AWS Storage Blog
AWS re:Invent recap: Optimize your data migration with AWS Snow Family

At AWS re:Invent 2020-2021, Ramesh Kumar, Senior Manager of Product Management for the AWS Snow Family, presented a session on “Optimizing data migrations with AWS Snowcone and AWS Snowball Edge“. That session, now on-demand, shed some light on solutions, services, and considerations for optimizing your data migration to AWS with those devices. Ramesh also discussed tooling and methodologies to transfer and migrate data from any edge location to the AWS Cloud while addressing edge computing usage scenarios. He closed by highlighting customers who have successfully performed multi-petabyte data migrations to AWS using multiple AWS Snowball Edge devices, providing customer examples of several different scenarios and use cases.
In this blog, I provide details and background around Snowcone and Snowball from a data migration perspective, recapping his session at re:Invent 2020-2021.
Overview
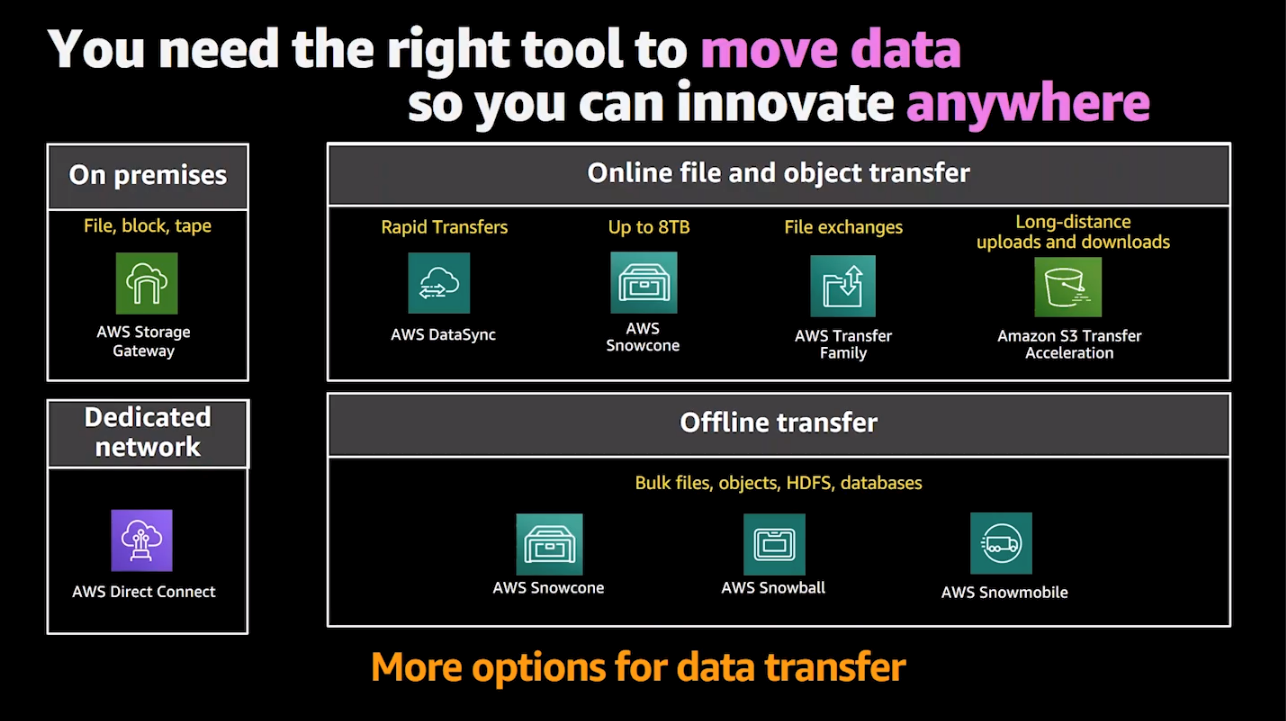
At the start of the session, Ramesh gave an overview of the multiple AWS solutions, services, and tools for offline and online data migration to AWS from any edge location. Although online and offline data migration methods were discussed, the majority of the session was focused on offline data migrations. For offline data migrations from edge locations or locations with limited to no connectivity, consider the AWS Snow Family.
AWS Snowcone is the smallest member of the AWS Snow Family of edge computing, storage, and data transfer devices, weighing 4.5 pounds (2.1 kg) with 8 TB of usable storage. Snowcone is rugged, secure, and purpose-built for use outside of a traditional data center. Its small form factor makes it a perfect fit for tight spaces or where portability is a necessity and network connectivity is unreliable.
You can collect and process data at the edge, and you can ship the device with data to AWS for offline data transfer. You can also transfer data online with AWS DataSync from edge locations. Snowcone stores data securely in edge locations, and can run edge computing workloads that use AWS IoT Greengrass or Amazon EC2 instances. A Snowcone device is ultra-portable, so you can carry one in a backpack or fit it in tight spaces for IoT, vehicular, or even drone use cases. For mobile or portable workflows, you can power the Snowcone device using a battery.
