AWS Open Source Blog
Virtual GPU device plugin for inference workloads in Kubernetes
Machine learning (ML) has become a centerpiece for enterprise transformation. AWS provides a broad and deep set of ML capabilities for builders with all levels of expertise. Developers with no prior ML experience can seamlessly build sophisticated AI-driven applications using AWS AI services. Developers and data scientists can use Amazon SageMaker, a managed machine learning service to build, train, and deploy ML models quickly. Expert ML practitioners who work at the framework level can use open source machine learning frameworks and AWS infrastructure to build, train, tune, and deploy ML models.
In this post, we will introduce an open source solution to schedule virtual GPU resource on Amazon Elastic Kubernetes Service (Amazon EKS). Expert ML practitioners may refer to this solution to build their inference application by using GPU efficiently.
Within the infrastructure layer, model training is the compute-intensive work in a typical ML pipeline; predictions, or inference, accounts for up to 90% of total operational costs. For example, autonomous vehicle (AV) development may require thousands of GPUs to train machine learning models, and require millions of CPUs or GPUs to validate their software/models with log or synthetic simulations.
Inference workloads have two major challenges. First, standalone GPU instances are designed for model training and are typically oversized for inference. Although training jobs can batch process hundreds of data samples in parallel, most inference happens on a single input in real time and consumes only a small amount of GPU compute. Even at peak load, a GPU’s compute capacity may not be fully utilized.
Second, different models need unique amounts of GPU, CPU, and memory resources. For example, a simple language processing model may require only one TFLOPS (trillion floating point operations per second) to run an inference, whereas a sophisticated computer vision model may need up to 32 TFLOPS. Selecting a GPU instance type that is big enough to satisfy the requirements of the most demanding resource often results in under-utilization of other resources.
AWS provides several services to address these challenges and to reduce the cost of inference.
Amazon Elastic Inference allows us to attach low-cost GPU-powered acceleration to Amazon Elastic Compute Cloud (Amazon EC2) and Amazon SageMaker instances to reduce the cost of running deep learning inference by up to 75% because we no longer need to over-provision GPU compute for inference.
AWS Inferentia provides high throughput, low latency inference performance at a low cost. Each chip provides hundreds of TOPS of inference throughput to allow complex models to make fast predictions. Inf1 instances were powered by AWS Inferentia and launched at AWS re:Invent 2019.
Amazon Elastic Kubernetes Service (EKS) has quickly become a leading choice for machine learning workloads. It combines the developer agility and the scalability of Kubernetes, with the wide selection of Amazon EC2 instance types available on AWS, such as the C5, P3, and G4 families. Amazon EKS also support integration with Elastic Inference and Inf1 instances. We can choose EKS with GPU instances if we want to migrate inference workloads based on GPU resources to EKS without modification.
Challenges to using GPUs in Kubernetes efficiently
By using namespaces and cgroups in Linux, Kubernetes can schedule pods with required CPU and memory on nodes that have corresponding free resources, and then use containers to set a quota of CPU and memory for processes to be run in containers. However, currently Kubernetes has no internal support for GPU resource scheduling and isolation. Instead, it is implemented by third-party through the device plugin and scheduler extension.
Nvidia Kubernetes Device Plugin is the commonly used device plugin when using Nvidia GPUs in Kubernetes. Nvidia Kubernetes device plugin supports basic GPU resource allocation and scheduling, multiple GPUs for each worker node, and has a basic GPU health check mechanism. However, the GPU resource requested in the pod manifest can only be an integer number as shown below. This means it does not support sharing single GPU among multiple pods, which make the GPU resource under-utilized in scenarios such as model inference in machine learning.
Another challenge is the GPU resource isolation when multiple containers share one GPU. By default, multiple containers/processes can be concurrently, but not parallelly, on one GPU; the time slice-based multiple task scheduling will impact the overall performance. GPU memory isolation also is not applicable by default. Applications typically must set their own GPU memory limits in a cooperative resource management manner. For example, TensorFlow has the parameter per_process_gpu_memory_fraction to set the fraction of the available GPU memory to allocate for each process.
Solution
The idea to address the limitation to set fractional number of GPU resource for each pod is to set a virtual unit for each GPU resource in Kubernetes device plugin. For example, we can allocate 10 virtual GPUs for each physical GPU, while the pod requests 1 GPU unit represented 1/10 physical GPU resource. Be aware that the resource allocation only happens in the scheduler of Kubernetes. There’s no constraint for GPU consumption with containers, which is different from CPU and memory allocation. By default, GPU dose not support resource isolation while multiple containers share one GPU.
