Amazon Web Services ブログ
Category: Artificial Intelligence

週刊生成AI with AWS – 2026年6月29日週
週刊生成AI with AWS, お客様事例が充実した 2026 年 6 月 29 日号 – プリモグローバルホールディングス様、株式会社ラクス様、ITbook 株式会社様、株式会社オーレックホールディングス様の国内事例ブログを紹介。また、Kiro の Agent Focus や GitLab 連携、OpenAPI からのテストスイート生成などのブログ記事も。サービスアップデートでは Claude Sonnet 5 の AWS 提供開始や Amazon Bedrock AgentCore のリージョン拡大をはじめとするアップデートを紹介。

フロンティアモデルの安全なリリースに向けた AWS の取り組み
Amazon Bedrock で Anthropic の Claude Fable 5 モデルが、悪用防止のためのさらに強力なガードレールを備えて再びご利用いただけるようになりました。本記事では、サイバー能力を持つフロンティアモデルを防御側に届けながら攻撃者による悪用を防ぐバランスの取り方、Project Glasswing を通じた Anthropic との連携、問題の重大度と対応の SLA など、フロンティアモデルを安全にお客様へ提供するための AWS の取り組みを紹介します。

東海旅客鉄道株式会社:超電導リニアの電気設備保守を支える IoT プラットフォームの構築
このブログは、東海旅客鉄道株式会社(以下、JR 東海)中央新幹線推進本部 リニア開発部 藤原 海渡氏と、アマゾ […]

【開催報告 & 資料公開】公共分野における AI 活用最新アップデート (AWS 公共セミナー 2026 年)
こんにちは。アマゾン ウェブ サービス ジャパン合同会社 パートナー ソリューション アーキテクト の深井宣之 […]

株式会社ラクス: 伝票作成 AI エージェントの構築と、品質を支える評価設計の取り組み
本ブログは株式会社ラクス様と Amazon Web Services Japan 合同会社が共同で執筆しました […]

Kiro とともに医療情報システムのガイドライン遵守開発に挑む
医療情報システム開発で避けて通れない数多くの業界ガイドラインに対して、AI 駆動開発でどう立ち向かうか。本記事では、ガイドラインの知識を Agent Skills、開発標準を Agent Steering として Kiro に与え、必要なときに必要な分だけコンテキストを参照させながら、人間が意思決定権を持って協働する「Kiro をチームの一員に育て上げる」アプローチを紹介します。

Agent Focus の紹介
開発者が AI と協働する方法は変わりつつあります。モデルは今や複数ステップの作業を計画し実行できるようになり、より多くの開発者が、自分で一行ずつコードを打ったり直接編集したりするのではなく、エージェントを導くことに一日を費やすようになっています。
IDE は別の時代のために作られたものです。IDE はコードを中心に据えますが、それはまさに「自分で編集しているとき」に欲しいものです。しかし、主な仕事がエージェントに実行させる作業を定義し、洗練し、方向づけることであるとき、それが必ずしも欲しいものとは限りません。2026 年 6 月 25 日、私たちは Agent Focus を発表します。これは Kiro IDE における実験的な新しいビューで、エージェントとのやり取りを前面に押し出すものです。チャットファーストな働き方の基盤を築きます。やりたいことを記述し、会話を通じて洗練させ、作業を開始し、エージェントが進める様子を確認する——という流れです。これまでの IDE 体験がなくなるわけではありません。Agent Focus はそれと並んで存在し、いつでも両者を行き来できます。

1 つのタスク、2 つのプロバイダー(GitLab と GitHub) をまたぐ変更を 1 セッションで調整する
Kiro Web は、既存の GitHub サポートに加えて、GitLab でも動作するようになりました。より興味深いのは、コードが GitLab と GitHub の両方にまたがって存在する場合に何が起きるかです。両方からリポジトリを同じセッションに追加し、単一の変更を記述すれば、Kiro がそれを両方にわたって実行し、一方にはマージリクエスト(MR)を、もう一方にはプルリクエスト(PR)を開いてくれます。これは、コードが 1 つのきれいな場所に収まっていないときに意味を持ちます。

接客スキルの属人化に悩む企業へ ― プリモグローバルホールディングスがAmazon Bedrock で実現した AI ロールプレイ研修
本ブログは プリモグローバルホールディングス株式会社 様と アマゾン ウェブ サービス ジャパン合同会社が共同 […]
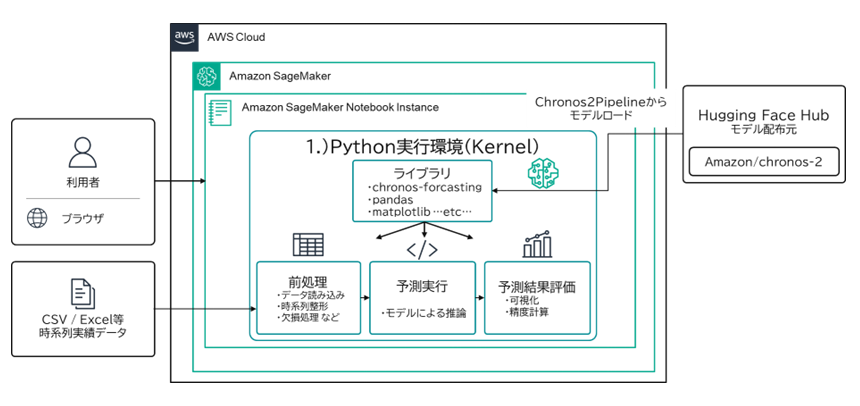
キヤノンIT ソリューションズ様と取り組むホテルのフードロス削減 – 時系列基盤モデル Chronos-2 で最適な提供量を予測する
本ブログでは、サステナビリティを組み込む取り組みの一例として、キヤノンITソリューションズ様と共同で取り組んだ Chronos-2 による需要予測を起点としたフードロス削減 PoC について、アーキテクチャと技術的なポイントをご紹介します。