December, 2022: Amazon Relational Database Service (Amazon RDS) now supports Amazon RDS Blue/Green Deployments to help you with safer, simpler, and faster updates to your Amazon Aurora and Amazon RDS databases. Blue/Green Deployments create a fully managed staging environment that allows you to deploy and test production changes, keeping your current production database safe. Learn more about Blue/Green Deployments on the Amazon RDS documentation.
Blue/green deployment techniques provide near zero-downtime release and rollback capabilities. This requires two identical environments that are running different versions of your application. This also extends to the underlying data layer, where you need two identical Amazon Aurora MySQL-Compatible Edition database clusters running in sync with the same dataset for seamless testing. After completing tests on the green environment, traffic is switched from the blue to the green environment.
The same technique can also be used for continuous integration and continuous delivery (CI/CD) pipelines when code changes and new features must be verified against existing online data. With CI/CD pipelines, you need multiple DB clusters for development, testing, quality assurance, and acceptance environments. You often also want to test code changes and new features against live data as it comes in. Changes to the underlying data model result in schema changes in the database. Schema changes must be thoroughly tested to mitigate the risk of application downtime. It is a best practice to avoid testing data definition language (DDL) operations, creation of databases indexes, schema migrations, or analytics work on your production cluster.
In this post, I walk you through the automation solution for blue/green deployments involving Amazon Aurora MySQL. The solution uses Aurora fast cloning, AWS Lambda functions, Amazon CloudWatch Events, and AWS Step Functions.
Aurora fast cloning
Aurora makes it easy to set up, operate, and scale a relational database in the cloud. An Aurora MySQL DB cluster consists of one or more DB instances and a cluster volume that manages the data for those DB instances. It also offers Aurora fast cloning, a feature to quickly and cost-effectively create a new cluster containing a duplicate of an Aurora cluster volume and all its data. Creating a clone is faster and more space-efficient than physically copying the data using a different technique, such as restoring a snapshot.
Aurora fast cloning is ideal for orchestrating blue/green deployments to minimize downtime for maintenance operations. In this scenario, the blue environment represents the production database serving production traffic. The green environment is created as a clone from the production cluster and synched with it. For Aurora MySQL, this is possible using a combination of Aurora fast cloning and binary log replication between blue and green clusters. To accomplish this, you first clone your production cluster (blue cluster); the clone (green cluster) is an exact copy of the blue cluster. Then you set up MySQL binlog replication between both clusters. This replicates all writes from the blue to the green cluster. You can use the clone (green cluster) to test DDL and DCL changes, database upgrades, or run workload-intensive operations, such as exporting data or running analytical queries with no impact to your production cluster.
You can incorporate this same methodology described into your CI/CD workflow to clone your production database cluster and sync the clone with your primary cluster using MySQL binlog replication.
With the green cluster synchronized, you can test the impact of your schema changes, new table design, additional table columns, databases indexes, and more in a matter of minutes with live data and without impacting your production database. To switch over production traffic, you set the blue cluster to read only, ensure that all writes have copied to the green cluster, and then proceed with production traffic.
