Amazon Web Services ブログ
Category: Artificial Intelligence

Kiro で OpenAPI/Swagger 仕様から数秒でテストスイートを生成する
API 仕様とテストの乖離は開発現場の慢性的な課題です。本記事では、エージェント駆動の開発システム Kiro を使い、Swagger/OpenAPI 仕様から axios ベースの HTTP テスト、Express のモックサーバー、モックと実 API を切り替える設定、HTML レポートまでを含む Node.js テストスイートを数秒で自動生成する方法を解説します。Petstore API を例にステアリングファイルの活用、生成されたテスト品質、削除ライフサイクル検証、認証付き内部 API への適応、ヘッドレスモードによる CI/CD 自動再生成まで紹介します。

実践企業に学ぶ生成 AI 導入の勘所 〜眠るデータを企業価値に変える〜 – AWS Local Executive Roadshow 博多編(#6/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]

週刊生成AI with AWS – 2026/6/22 週
6 月 22 日週の生成 AI with AWS 界隈のニュースをまとめてお届けします。Amazon Bedrock AgentCore の Web Search 一般提供やマネージドナレッジベース、AWS DevOps/セキュリティエージェントの新機能など、AI エージェントを本番で活用するためのアップデートが充実しました。ユナイテッドアローズの店舗 AI エージェント「SMART」の国内事例や、Kiro の新機能・GovCloud 認証取得まで、今週の注目トピックをぜひご覧ください。

Amazon Quick on Desktop が東京リージョンに対応 – AWS Summit New York 2026 アップデート –
Amazon Quick on Desktop が AWS アジアパシフィック (東京) リージョンで利用可能になりました。本ブログでは、Amazon Quick on Desktop の機能やアップデートについて紹介します。

CX向上に向けたコンタクトセンター変革 — 全国複数拠点・数千席規模の環境で挑む 東京電力エナジーパートナーの Amazon Connect Customer × 生成 AI 活用
本ブログは東京電力エナジーパートナー株式会社 サービスソリューション事業部 今野拓也様の監修のもと、アマゾン […]
AWS Summit Japan 2026 : Physical AI – Spatial Computing 関連展示の紹介
こんにちは。AWS プロフェッショナルサービスの Spatial Computing (空間コンピューティング […]
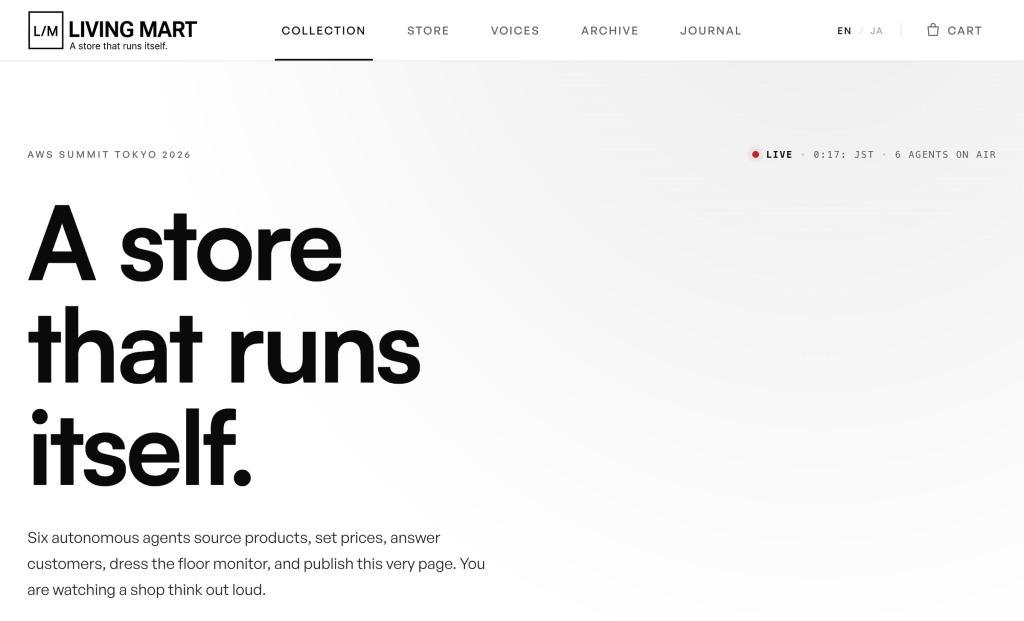
AI が経営するお店で買い物しませんか? — AWS Summit Japan 2026 Builders’ Fair で「Living Mart」体験
6 体の AI エージェントが、仕入れ・値付け・サイト運営・接客・広告までを人間の指示なしに動かすお店。AWS Summit Japan 2026(幕張メッセ/ブース A080)で、AI 運営の EC サイトでのお買い物と、当選者向け AI デザインのオリジナルステッカーを体験できます。
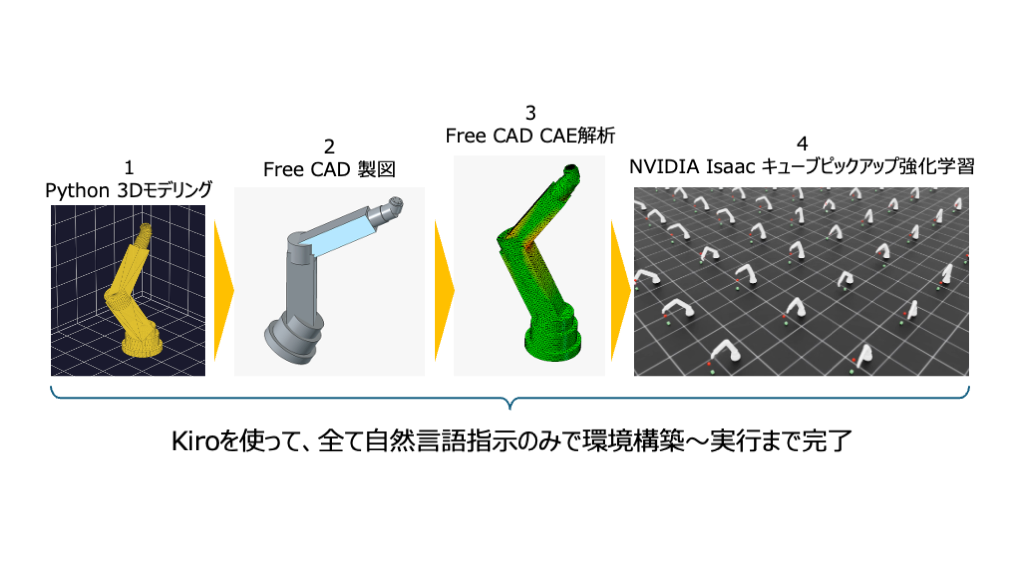
AWS Summit Japan 2026 ブース紹介 — 生成 AI 時代の製品設計開発
みなさんこんにちは。ソリューションアーキテクトの山田です。2026 年 6 月 25 日(木)、26 日(金) […]
AWS Summit Japan 2026 ブース紹介 ソフトウェア定義型ファクトリー
こんにちは、ソリューションアーキテクトのシャルノ ミカエルです。 本記事では、2026 年 6 月 25 日( […]

もぐもぐ AWS – 現場の SA が語るお昼 30 分の技術トーク
昼休み30分でAWSの最新AI技術をキャッチアップ。現場のソリューションアーキテクトが配信。AIエージェント、Bedrock、セキュリティまで。参加無料。