful degradation, time for self-healing, time to recovery, and time to get back to stable.
- Improve and Fix: This is an important step. Prioritize fixing the findings of experiments over developing new features. It may require a cultural paradigm shift in enforcing this phase.
Key terms to understand our solution
In this section, let’s first review a few key concepts:
- A product is a blueprint for building your AWS resources that you want to make available for deployment on AWS along with the configuration information. You create a product by importing a CloudFormation template. A product can belong to multiple portfolios. To know more about the product, see the AWS Service Catalog documentation. In this solution, a product leveraging the fault injection service is created to conduct two experiments – one on webservers and the other on Amazon RDS.
- A portfolio is a collection of products, together with the configuration information. Use portfolios to manage the user access to specific products. You can grant portfolio access at AWS Identity and Access Management (IAM) identities such as user, group, and role. To know more about the portfolio, see the AWS Service Catalog documentation. In this solution, you will add the product created using fault injection service to the portfolio and sharing it across an account or organization.
- A provisioned product is a CloudFormation stack, that is, the AWS resources that are created. When an end user launches a product, the AWS Service Catalog provisions the product in the form of a CloudFormation stack. To know more about the provisioned product, see the AWS Service Catalog documentation. In this solution, you will launch the product in the target accounts that will conduct the experiments.
- The customizations for AWS Control Tower (CfCT) solution combines AWS Control Tower and other highly-available, trusted AWS services to help customers more quickly set up a secure, multi-account AWS environment using AWS best practices. Easily add customizations to your AWS Control Tower landing zone using an AWS CloudFormation template and service control policies (SCPs). Deploy the custom template and policies to individual accounts and organizational units (OUs) within your organization. This solution integrates with AWS Control Tower lifecycle events to make sure that resource deployments stay in sync with your landing zone. In our solution, we leverage the CfCT to provision the overall infrastructure required.
Architecture
We leverage the AWS Fault Injection Simulator (FIS) and its integration with AWS Service Catalog and AWS Control Tower to induce failures in a multi-account setup. In this approach, we leverage CfCT to provision one AWS Service Catalog portfolio and a product using AWS fault injection service, which is then shared with other AWS accounts.
Figure 2 illustrates three accounts of a multi-account environment. There is an AWS Control Tower Shared Services account where a AWS Service Catalog portfolio and a product leveraging Fault injection service is created. The portfolio is shared with the remaining account in the organization. There is a target-account (spoke) account where failures are injected. In this spoke account we have two fault injection experiments, one for web server instances, and another for Amazon RDS instances. Note that you can create other experiments in the target account as per your requirements.
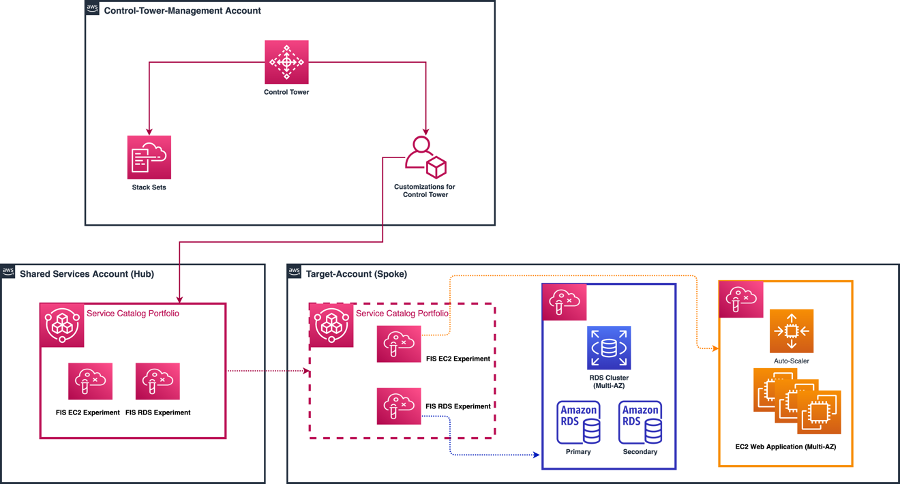
Figure 2: A multi-account Control Tower environment with Fault Injection experiments shared via AWS Service Catalog
Prerequisites
- Use a separate AWS Account to centrally host the approved list of AWS Service Catalog products, which is different from the management account. We’ll refer to this account as the “Shared Services” account. The purpose of the Shared Services Account is to act as a hub not only for AWS Service Catalog, but also for any distributed service that requires centralized management.
- It’s assumed that you have the following accounts created and enrolled in the AWS Control Tower landing zone: Management Account, Shared Services Account, Target Account(s).
- Additionally, you should have an auto-scaled Amazon Elastic Compute Cloud (EC2) instance(s) and Amazon RDS instance with the following Tag key-value pair in the accounts where FIS experiments will be run. An example template to deploy targets can be found here.
- Finally, it’s assumed that readers have experience deploying CfCT framework.
Deployment
The deployment consists of five main steps :
Step 1 – S3 bucket in Control Tower Management Account that stores the code for AWS service catalog products used for FIS experiments.