Nvidia provides the Multi-Process Service (MPS) implementation for the CUDA-compatible API to improve the resource utilization for applications running in parallel. They recently added a new QoS feature in MPS that allows programmers to specify an upper limit on the number of GPU threads available for each application to limit available compute bandwidth on a per-application basis.
So, we designed our GPU device plugin to address these issues by implementing the Kubernetes device plugin and Nvidia MPS. This project has been open sourced on GitHub. Let’s see how it works and how to use it in a machine learning inference workload.
How it works
Kubernetes provides a device plugin framework that we can use to advertise system hardware resources to the Kubelet.
Instead of customizing the code for Kubernetes itself, vendors can implement a device plugin to deploy either manually or as a DaemonSet. The targeted devices include GPUs, high-performance NICs, FPGAs, InfiniBand adapters, and other similar computing resources that may require vendor-specific initialization and setup.
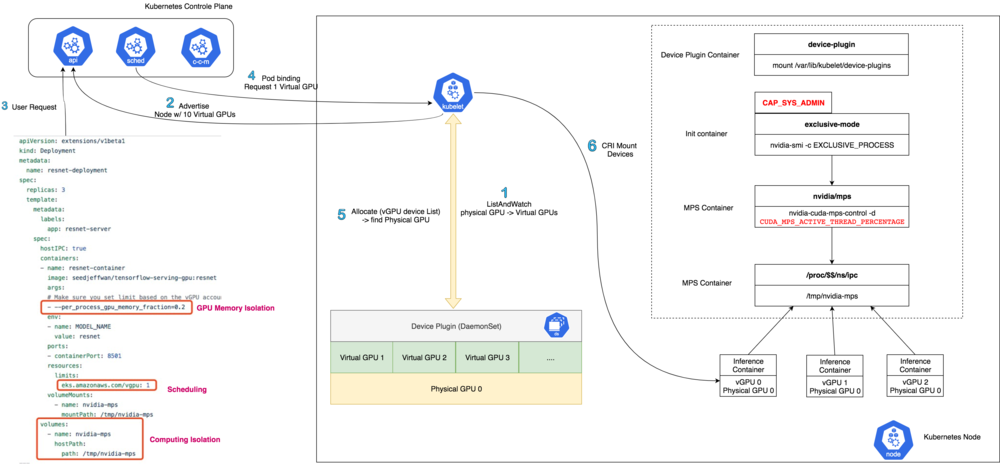
Device Plugin advertises virtual number of GPU cards to APIServer during ListAndWatch. There is a multiplier factor users can configure to map physical GPUs to virtual GPUs.
Device Plugin implements custom Allocate logic to retrieve binding pods and map the virtual GPU resources to physical device id. We set NVIDIA_VISIBLE_DEVICES to physical GPU card ID to containers and this will be visible to the container.
Users need to control three things:
CUDA_MPS_ACTIVE_THREAD_PERCENTAGEin device plugin: Each CUDA application won’t use GPU threads more than this factor.per_process_gpu_memory_fraction: This is a TensorFlow setting to determine how much memory that process consumes. MPS doesn’t provide GPU memory-level isolation; splitting GPU memory for each process based on application workloads is important. Other frameworks, such as PyTorch or MxNet, have similar configurations.- Custom resource
k8s.amazonaws.com/vgpu: This will be used by the scheduler to filter nodes with resources.
How to use the AWS virtual GPU device plugin
- Follow the “Getting started with eksctl” document to install and configure AWS Command Line Interface (AWS CLI), eksctl, and kubectl.
- Create an EKS cluster with 2 g4dn.xlarge instances. Add the label k8s.amazonaws.com/accelerator=vgpu for worker nodes, which is needed by AWS virtual GPU device plugin:
- Completing the cluster and node group creation may take up to 10 minutes. After the cluster is created, let’s check the worker nodes and their labels:
- Install AWS virtual GPU device plugin:
- Deploy GPU pods:
Benchmark
To run the machine learning inference benchmark to evaluate the performance when running multiple pods on one GPU, follow the steps in the GitHub repository to get the benchmark result.