AWS Snowball Edge provides edge computing and data migration capabilities; Snowball comes in two options. Snowball Edge Storage Optimized devices provide both block storage and Amazon S3 object storage, and 40 vCPUs. Customers can use multiple Snowball Edge devices to transfer up to 10 PB of data to AWS. Snowball Edge Compute Optimized devices provide 52 vCPUs, block and object storage, and an optional GPU for use cases like advanced machine learning and full motion video analysis in disconnected environments.
You can create a storage cluster with up to 15 Snowball Edge devices to store up to 1 PB of data at your edge location. To run your compute applications on Snowcone and Snowball Edge, you can develop and validate your applications on EC2 in AWS. Then, you can deploy your applications to run on the EC2 instances hosted on the Snow devices at the edge in remote locations to collect, pre-process, and upload the data to AWS. Common use cases include data migration, data transport, image collation, IoT sensor stream capture, and machine learning.
AWS Snowmobile is an exabyte-scale data transfer service used to move extremely large amounts of data to AWS. You can transfer up to 100 PB per Snowmobile, a 45-foot ruggedized shipping container, pulled by a semi-trailer truck. Snowmobile makes it easy to move massive volumes of data to the cloud, including video libraries, image repositories, or even a complete data center migration.
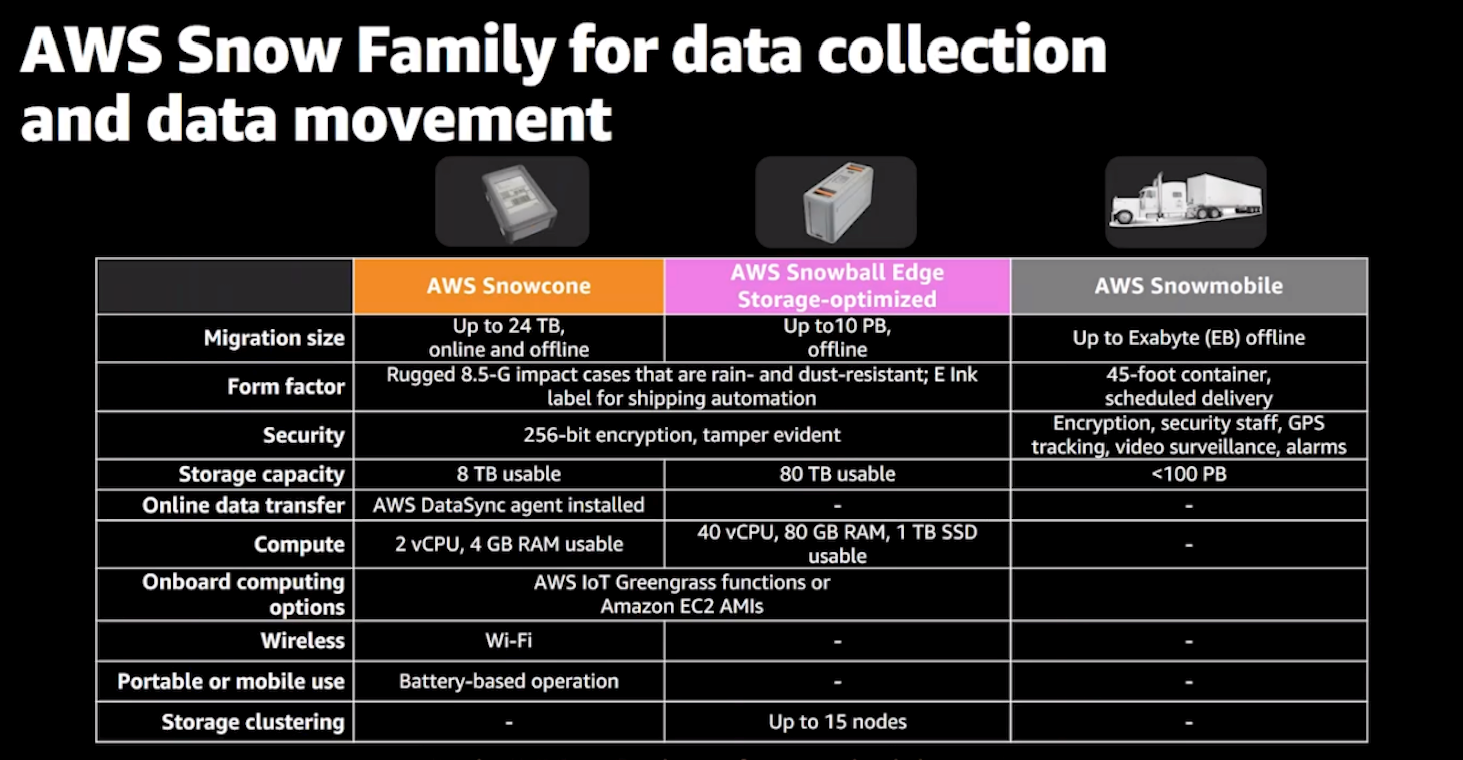
Refer to the following table for a summary comparison of the AWS Snow Family. Visit the Snow Family product page for a more detailed comparison.
After the overview of the Snow Family, Ramesh also talked about how to you can use the Snow devices for data migration in edge computing workflows. You can use Snowball Edge as an IoT hub to capture sensor data and process sensor data locally. In real-time, customers can implement image processing or video analytics functions at the edge, as well as run machine learning and inference models at the edge and at rugged locations. Snow devices can operate independent of network connectivity and AWS for long periods of time, making these devices well suited for environments with no connectivity, intermittent connectivity, or low bandwidth.
