AWS Startups Blog
Using Amazon Redshift & AWS Glue: How Landbay Pivoted to Provide Mortgage Payment Holidays

This article examines how Landbay used AWS and the power of Amazon Redshift and AWS Glue to adapt quickly during the COVID-19 pandemic, to ensure they adhered to government guidelines for mortgage payment holidays. It is authored by Chris Burrell, Head of Tech, Landbay
Landbay is a marketplace lender focused on the UK prime buy-to-let (BTL) market. It matches borrower requirements with investors’ pools of institutional capital. Landbay’s credit, data, and technology-led approach has seen the firm successfully lend over £0.5B since 2015 with zero defaults.
The COVID-19 pandemic resulted in a significant impact to the UK BTL mortgage market with lower origination, tighter capital market funding, and reduced risk appetite.
With no property viewings taking place during the lockdown, the market stalled. For Landbay, a lack of physical valuations resulted in a pause in the issue of new mortgage offers.
During the pandemic, the government quickly introduced new processes for mortgage holidays and special servicing. The challenge was to implement these in an environment where staff had moved to 100% remote working.
To be successful, Landbay required additional data and insights to:
- Implement new processes to facilitate mortgage holidays for our borrowers adhering with the emerging government and regulatory guidelines.
- Ensure continued ability to make fast, accurate decisions with appropriate due diligence for both requests for payment holidays and plans to exit payment holidays to ensure that our customers had the best outcomes.
- Monitor resulting mortgage holidays performance against the wider industry where today, Landbay is significantly outperforming peers.
Landbay’s cloud-based platform and the power of Amazon Redshift & AWS Glue have been instrumental in facilitating these requirements.
The data pipeline at Landbay
Many organizations have built data warehouses, but they often lack the agility to add new data sets quickly.
Landbay’s data pipeline is built on top of a micro-service architecture and leverages ELT principles (Extract Load Transform) to pump all of its operational data into Redshift.
There are three core elements to this:
1. Our source data – using MariaDB RDS & read-replicas to offload the data extraction outside of any OLTP/real-time operations traffic
2. Redshift, as the data store for all the extracted microservice’s data
3. DBT (a SQL-based data tool) to transform our source data and make it consumable to the end-user visualization tools.
The diagram below shows our pipeline in action:
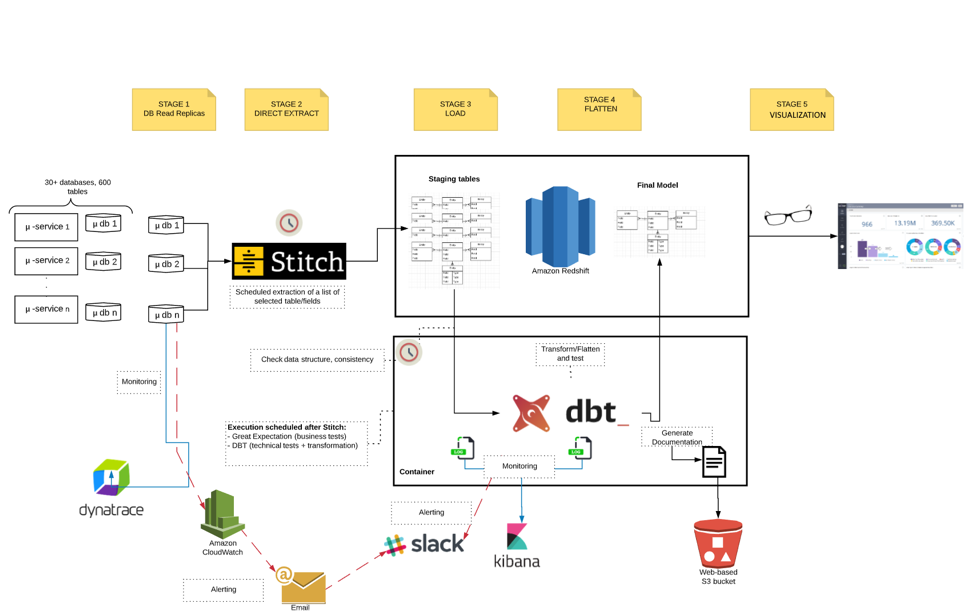
Stage 1 shows our operational databases (one per microservice) set up with read-replicas to offload any data-intensive query and a third-party provider (Stitch) to extract the data into Redshift (Stages 2 & 3).