Solution overview
The following solution offers complete automation for the Aurora blue/green deployment process (see the following architecture diagram).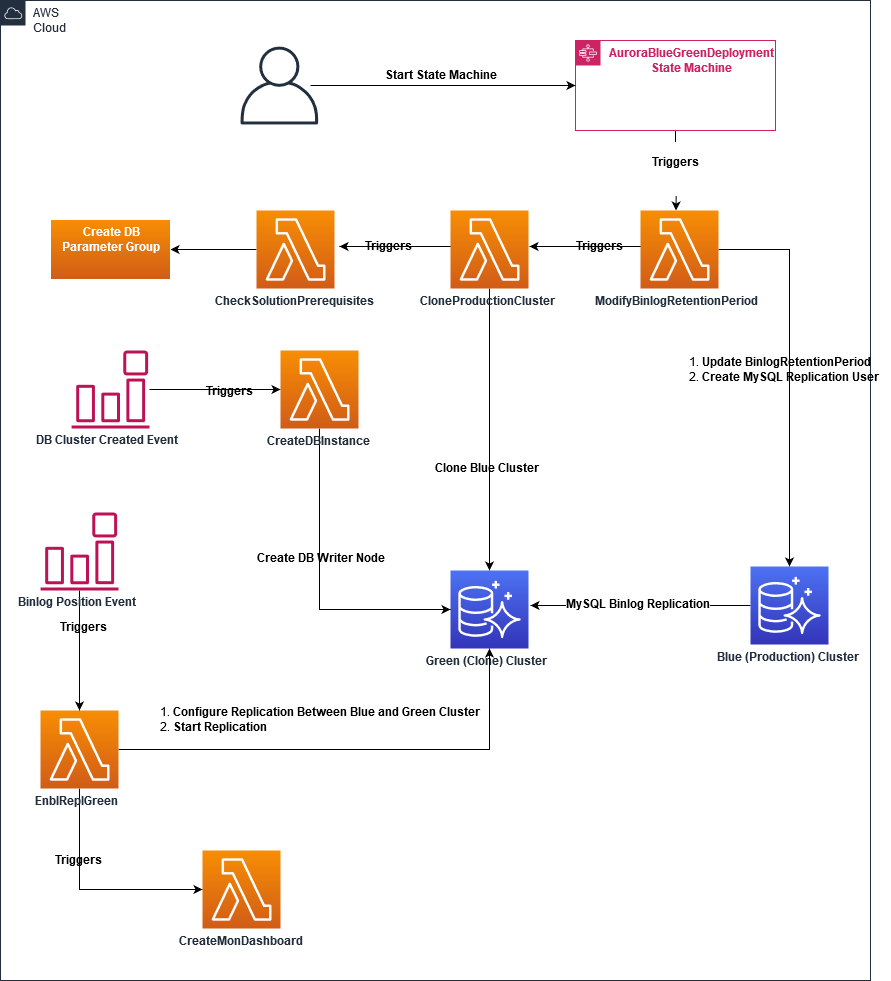
Prerequisites
To test the solution, you must have a source Aurora MySQL cluster already up and running (see Creating an Amazon Aurora DB cluster). This is typically your production cluster. For the rest of this post, we refer to the production cluster as the blue cluster and the clone as the green cluster. Before you start the solution, you must check if MySQL binary logging is enabled on the blue cluster environment and enable it if it’s currently disabled.
Check binary logging status
To check if MySQL binary logging is enabled, you can run either select @@global.log_bin or show master status against your blue cluster writer DB instance as follows:
mysql> select @@global.log_bin;
+------------------+
| @@global.log_bin |
+------------------+
| 1 |
+------------------+
If the output of select @@global.log_bin is 1, binary logging is enabled. If output is 0, binary logging is disabled.
If the output of show master status shows the binlog position similar to the following output, binary logging is enabled.
mysql> show master status;
+----------------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------------+----------+--------------+------------------+-------------------+
| mysql-bin-changelog.000010 | 32078471 | | | |
+----------------------------+----------+--------------+------------------+-------------------+
If empty output is received, then binary logging is disabled.
Enable binary logging
To enable binary logging, complete the following steps:
- On the Amazon Relational Database Service (Amazon RDS) console, choose Databases in the navigation pane.
- Choose the blue DB cluster.
- On the cluster details page, on the Configuration tab, locate the DB cluster parameter group.
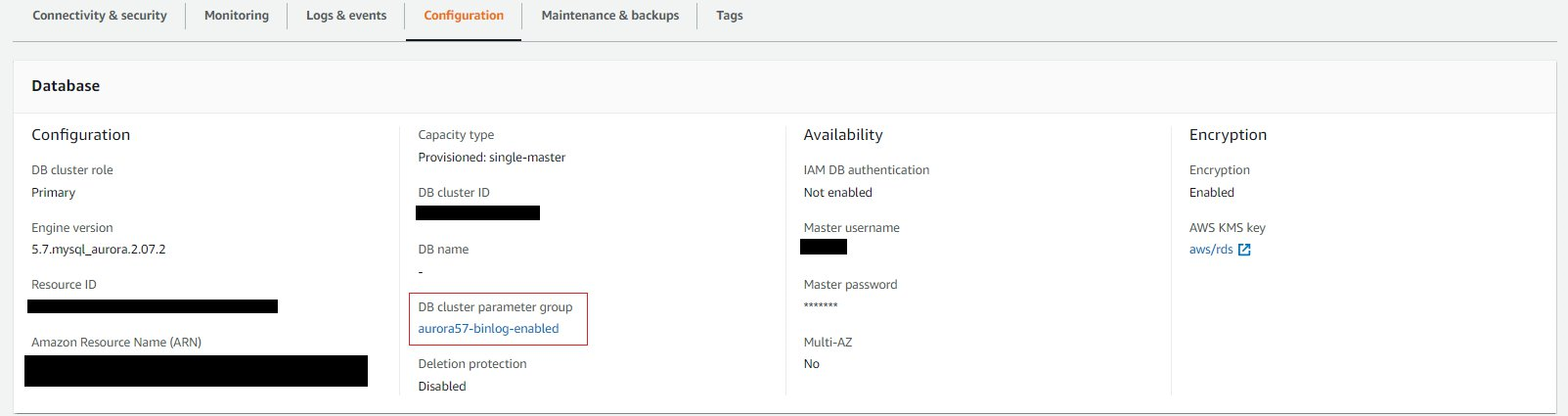
- If you’re using the default Aurora DB cluster parameter group, create a new DB cluster parameter group. For Type, choose DB Cluster Parameter Group.
