AWS Security Blog
Tag: AWS CLI
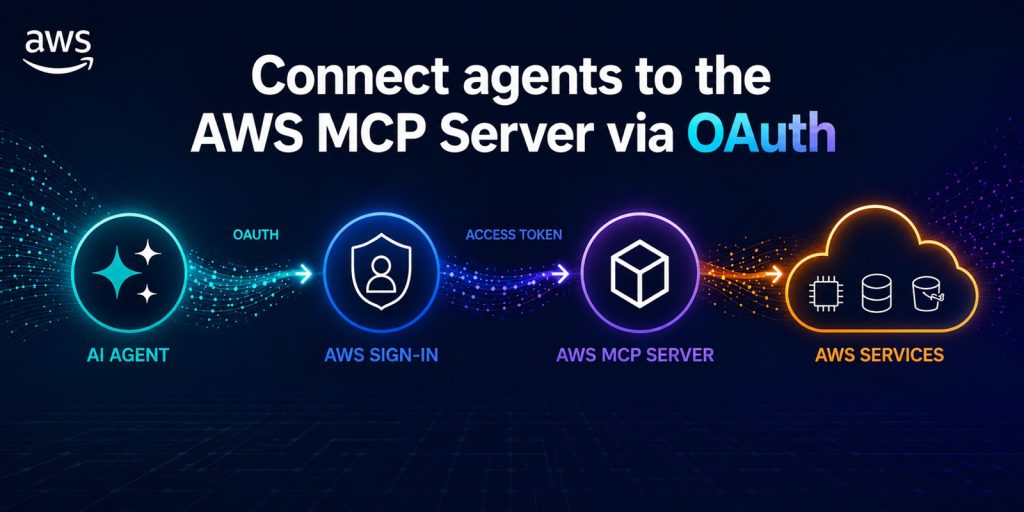
Introducing OAuth Support for AWS MCP Server
You can now connect your agents to the AWS MCP Server using the same credentials and sign-in methods that you already use for connecting to the AWS Management Console or AWS Command Line Interface (AWS CLI) through a familiar browser-based experience powered by industry-standard OAuth. This new sign-in path supports AWS Identity and Access Management […]
Simplified developer access to AWS with ‘aws login’
Getting credentials for local development with AWS is now simpler and more secure. A new AWS Command Line Interface (AWS CLI) command, aws login, lets you start building immediately after signing up for AWS without creating and managing long-term access keys. You use the same sign-in method you already use for the AWS Management Console. […]

Temporary elevated access management with IAM Identity Center
AWS recommends using automation where possible to keep people away from systems—yet not every action can be automated in practice, and some operations might require access by human users. Depending on their scope and potential impact, some human operations might require special treatment. One such treatment is temporary elevated access, also known as just-in-time access. […]

How to use Google Workspace as an external identity provider for AWS IAM Identity Center
January 25, 2024: This post is no longer current. Please see this tutorial for the updated info. March 21, 2023: We modified the description of a permission set in the Introduction. March 8, 2023: We updated the post to reflect some name changes (G Suite is now Google Workspace; AWS Single Sign-On is now AWS […]

Managing temporary elevated access to your AWS environment
September 27, 2023: We updated this post to include a list of newer temporary elevated access solutions that integrate with AWS IAM Identity Center. September 9, 2022: This blog post has been updated to reflect the new name of AWS Single Sign-On (SSO) – AWS IAM Identity Center. Read more about the name change here. […]

New IAMCTL tool compares multiple IAM roles and policies
If you have multiple Amazon Web Services (AWS) accounts, and you have AWS Identity and Access Management (IAM) roles among those multiple accounts that are supposed to be similar, those roles can deviate over time from your intended baseline due to manual actions performed directly out-of-band called drift. As part of regular compliance checks, you […]

Enhance programmatic access for IAM users using a YubiKey for multi-factor authentication
Organizations are increasingly providing access to corporate resources from employee laptops and are required to apply the correct permissions to these computing devices to make sure that secrets and sensitive data are adequately protected. The combination of Amazon Web Services (AWS) long-term credentials and a YubiKey security token for multi-factor authentication (MFA) is an option […]

Enable Federated API Access to your AWS Resources for up to 12 hours Using IAM Roles
Now, your applications and federated users can complete longer running workloads in a single session by increasing the maximum session duration up to 12 hours for an IAM role. Users and applications still retrieve temporary credentials by assuming roles using AWS Security Token Service (AWS STS), but these credentials can now be valid for up […]

AWS Federated Authentication with Active Directory Federation Services (AD FS)
Today we’d like to walk you through AWS Identity and Access Management (IAM), federated sign-in through Active Directory (AD) and Active Directory Federation Services (ADFS). With IAM, you can centrally manage users, security credentials such as access keys, and permissions that control which resources users can access. Customers have the option of creating users and […]

How to retrieve short-term credentials for CLI use with AWS IAM Identity Center
May 23, 2022: This blog post is out of date. Please refer here for current info: https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-sso.html September 12, 2022: This blog post has been updated to reflect the new name of AWS Single Sign-On (SSO) – AWS IAM Identity Center. Read more about the name change here. Today, AWS made it easier to use […]