We’re looking forward to experimenting with the new federated queries feature that would allow us to replace Stage 2 by enabling data to be available directly from our read-replicas into Redshift – this is currently available for PostgreSQL, but we await availability for MariaDB.
Stage 4 transforms the data into a consumable form. DBT is an excellent SQL-based open-source tool, compatible with many mainstream warehouses. It allows data engineers to easily change the format, amalgamating it into de-normalized fact tables.
Bruno Murino, one of our data engineers, says, “As a contributor to DBT myself, the speed at which new DBT features are made available to the community means businesses including Landbay find it incredibly easy to solve even the most complex use cases.”
Stages 5 & 6 make the data available to our end-user visualization tools. At Landbay, we’ve opted for a tool where we can model data once to provide consistency and control across the business while still allowing all of our users to self-serve and build reports.
For more details, check out the talk on Awesome CI/CD Data pipelines for distributed data sources, which goes into more depth.
This process is all well and good; however, shouldn’t introducing new data sources be more straightforward than having to build entire new microservices?
Getting the data onto the platform quickly
In our particular use case, reporting data on our borrower’s situation (for example, the historical performance of their payments, arrears, and loan details) comes in the form of CSV files over SFTP.
Before AWS released their AWS managed SFTP transfer service, Landbay built an Amazon S3-backed SFTP service using s3fs-fuse file system on a burstable t3 instance, which for low ad-hoc volumes is still to this day more than sufficient for our needs.
The service allows us to shift large data files between external partners and internal systems quickly. When data writes to the file system over SSH/SFTP, the filesystem transparently writes it to S3.
This mechanism is ideal as it removes the need for user interaction to upload, or key in files manually, through a browser app. With the data now on S3, we then get it loaded into Redshift.
Leveraging AWS Glue & Amazon Redshift to load the data
One of Redshift’s excellent features is its Redshift Spectrum capability, which we use to make S3 files available through a simple create table statement.
With previous data sets, we manually ran those SQL-like statements to create materialized views. As such, when our pipeline transformations tool (DBT) runs, it can be agnostic as to whether the data is actually in Redshift or stored on S3 behind the scenes.
As we added more and more data sources, we started to investigate the benefits of Glue. With Glue’s crawler, we can automatically create a catalogue of data tables by scanning a set of S3 buckets.
Once set up, configuring a new data source is a few steps away. This process prompts Glue to automatically detect the schema and semantics of the data held in the bucket.
As an aside, since Redshift Spectrum charges “per byte scanned,” a columnar storage format allows us to optimize both cost and performance. During a hackathon, we experimented and measured some of the promised cost savings and performance boosts and configured our bigger data sets to use the Parquet format. By using the “bytes scanned” metrics within Redshift, we were able to estimate a 30x cost reduction on some of our data sources. This is because we read a fraction of the CSV file for each query now. Performance-wise between, we ran a small set of benchmarks on our data and observed roughly 3-5x performance boost.
When running the crawler, it will turn any insights about your data (for example, columns, relevant column order in CSV files) into a table in the Glue data catalogue. With Glue configured to surface these tables into Redshift as Spectrum tables, we can then use the data. In other words:
Step 1 – Create a bucket and configure in Glue and upload some data
Step 2 – Wait for tables to appear in Redshift automatically
Step 3 – Write a SQL query to transform the incoming data into the required fact table using DBT
All in all, to provide our data to our end users takes somewhere between 2-4 hours!