- In the navigation pane, choose Parameter groups.
- Select the DB custom cluster parameter group, choose Parameter group actions, and choose Edit.
- Modify the
binlog_format parameter to ROW.
- Choose Save.
If you created a new DB cluster parameter group, attach the parameter group to your DB cluster:
- On the Amazon RDS console, in the navigation pane, under Clusters, choose Modify.
- Update the DB cluster parameter group to the new DB cluster parameter group, and then choose Apply immediately.
- Choose Continue, and choose Modify cluster.
After you perform these steps, you must reboot the writer instance in the Aurora DB cluster for your changes to apply. When you reboot the writer instance, all the readers in the DB cluster are also rebooted. This doesn’t apply to Aurora MySQL version 2.10 and higher. In Aurora MySQL version 2.10 and higher, you can reboot the writer instance of your Aurora MySQL cluster without rebooting the reader instances in the cluster. For more information, see Rebooting an Aurora MySQL cluster (version 2.10 and higher).
By deploying this solution, you incur costs for Lambda, AWS Systems Manager Parameter Store, AWS Secrets Manager, and Aurora MySQL.
Deploy the solution
You deploy the solution using the following AWS CloudFormation template:

The template takes several parameters as input, including the Aurora production cluster (blue cluster) identifier, the VPC ID and subnet details where the blue cluster is currently running, and the security groups to assign to the clone cluster and the solution Lambda functions.
Before starting the solution automation, you must make sure that the security groups assigned to the green cluster allow the replication process to work and data to flow between the blue and green clusters on the MySQL configured port.
The following is a list of the input parameters of the CloudFormation template:
- BinaryLogRetentionPeriod – This parameter sets the binlog retention hours used to specify the number of hours to retain binary log files on the blue cluster. Amazon RDS normally purges a binary log as soon as possible, but the binary log might still be required for replication with the clone depending on how far behind the clone is and the frequency of updates to your blue cluster. Adjust the retention period according to your use case.
- DBClusterParameterGroupName – The name of the DB cluster parameter group to assign to the clone cluster. A DB cluster parameter group acts as a container for engine configuration values that are applied to every DB instance in an Aurora DB cluster. You should create a new DB cluster parameter group and provide its name in the template. The solution assigns it to the green cluster. If no valid DB cluster parameter group name is provided, the clone cluster uses the default DB cluster parameter group for the Aurora MySQL engine version used. The default parameter group for Aurora MySQL 2.x is
default.aurora-mysql5.7; the default parameter group for Aurora MySQL 1.x is default.aurora5.6.
- DBClusterVPC – The VPC where the blue cluster is running. The clone cluster is created in the same VPC as the blue source cluster. The VPC is also required to configure Lambda functions that connect to the blue and green clusters to set up the MySQL binlog replication. Make sure to verify application connectivity before you switch over production traffic.
- DBParameterGroupName – The name of the DB parameter group to assign to the writer instance of the clone cluster. A DB parameter group acts as a container for engine configuration values that are applied to one or more DB instances. We recommend that you create a new DB parameter group before running the solution and provide its name in the CloudFormation template. Otherwise, the solution creates a new DB parameter group, sets it to read only, and assigns it to the clone cluster. If you provide the name of a valid DB parameter group, the solution verifies if this DB parameter group isn’t associated with the blue cluster writer instance. Then it modifies the DB parameter group to read only and assigns it to the clone. If the input DB parameter group is associated with the blue cluster writer node, or no valid DB parameter group is provided, the solution creates a new DB parameter group, modifies it to read only, and assigns it to the clone cluster writer instance.