Ramesh also highlighted the security features for the Snow Family of devices. AWS Snowball Edge devices use tamper-resistant enclosures, 256-bit encryption, and industry-standard Trusted Platform Modules (TPM) designed to ensure both security and full chain-of-custody for your data. All data copied to Snow automatically encrypts using 256-bit keys that you manage by using the AWS Key Management Service (AWS KMS). Encryption keys are never stored on the device. This helps ensure that your data stays secure during device transit. The TPM provides a hardware root of trust – specifically, they are designed to detect any unauthorized modifications to the hardware, firmware, or software. AWS also uses additional tamper-indicating inspection processes after each Snow device is received back to the AWS Region to ensure the integrity of the device. With the Snow service’s encryption features, it helps preserve the confidentiality of your data.
In addition to covering data migration, Ramesh highlighted the fact that you can use the Snow devices to host edge compute applications. You can run EC2 instances based on the baseline Amazon Machine Images (AMIs) provided or create custom AMIs for your applications. In addition, you can run AWS Lambda powered by AWS IoT Greengrass locally on the Snow device.
To manage Snow devices, you can use the graphical user interface, AWS OpsHub, to rapidly deploy edge-computing workloads and simplify data migration from edge or rugged locations to the cloud. With OpsHub, you can unlock and configure devices, perform offline data transfers to Snowcone, activate DataSync for online data transfers to AWS, launch applications, and monitor device metrics. Here’s a short video demonstration of OpsHub that shows how easy it is manage Snow devices.
Data migration workflows with AWS Snow Family
After the overview, the focus switched to data migration patterns and customer examples using Snowcone and Snowball Edge.