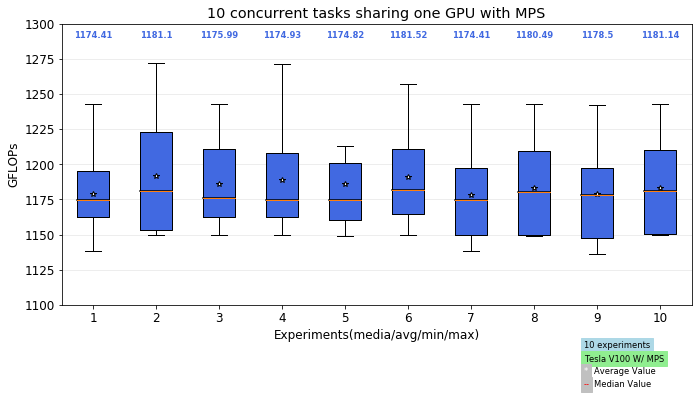
We run 10 experiments and each experiment runs 10 tasks. We can see GFLOPS is stable across every task, which means GPU can evenly share resources. It also means applications QoS is guaranteed in a GPU share environment.
Tips
As MPS cannot isolate GPU memory for each process, we may need to set GPU memory consumption limit in each process to avoid an out of memory issue when running multiple processes in parallel. For example, TensorFlow provides the parameter gpu_memory_frac_for_testing to set the fraction of GPU memory that will be used.
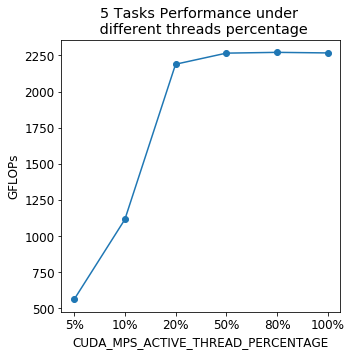
We may need to tune the parameter CUDA_MPS_ACTIVE_THREAD_PERCENTAGE to limit the percentage of GPU threads available for each process to improve the utilization of GPU resource; however, higher value doesn’t always get higher performance. The following is the test result for different CUDA_MPS_ACTIVE_THREAD_PERCENTAGE with five tasks:
We can update CUDA_MPS_ACTIVE_THREAD_PERCENTAGE with the following command:
kubectl set env -n kube-system ds/aws-virtual-gpu-device-plugin-daemonset -c mps CUDA_MPS_ACTIVE_THREAD_PERCENTAGE=20The default value of virtual GPUs number for each physical GPU is 10. If you need to run more than 10 GPU pods on one physical GPU, you can update the argument for the container aws-virtual-gpu-device-plugin-ctr. For example, set 20 vGPUs:
Clean up
Conclusion and future work
Efficiently running machine learning inference workload on GPU with Kubernetes is not easy. We demonstrated a solution to use a Kubernetes device plugin and Nvidia MPS to run inference jobs on GPU, which can significantly improve the GPU resource utilization and reduce cost.
Nvidia released their latest GPU based on the Nvidia Ampere architecture, the Nvidia A100. The Nvidia A100 Tensor Core GPU delivers acceleration for AI, data analytics, and high-performance computing (HPC). One exciting feature in A100 is it can be securely partitioned into as many as seven separate GPU instances to accelerate workloads of all sizes, with Nvidia Multi-Instance GPU (MIG) technology. MIG promises Qos at the GPU Instance level. All instances share memory and available GPU engines with all other compute instances on the same GPU instance. Technically, users can enable MPS with MIG together to share GPUs at the compute instance level. We plan to add the support in an AWS virtual GPU device plugin later.
References
AWS:
- Amazon Elastic Inference–GPU-Powered Deep Learning Inference Acceleration
- Amazon Elastic Inference–Reduce Deep Learning inference costs by 75%
- Running Amazon Elastic Inference Workloads on Amazon ECS
- Optimizing TensorFlow model serving with Kubernetes and Amazon Elastic Inference
- Introducing Amazon EC2 Inf1 Instances, high performance and the lowest cost machine learning inference in the cloud
Community:
- Nvidia Multi-Instance GPU
- Nvidia A100 Tensor Core GPU Architecture (PDF)
- Nvidia Turing GPU Architecture (PDF)
- Nvidia Tesla V100 GPU Architecture (PDF)
- Is sharing GPU to multiple containers feasible?
- Fractional GPUs: Software-based Compute and Memory Bandwidth Reservation for GPUs
- GPU Sharing Scheduler Extender Now Supports Fine-Grained Kubernetes Clusters
- GPU Sharing for Machine Learning Workload on Kubernetes (YouTube)
- Deep Learning inference cost optimization practice on Kubernetes (PDF, Chinese)
- Gaia Scheduler: A Kubernetes-Based Scheduler Framework