- VPCSecurityGroups – The list of security groups to assign to the green cluster and the VPC Lambda functions connecting to both the green and blue clusters. Make sure port 3306 is open for binary log replication between blue and green clusters to work. Additionally, make sure the chosen security groups allow database access to the existing blue cluster security groups. This is required for the Lambda functions to connect to the blue and green clusters to create the replication user, update the binary log retention period, and set up binary log replication. If the green cluster can’t connect to the blue cluster, the solution fails and the Lambda functions don’t function correctly.
- VPCSubnetIDs – The VPC subnet IDs to attach to the Lambda functions deployed by the solution to connect to both blue and green clusters. These subnets should be the same as your DB subnet groups and where the blue cluster is currently running. The green cluster and all the required Lambda functions are created in the same subnets.
- WriterNodeIdent – The DB instance identifier to assign to the green cluster writer instance. The identifier must be unique across all DB instances in your account and must follow the following naming constraints:
- Must contain 1–63 letters, numbers, or hyphens
- First character must be a letter
- Can’t end with a hyphen or contain two consecutive hyphens
- MySQLMasterUser and MySQLMasterPassword – The MySQL master user on the production database. The user details (username and password) are stored in AWS Secrets Manager for additional protection. You must provide the MySQL master user details for the solution to work. To start the replication, the master user must run the
mysql.rds_start_replication procedure. The automation uses the master user to connect to both the blue and green clusters, and set up and start the replication process.
- MySQLReplicationUser and MySQLReplicationPassword – As a security best practice, the solution creates a MySQL user with limited privileges to be used solely for replication. This user only has
REPLICATION SLAVE privileges. The username must be between 4–16 letters, numbers or underscores, and the first character must be a letter.
These inputs are stored as parameters in the AWS Systems Manager Parameter Store and used by a series of Lambda functions to perform the following tasks:
- Connect to the blue cluster using
MySQLMasterUser and MySQLMasterPassword.
- Modify the binlog retention period on the blue cluster to the value you specified in
BinaryLogRetentionPeriod.
- Create a replication user on the blue cluster used solely for replication as a security best practice. The corresponding values for
MySQLReplicationUser and MySQLReplicationPassword are used to create this replication user.
- Create a clone cluster with a single DB writer instance with the name specified in the
WriterNodeIdent parameter. This is the green cluster.
- Enable
read_only mode on the green cluster to avoid possible data inconsistency and a split-brain.
- Connect to the green cluster using the
MySQLMasterUser and MySQLMasterPassword.
- Set up and enable MySQL binlog replication between the blue and green clusters. The replication user created in Step 3 is used exclusively to start the replication using the rds_start_replication procedure.
- Create a CloudWatch dashboard to monitor the replication lag between both clusters.
Start the solution
The CloudFormation template provisions all the necessary Lambda functions to perform the steps we described. However, it doesn’t start the automation. It also creates a Step Functions state machine called AuroraBlueGreenDeployment. This state machine is responsible for starting the entire automation.
To start the solution, you need to invoke the AuroraBlueGreenDeployment state machine. You can do this on the Step Functions console or the AWS Command Line Interface (AWS CLI).
To use the console, complete the following steps:
- On the Step Functions console, in the navigation pane, choose State machines.
You can review all the Step Functions state machines you have available.
- Choose the
AuroraBlueGreenDeployment state machine.
- On the state machine details page, choose Start Execution to run the state machine.
The state machine requires no input, and you can leave the default JSON optional input as is.
The State Machine runs and exits as soon as the green cluster creation starts. It doesn’t wait for the green cluster to be available and replication started.
Alternatively, you can use the start-execution AWS CLI command to run this state machine and start the automation.
The solution also creates a CloudWatch dashboard with the following name pattern: Aurora-Binlog-Replication-Lag-regionName-Writer_Node_Name, for example Aurora-Binlog-Replication-Lag-us-east-1-testprod1. Use this dashboard to monitor the replication lag between the blue and green clusters. The dashboard displays the value of the AuroraBinlogReplicaLag CloudWatch metric, which displays the value of the Seconds_Behind_Master field of the MySQL SHOW SLAVE STATUS command on the writer node of the green cluster.