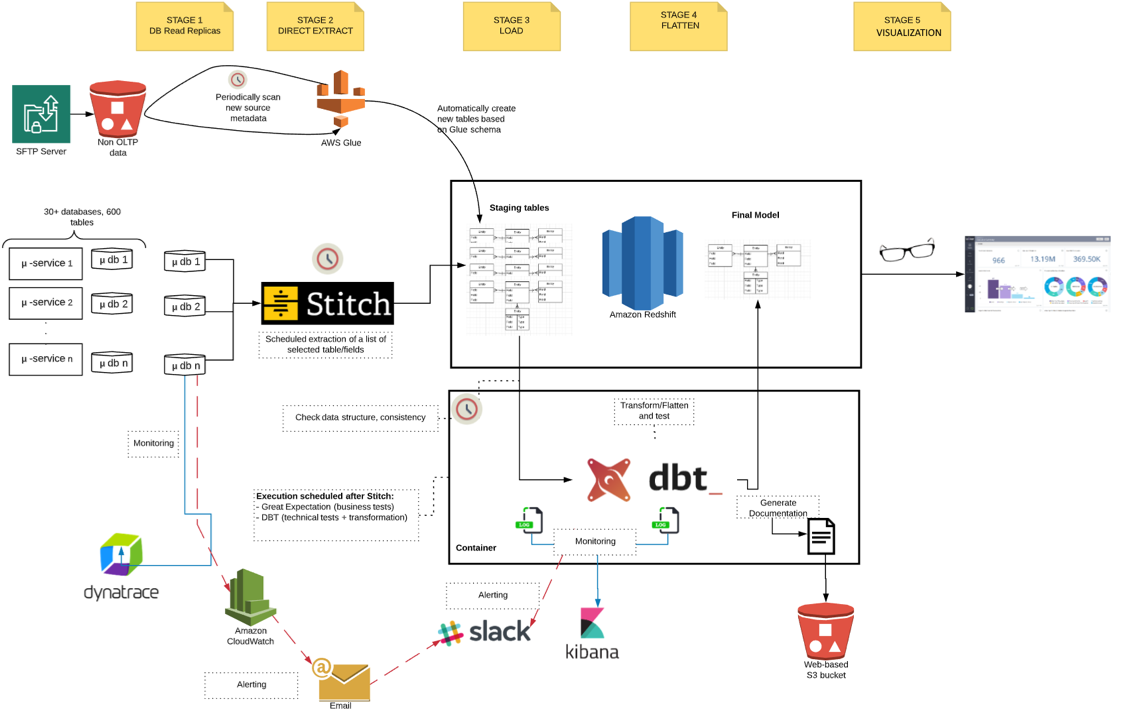
The revised diagram below shows the new SFTP-based files arriving into our data pipeline.
One of the reports we produced
The graph below is one of the many reports our staff can generate with a click of a button. The visualization shows our ratio of payment holidays in comparison to the market:
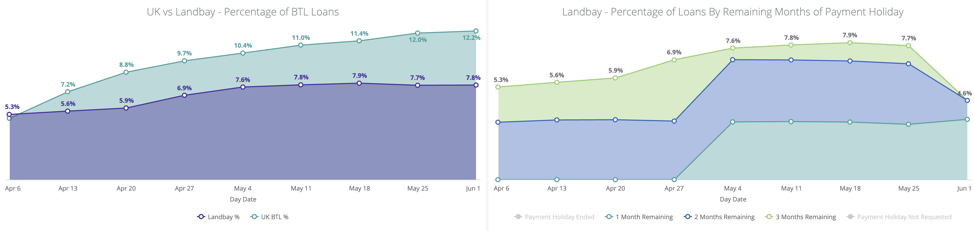
This graph shows that we are now able to quantify the impact of mortgage payment holidays with the direct effects on the drop of interest payments and thereby predict the return of revenue in the coming months.
Having given mortgage payment holidays of 1, 2, or 3 months depending on their circumstances, we can now track potential missed payments across our entire loan book.
For example, on April 13th, 2020, we had approximately 5.6% of our loans with three months or less of payment holidays left. As time goes on, the graph shows that the number of payments remaining goes down as the remaining months of the holiday are used up.
As you can see, in comparison to the average market, Landbay has been able to keep its volume low and the holidays appropriately sized to help our borrowers. This data has helped re-assure our various funding partners and underlines the quality of loans underwritten by Landbay.
Final thoughts
In addition to bringing in data from our RDS databases, Glue and Redshift Spectrum allow us to bring in new data sets exceptionally quickly, helping Landbay achieve three significant benefits:
A holistic view of our data has enabled us to provide a decision within 24-hours (other lenders are taking several weeks before giving an outcome). This speed is possible because the data is available with a few clicks.
Landbay has been able to prioritize our most distressed customers and keep the mortgage holidays as low as possible. While industry levels vary from 18% to 30% of their loan books, Landbay has been able to reduce the impact to just 12%.
Landbay now has a longer-term infrastructure that caters for any data source uploaded in a file-based format. Data is now only 2-4 hours away from being able to be used directly from our data warehouse and visualization tools.
We know that the market will recover in time, and we are working hard to invest in continuous improvement to our platform, products, and processes so that we can come out of this stronger.
Our engineering team has continued to deliver new functionality, and we are using our additional underwriter capacity due to lower volumes to shape these requirements.
We have a vision to be the leading BTL lending platform in the UK. That means we are the go-to lender in this space and a default option for brokers, and the partner for choice for those that want to invest in BTL mortgages. We are well on the way!
Check out career opportunities at Landbay, or, to find out more about Landbay, visit our website.