Step 2 – Configuration changes to Control Tower Management Account
Step 3 – Changes to manifest file and parameter configurations in Management Account
Step 4 – Configuration changes to Spoke Accounts
Step 5 – Deploy the FIS experiments
The code used for the solution can be found in github repository .
Step 1 – S3 bucket in Management Account that stores the code for AWS service catalog products used for FIS experiments
- Log in to AWS console of Control Tower Management Account and select the Cloudformation service in the region of CfCt deployment.
- Launch a Cloudformation stack using s3-bucket-template.
- Upload the FIS-experiment-template as an object to the S3 bucket created above. Copy the object URL into your notepad as it will be used in further steps below.
Step 2 – Configuration changes to Control Tower Management Account
- First, deploy the CfCT framework in the AWS Control Tower Management Account. Follow the implementation guide. The framework can be deployed using the ‘Launch in the AWS Management Console’ button in the link provided. Use the default parameters when deploying the framework.
- Set up Amazon Simple Storage Service (S3) as the configuration source by following the steps outlined in appendix-a.
- Enable trusted access for AWS Service Catalog in your AWS Organizations organization. Navigate to AWS Organizations, Services, Service Catalog, and choose Enable trusted access. Enabling trusted access lets AWS Service Catalog Portfolio be distributed within your organization.
- Delegate the Shared Services account as a delegated administrator for AWS Service Catalog. This lets your Shared Services account act as an administrator when sharing Portfolios to spoke accounts.
- From the Management Account, check your current list of delegated administrator accounts by running the following command:
aws organizations list-delegated-administrators
If this is your first time running this command, then you should receive an empty response.
-
- To designate the Shared Services account as an administrator, run the following command:
aws organizations register-delegated-administrator --account-id <YOUR_AWS_ACCOUNT_ID> --service-principal servicecatalog.amazonaws.com
-
- To verify the delegation, rerun the command:
aws organizations list-delegated-administrators –service-principal servicecatalog.amazonaws.com
The response will show the delegated account details.
Step 3 – Changes to manifest file and parameter configurations in Management Account
- Download the custom-control-tower-configuration.zip file and unzip them.
- Update /parameters/sc-pf-pr-source.json for “OrganizationalUnit” with your Organization ID and “Provisioning Template” with the URL for the FIS source code object created in Step 1.
- Update the parameters for region, location path of resource file and parameter file and IDs of accounts in manifest.yml.
- Compress/zip the files back with name custom-control-tower-configuration.zip.
Step 4 – Configuration changes to Spoke Accounts
In the spoke account, you will require to designate users/groups/roles to the imported Portfolio. To do this, follow the below steps :
- Log in to the AWS console in spoke account in the region where CfCt is being deployed. Navigate to AWS Service Catalog.
- In the Imported portfolio details page, expand Users, groups and roles, and then choose Add user, group or role.
- Choose the Groups, Users, or Roles tab to add groups, users, or roles, respectively.
- Choose one or more users, groups, or roles, and then choose Add Access to grant them access to the current portfolio.
- Using the identity that you designated in the prior step, launch the Chaos Engineering product by navigating to ‘Products’ (above Administration grouping if visible) and launch the product.
Step 5 – Deploy the FIS Experiment
- From the same Spoke Account used above, navigate to the AWS FIS console. On the left-hand menu, select ‘Experiment templates’. You should see two FIS Experiment templates: RebootRDSInstances, StopEC2Instances.
- Select one of the experiment templates to run (make sure that you have EC2/RDS instances that meet the requirements listed in the Prerequisites section above).
- Choose Actions, and Start experiment. When prompted, enter start, and choose Start experiment.
- Navigate to the EC2 and Amazon RDS console to observe the Experiment executions. You should observe EC2 instances being terminated and recreated via the Auto Scaler. For the Amazon RDS experiment, you should see the Amazon RDS primary DB being rebooted.
Note the following:
- Additional actions can be added to existing Experiment Templates by selecting Update in the Actions dropdown in the desired Experiment Template. From there, Actions can be added and removed depending on the intent of what must be tested.
- Experiment Targets can also be customized by updating the experiment and adding Targets. Targets are specified by Resource IDs or Resource tags and filters. In this post, we use the following tag key-value pair: ChaosTesting, ChaosReady.
Cleanup
After successful testing and validation, all of the resources deployed through CloudFormation templates should be deleted to avoid any unwanted costs. Simply go to the CloudFormation console, identify the appropriate stacks, and delete them. Additionally, experiment templates must be deleted manually from the Target-Account (Spoke).Note that if you use a multi-account setup, then you must navigate through account boundaries and follow the above steps as needed.
Conclusion
In this post, we showed how you can leverage Fault Injection Simulator service to inject failures in a controlled way. We provided you with a customization to the CfCT solution that provisions the AWS Service Catalog portfolio with chaos engineering products for Amazon RDS and EC2. The example experiments can be used against web servers and Amazon RDS instances to investigate application behaviors at scale in a large multi account setup. This have helped our customers create the real-world conditions for application resiliency and detect performance bottlenecks that are difficult to find in distributed systems. We hope that this post is helpful, and we look forward to hearing about how you use this solution.