When the green cluster has caught up with the blue cluster, you’re ready to switch over from the blue to the green cluster. After switchover, you can start testing against the green cluster.
Switch over to the green cluster
After you have tested your code, schema changes, and verified application connectivity to the green cluster, you must complete the following tasks before switching over:
- Verify you have run through all your critical DB operations and thoroughly tested the code and schema changes.
- Add Aurora reader nodes to the green cluster. The solution provisions the green cluster with a single writer DB instance for testing purposes. For production traffic, however, it’s a best practice to add Aurora reader nodes across Availability Zones for high availability.
- Make sure the replication on the green cluster has caught up with the blue cluster. Run the
show slave status\G command on the green cluster to verify it has applied all the relay logs from the blue cluster. You also can use the CloudWatch dashboard created by the solution to monitor the Seconds Behind Master metric, which tells you how far the replica target is behind the source. CloudWatch offers 1-minute granularity, so for real-time details on the replication progress, make sure to check the show slave status\G command before switchover.
Now you’re ready to stop the application and start with the scheduled downtime to switch over.
- Stop all the application processes and make sure all the write activities are stopped on the blue cluster and there are no application database connections. If you can’t stop application writes, you can work around it by blocking application access to the database (for example, through security groups, if only the blue environment cluster uses it).
- To avoid any write operations, turn the
read_only database mode to ON for the blue environment by changing the database parameter read_only value from 0 to 1 on the writer database instance.
- Stop the binary log replication on the green cluster. Connect to the green cluster and call the mysql_rds_stop_replication procedure. The
mysql.rds_stop_replication procedure is only available for MySQL versions 5.6 and later, and 5.7 and later.
- Reset the replication on the green cluster. Connect to the green cluster and call the mysql_rds_reset_external_master procedure. The
mysql.rds_reset_external_master sets the green cluster to no longer be a read replica of the blue cluster.
- Now that the green cluster is no longer a replica of the blue cluster, disable the
read_only database mode on the green cluster allowing it to accept write traffic directly from the application. To do this, modify the custom DB parameter group that it’s assigned to the green cluster writer instance by setting the variable name read_only to 0 instead of 1.
- Update the application connection string to use the green cluster endpoint.
Clean up
You can clean up the AWS resources created (Lambda functions, CloudWatch events, and Step Function state machine) by deleting the CloudFormation stack.
You can do this from the AWS CloudFormation console or the AWS CLI. To use the console, complete the following steps:
- On the Stacks page on the AWS CloudFormation console, choose the stack that you want to delete. The stack must be currently running.
- In the stack details pane, choose Delete.
- Choose Delete stack when prompted.
Alternatively, you can delete the stack using the AWS CLI delete-stack command:
aws cloudformation delete-stack --stack-name my-stack
Deleting the CloudFormation stack doesn’t delete the clone cluster created. The replication user you created is also not deleted on the blue and green clusters. You can drop the replication user from both clusters using the following command:
DROP USER Replication_User_Name;
Summary
This post explained how to configure and start Aurora MySQL blue/green automation and switch over to the green cluster. The solution clones the blue cluster and designates the clone as the green cluster. It then sets up MySQL binary log replication between both clusters. This practice is particularly useful to test new application versions with changes to the underlying data store, including significant schema changes with minimal impact on the production cluster. It’s a best practice not to test schema changes against live production databases and instead use the blue green deployment technique to test changes with incoming live data.
When testing is complete and you’re ready to switch over, make sure writes are stopped on the blue cluster and that the green cluster has caught up (read all updates) with the blue cluster. Only then can you update the application connection string to point to the green cluster. We recommend taking a manual snapshot of your blue cluster before starting this automation. For more information on taking manual snapshots, see Creating a DB cluster snapshot.
This post builds up on the post Performing major version upgrades for Amazon Aurora MySQL with minimum downtime.
About the Author
 Ahmed Gamaleldin is a Senior Technical Account Manager (TAM) at Amazon Web Services. Ahmed helps customers run optimized workloads on AWS and make the best out of their cloud journey.
Ahmed Gamaleldin is a Senior Technical Account Manager (TAM) at Amazon Web Services. Ahmed helps customers run optimized workloads on AWS and make the best out of their cloud journey.