Amazon Web Services ブログ
Category: Artificial Intelligence

AWS 週間まとめ:NY Summit の振り返り、ハノイでのローカルゾーン、Bedrock での Grok 4.3、価格引き下げなど(2026年6月22日)
2026 年 6 月 15 日週、AWS Summit New York City では、何千人ものお客様、パ […]
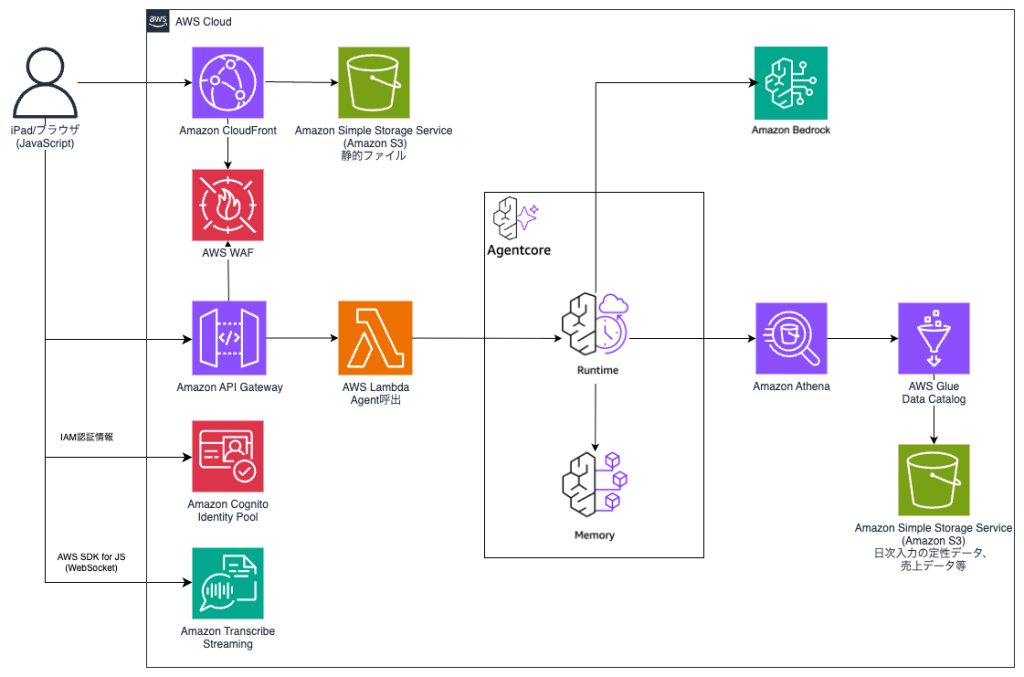
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。

より高速かつ正確なエンタープライズ AI アプリケーションを実現する Amazon Bedrock マネージドナレッジベースのご紹介
2026 年 6 月 17 日、Amazon Bedrock マネージドナレッジベースを発表しました。これは、 […]

Amazon Bedrock AgentCore での Web Search を発表: AI エージェントを最新かつ正確なウェブ知識に基づかせる
2026 年 6 月 17 日、Amazon Bedrock AgentCore での Web Search […]

Kiro Web の Automations 機能のご紹介
Kiro Web に、繰り返し発生するタスクを自動化するクラウドで動作する Automations 機能を追加しました。スケジュールを設定すると、Kiro が自律エージェントとしてサンドボックス上でタスクを実行し、変更を含むプルリクエストを自動的に開きます。ドキュメント更新、テスト生成、TODO 整理など、定期的な作業をまかせられます。
AWS Transform – 継続的モダナイズ (プレビュー) で、技術的負債を自律的にプロアクティブに削減
2026 年 6 月 17 日、AWS Transform の新機能である AWS Transform – 継 […]

Accelerating Smart Product SDLC with AI Agent Workshop のご紹介
IoT やコネクテッドデバイスの普及により、製造業の製品はハードウェア単体からソフトウェアで価値を提供する「ス […]

コーディングは不要 ― ビジネスユーザーこそが顧客体験の新たな設計者に
Agentic AI により、顧客体験の設計はエンジニアだけの仕事ではなくなります。Amazon Connect Customer の新機能「Agentic CX Designer」と「Live Sync」により、ビジネスユーザーが自ら体験を設計・テスト・リリースできる時代が到来しました。

BIM データの要件定義から IDS を自動生成する: 生成 AI と AgentCore で実現するパラレル IDS ビルダー
建設業界で進む BIM 活用では、「必要なデータが揃っているか」を定義・検証することの難しさが課題になっています。本ブログでは、この要件を機械が検証できる形で定義する国際標準の IDS を、自然言語で書かれた要件定義から生成 AI が自動生成するソリューションを解説します。Amazon Bedrock AgentCore と AWS Step Functions を組み合わせ、要件ごとに並列で IDS を生成する仕組みを、実装レベルで紹介します。

BIM データを生成 AI で活用する: IFC を RDF グラフに変換し Amazon Neptune で問い合わせるアーキテクチャ
建設業界で導入が進む BIM には、建物の豊富なデータが蓄積されています。本ブログでは、このデータを生成 AI から自然言語で問い合わせる方法として、BIM のオープンな標準フォーマットである IFC を RDF グラフに変換して Amazon Neptune に格納し、AI エージェントが text-to-SPARQL で回答する仕組みを、実装レベルで解説します。