AWS Storage Blog
Improve application resiliency with Amazon EBS volume metrics and AWS Fault Injection Simulator
When business build applications, it is crucial to monitor those applications and take measures if and when needed to avoid downtime, and potentially, revenue loss. Choosing the correct metrics to monitor and setting up alarms as needed is table stakes for customers to achieve their application resiliency and availability goals.
Amazon Elastic Block Store (Amazon EBS) is a persistent block storage that provides up to 99.999% durability while providing high performance for mission-critical applications, such as SAP, Oracle, and Microsoft products. However, in any system of reasonable complexity, it is expected that failures will occur. Your workload needs to be aware of failures as they occur and take action to avoid impact on availability. Workloads must be able to both withstand failures and automatically repair issues. With AWS, you can take advantage of automation to react to monitoring data.
In this post, we share a solution that involves using a custom Amazon CloudWatch metric that can quickly notify customers of any I/O interruptions, allowing you to take timely actions as needed. By leveraging CloudWatch metrics and events, you can closely monitor the application health and set up alarms to initiate an automated action to remedy the problem. To simulate a storage fault, we utilize the Pause I/O action in AWS Fault Injection Simulator (AWS FIS). This will allow you to reproduce the real-world signals that happen when a volume is not responding to I/O operations and get notified using the custom CloudWatch alarm created. This lets customers test and build confidence that their entire application stack responds as intended to an unresponsive EBS volume.
Solution overview
When you create an EBS volume, it is automatically replicated within its Availability Zone to prevent data loss due to failure of any single hardware component. However, there is the potential for failures to impact your workload. Therefore, you need to continuously monitor the health of your workload so that you and your automated systems are aware of degradation or failure as soon as they occur.
To detect storage faults in your workload, we propose a solution that uses custom CloudWatch metric math and alarms to notify you when an EBS volume is not responding to I/O operations. You can then observe how these metrics and alarms respond to storage faults, and tune recovery processes in your environment by using the Pause I/O action in AWS Fault Injection Simulator (AWS FIS).
Prerequisites
You must set up an AWS account with sufficient permissions to access CloudWatch and create alarms. Additionally, when using AWS FIS, it automatically configures an AWS Identity and Access Management (IAM) role for the experiment. Please note that AWS FIS carries out real actions on real AWS resources in your system. Therefore, before you use AWS FIS to run experiments in production, we strongly recommend that you complete a planning phase and run the experiments in a pre-production environment.
Walkthrough
To be notified when an EBS volume is unresponsive, you must implement the following steps:
- Log in to the AWS Management Console and navigate to CloudWatch.
- Create a new CloudWatch alarm.
- Create a custom CloudWatch metric for the alarm.
- Configure actions to trigger Amazon Simple Notification Service (Amazon SNS)
- Conduct a simulation of a “disrupted” volume state using Pause I/O action in AWS FIS: Navigate to the Amazon EC2 console and select the non-production Amazon EBS volume for which you want to pause I/O and start the experiment. Make sure that this simulation is performed on a non-production Amazon EBS volume.
- Start the AWS FIS experiment: Generate load on your Amazon EBS volume and start the AWS FIS experiment created in Step 5 to simulate the disrupted volume state.
- View the newly created alarm from the CloudWatch alarm console page: As soon as the Amazon EBS volume stops processing I/O, a CloudWatch alarm generates an Amazon SNS notification alerting the said volume which might be in an impaired state.
Step 1: Log in to the AWS Management Console and navigate to CloudWatch service
- Log in to the Console and select the appropriate region.
- Navigate to CloudWatch here.
- To change the AWS Region, use the Region selector in the upper-right corner of the page.
Step 2: Create a new CloudWatch alarm
- In the navigation pane, select All alarms.
- Select Create alarm.
Step 3: Create a custom CloudWatch metric for the alarm
- Click on Select Metric to specify the metric and condition.

- In the search bar, type in your Amazon EBS volume ID on which you would like to set up the alarm. Then select Per-Volume Metrics.

Select the VolumeReadOps, VolumeWriteOps, and VolumeQueueLength metrics, and then select Graphed metrics from the panel.
- Click on the Add math dropdown menu and then select Start with empty expression.

- Under the Details column, select Edit math expression and type “IF(m3>0 AND m1+m2==0, 1, 0)”, where m1 is VolumeReadOps, m2 is VolumeWriteOps, and m3 is VolumeQueueLength.

- Select only custom expression and click on Select metric in the bottom right-hand corner.