Customers can sometimes face challenges when implementing data migration workflows to AWS. For example, transferring 1 PB of data online can take quite a long time to migrate unless you’re able to dedicate a 10Gbps network connection. Specifically, data migration considerations include the following:
- Connectivity limitations: In some edge locations, you may not have consistent network connectivity required for online data transfers.
- Bandwidth constraints: In some scenarios, you may have good network connectivity to AWS. However, you may have production or operational applications that require the use of that bandwidth, and thus there is insufficient available bandwidth for data migrations.
- Legacy environments: This can include restrictions of protocols that are permitted, incompatible filesystems, use of mainframes for data migration at the edge location, and databases running on legacy infrastructure.
- Data collected in remote or austere locations: In some use cases, customers may be capturing sensor data, machine-generated data, videos, or photos in locations where there may be no network connectivity for online data transfers.
To use a Snow device for data migration, Ramesh walked us through the end-to-end workflow from a customer’s perspective (see the following diagram). This workflow includes placing an order, transferring data, and having the data imported into S3, whereupon the Snow device goes through a secure erasure process following NIST guidelines.

Based on experience, Ramesh strongly recommended doing a proof-of-concept before any multi-petabyte data migration with 1-2 Snowball Edge devices. This helps you address any potential shortcomings or gaps in your local network. For instance, you can assess network bandwidth, workstations or servers needed, and the capability of your local network to copy data simultaneously to multiple Snowball Edge devices. In addition, this gives you the opportunity to implement best practices, batch small files, and tune your data transfers before your production data migration.

Work with your AWS account team, solutions architect, and Snow service team to plan and orchestrate your data migration. Why is this important? Ramesh gave an example of a 2-PB migration using 25 Snowball Edge devices, wherein the local network environment was only capable of copying to five Snowball Edge devices at a time. To account for the environment constraints, the Snow service team provided guidance to set up and plan five rounds, with five Snowball Edge devices in each round. AWS shipped five devices that the customer could copy data to at a time. Another five devices would go out to the customer just as soon as they were ready for them, resulting in a seamless migration (25 total devices).
To learn more about data migrations with AWS Snowball Edge and AWS Snowcone, check out the following resources:
- AWS Snowball Edge data migration guide
- Blog: Data migration best practices with AWS Snowball Edge
- Blog: Best practices for accelerating data migrations using AWS Snowball Edge
Real-World scenarios
In the later part of the session, Ramesh showed how Snowball Edge and Snowcone are used by customers.
For Snowball Edge, two petabyte-scale data migration customer examples were highlighted. Photobox, Europe’s number 1 online photo service, migrated 10 PB of photo storage to Amazon S3 using AWS Snowball Edge. This resulted in cost savings as they no longer needed to manage and maintain on-premises storage. Moreover, Photobox achieved better performance and durability with S3 compared with what they had previously, in addition to accelerating their ability to innovate on behalf of their customers.

Lotte, a leading South Korean retailer, migrated 140 million files in 2 weeks with AWS Snowball to power their ecommerce site that serves 39 million Lotte members.

With 2 vCPU and 4 GB RAM onboard Snowcone, you can run a number of computing applications at the edge. Ramesh highlighted three examples of using Snowcone at edge locations:
- Construction: Use Snowcone to capture sensor data in the field or from other machines in rugged and austere locations, and process it in real time. In environments where you may be power or space constrained, you can use a battery to power the Snowcone device.
- Shipping: For oceanographic or oil explorations, you can use Snowcone to capture data from sensors onboard ships. You can then run lightweight analytics or data processing, and store post-processed or transformed data on Snowcone. When the ship is back at port or when there is reliable internet connectivity, connect Snowcone to the network, and send data to AWS. As soon as the data has landed in AWS, you’re now ready to capture the next set of data on your next voyage.
- Retail: Typically, retail environments have poor or inconsistent network connectivity. Snowcone is well suited for storing point of sale data, images, and videos from security cameras, in addition to processing the data right at the edge location.
A key point that I noted from the session is that there are two paths to getting data from Snowcone to AWS:
- Offline method – Send the Snowcone device back to AWS to get your data into AWS if you don’t have a good network connection. Keep in mind, this means you have to keep ordering Snowcones if you have a recurring data transfer or edge computing application generating data that must go to AWS.
- Online method – For scenarios where new data is generated regularly, copy your data onto the Snowcone, then connect Snowcone to the network, then transfer the data online to AWS using DataSync. This approach enables you to use Snowcone for the long term, and on an ongoing basis. This is ideal for everything from machines on a factory floor, sensors in the field, telemetry data in autonomous vehicles, to moving robots, drone videos, and camera footage.
Here’s how the ongoing data transfer workflow looks. First, you use Snowcone for capturing and processing data at the edge, then use DataSync to transfer data to AWS. This enables you to re-deploy Snowcone to continue its ongoing function at the edge:

Snowcone comes with a DataSync agent pre-installed as an AMI. To initiate online data transfers, connect Snowcone to your network, then enable the DataSync agent on the device, and activate the DataSync service in AWS.
Final thoughts
The optimize your data migration with AWS Snowcone and AWS Snowball Edge re:Invent session highlighted using AWS Snow Family devices for data migration – small to petabyte-scale migrations – and for edge computing. It was interesting to note the different ways the Snow devices could be used in rugged, austere environments, vibration prone environments like autonomous vehicles, and even on ships out at sea. You can leverage these devices for IoT applications for capturing, processing, and storing data in real time at the edge. Check out the building an IoT solution at the edge with AWS Snowcone blog for ideas on building your IoT workflows using AWS Snowcone.
I hope you enjoyed Ramesh’s session along with the takeaways from the session that I featured in this blog. If you have any comments or questions about this re:Invent session or this blog post, please don’t hesitate to reply in the comments section. Thanks for reading!