- Under Graph, select the Period dropdown and select 1 minute. This means that you’re selecting 1 minute as the granularity of the data points on which the alarm is monitored.

- Next, we need to define the threshold to trigger the alarm. Under Conditions, select the threshold type as Static, the alarm condition as Greater/Equal, and the threshold value based on how frequently you want the alarm to be triggered. For example, if you would like to be alerted when your volume has been impaired for 2 continuous minutes, your threshold should be set as “2”. Select Next.

Step 4: Configuring actions to trigger Amazon SNS notifications
- Under Configure Actions, select In alarm, Create new topic, and optionally add any email address to which you would like to send notification. Once done, scroll down and select Next.

- Provide an alarm name and select Next.
- Preview all the options and select Create Alarm.
Step 5: Conduct a simulation of the “disrupted” volume state using the Pause I/O action in AWS FIS
- Open the Amazon EC2 Console.
- In the navigation pane, choose Volumes.
- Select the volume for which to pause I/O, and choose Actions > Fault injection > Pause volume I/O.

- For Duration, enter the duration for which to pause the I/O between the volume and the instances. The field next to the Duration dropdown list shows the duration in ISO 8601 format.
- In the Service access section, select the IAM service role for AWS FIS to assume to perform the experiment. You can use either the default role, or an existing role that you created. For more information, see Create an IAM role for AWS FIS experiments.

- Choose Pause volume I/O. When prompted, enter start in the confirmation field and choose Start experiment.
- Monitor the progress and impact of your experiment. For more information, see Monitoring AWS FIS in the AWS FIS User Guide.
Step 6: Start the AWS FIS experiment
- Log in to your EC2 instance to which the volume is attached.
- Install and run the Flexible I/O (FIO) tester utility to generate load on your Amazon EBS volume. Make sure that FIO is running for sufficient time to trigger the alarm using the Pause I/O FIS experiment created in Step 5.
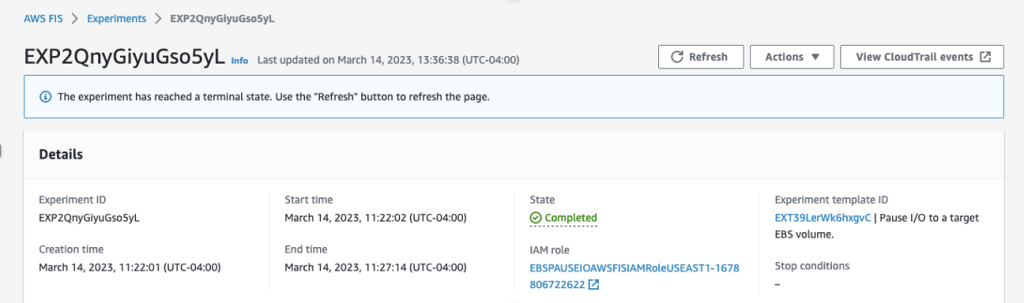
- Once the experiment is completed, you can see a similar screen as follows:
Step 7: View newly created alarm
- Navigate to the CloudWatch console and select All alarms under Alarms in the left-hand navigation panel.

- Select the newly created alarm. You should be able to see an alarm in the “In alarm” state which was triggered by the AWS FIS experiment in Step 6.

Remediated actions to take when you notice the alarm
Once the alarm is triggered and an Amazon SNS notification comes in, you can take action based on your recovery workflows. Based on assessment of your potential disruptions on your systems, you can take a variety of actions, such as creating a volume from a recent snapshot of the volume or you can divert requests/traffic away from the impaired volume at the application layer.
If you are using an auto-scaling group of EC2 instances, you can use the CloudWatch alarm to trigger termination of the unhealthy instance and launch a new one to replace it. Auto scaling works well for gradual changes when you have minutes to recover that capacity.
Cleaning up
If you no longer need this solution, then delete the CloudWatch alarm. In addition, review the newly created or existing Amazon SNS subscription and topic for deletion to avoid incurring charges for resources created when following this post.
Conclusion
In this post, we presented a solution for monitoring Amazon EBS volume disruptions via Amazon CloudWatch, and setting up alarms that can be sent via Amazon SNS. With the help of this solution, you will rarely miss an alarm related to volume impairment because now you can receive notifications at all your designated endpoints. This is extremely important because now you can receive the alarms and then react to those alarms by taking necessary actions on the application side. The ability to monitor the alarm and react to it lets you achieve the desired resiliency of your mission critical applications.
Thank you for reading this post. If you have any comments or questions, then don’t hesitate to leave them in the comments section.